mongodb mapreduce分析
目前发现mapreduce的用法有两种:
一:计数以及实现聚合函数统计数据
二:对数据进行分组简化或者构造自己想要的格式
三:根据条件进行数据筛选
现在普遍的用法是第一种,对于第二种用法我们会分析一些格式怎么构造。
环境:
虚拟机:Oracle VM virtualbox 4.0.6
Linux:CentOS 5.6
mongovue(推荐使用,一个可视化的mongodb客户端,下载地址:http://www.mongovue.com/)
效果图
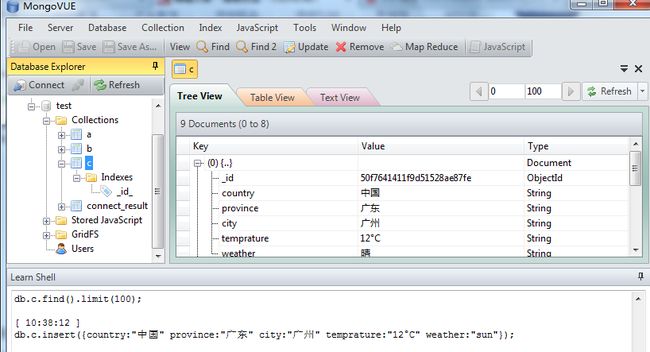
PS:如果主机和虚拟机中的linux可以相互ping通,mongovue却连接不成功,拒绝访问的话很可能是Linux中防火墙的设置问题。可以把防火墙暂时关了或者把mongodb的端口开启,方法如下:
1) 永久性生效,重启后不会复原
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后复原
开启: service iptables start
关闭: service iptables stop
需要说明的是对于Linux下的其它服务都可以用以上命令执行开启和关闭操作。
在开启了防火墙时,做如下设置,开启相关端口,
修改/etc/sysconfig/iptables 文件,添加以下内容:
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
mongovue破解方法:
在开始--运行中打入 regedit--回车
注册表中查找B1159E65-821C3-21C5-CE21-34A484D54444中的子项4FF78130 ,删除其下的三个子项即可。
这样剩余时间又会回到15天前
mapreduce原理:
参考资料:http://www.csdn.net/article/2013-01-07/2813477-confused-about-mapreduce(十张图带你了解mapreduce)
http://www.mongovue.com/2010/11/03/yet-another-mongodb-map-reduce-tutorial/ (原理)
http://www.infoq.com/cn/articles/implementing-aggregation-functions-in-mongodb(聚合函数)
1.db.runCommand(
2.{
3. mapreduce : <collection>,
4. map : <mapfunction>,
5. reduce : <reducefunction>
6. [, query : <query filter object>]
7. [, sort : <sort the query. useful optimization>] for
8. [, limit : <number of objects to from collection>] return
9. [, out : <output-collection name>]
10. [, keeptemp: < | >] true false
11. [, finalize : <finalizefunction>]
12. [, scope : <object where fields go into javascript global scope >]
13. [, verbose : ] true
14.});
参数说明:
- mapreduce: 要操作的目标集合。
- map: 映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce: 统计函数。
- query: 目标记录过滤。
- sort: 目标记录排序。
- limit: 限制目标记录数量。
- out: 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- keeptemp: 是否保留临时集合。
- finalize: 最终处理函数 (对 reduce 返回结果进行最终整理后存入结果集合)。
- scope: 向 map、reduce、finalize 导入外部变量。
- verbose: 显示详细的时间统计信息
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。
我们可以把mapreduce与sql对比理解:

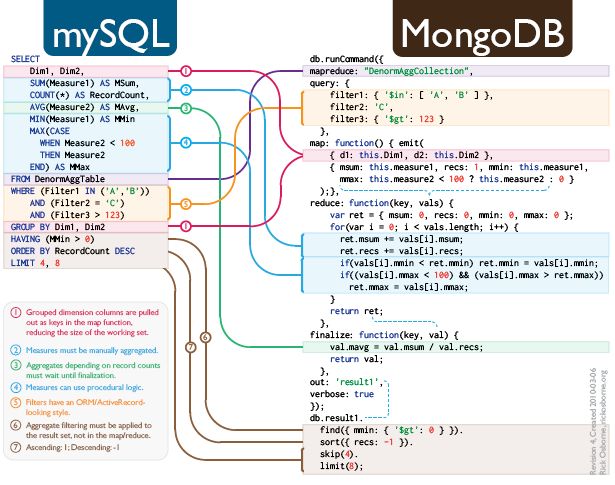
emit函数是非常重要的,他的作用是将一条数据放入数据分组集合,这个分组是以emit的第一个参数为key的。你可以这样理解,当你在所有需要计算的行执行完了map函数,你就得到了一组key-values对。基本key是emit中的key,values是每次emit函数的第二个参数组成的集合。
现在我们的任务就是将这一个key-values变在key-value,也就是把这一个集合变成一个单一的值。这个操作就是Reduce。
例如:我们有巴西和澳大利亚的信息,我们按照城市来分组就要用emit函数,用城市名当key

这样我们就得到了一组key-values对,则第一次values中装的就是巴西组的信息,第二次values中装的是澳大利亚组的信息。values数组中则装的是每个城市的信息。具体有哪些信息取决于我们的emit函数的第二个参数发送了哪些信息。
在reduced和finalize里我们就能进行相应的统计计算或者结构重构等操作。
mapreduce例子:
首先我们插入数据
db.c.insert({country:"中国" province:"广东省" city:"广州" temprature:"12°C" weather:"晴"});
db.c.insert({country:"中国" province:"广东省" city:"深圳" temprature:"15°C" weather:"晴"});
db.c.insert({country:"中国" province:"广东省" city:"珠海" temprature:"7°C" weather:"多云"});
db.c.insert({country:"中国" province:"贵州省" city:"贵阳" temprature:"4°C" weather:"晴"});
db.c.insert({country:"中国" province:"贵州省" city:"遵义" temprature:"2°C" weather:"晴"});
db.c.insert({country:"中国" province:"云南省" city:"昆明" temprature:"24°C" weather:"多云"});
db.c.insert({country:"中国" province:"云南省" city:"丽江" temprature:"22°C" weather:"晴"});
db.c.insert({country:"澳大利亚" province:"新南威尔士州" city:"悉尼" temprature:"15°C" weather:"晴"});
db.c.insert({country:"澳大利亚" province:"维多利亚州" city:"墨尔本" temprature:"20°C" weather:"晴"});
PS:由于MongoDB中没有提供给shell的“批量插入方法”,不过各个语言的驱动driver有提供批量的方法。或者对于相同的数据可以用for循环插入。在这里我直接用mongovue直接分9次插入。
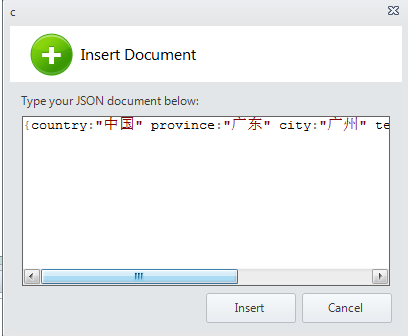
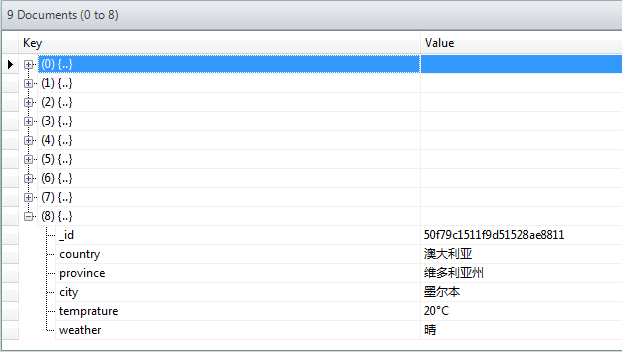
插入完成后一共有9条数据:
用法一:
1.计数的例子:
一:求所有记录的总条数
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(
1, // how to group
{count: 1} // associated data point (document)
);
},
reduce : function Reduce(key, values) {
Total=0;
values.forEach(function(val) {
Total += val.count;
});
return Total;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
结果:

分析:map函数中emit函数分组,因为我们要算所有记录的总条数,所有这里就不分组了。key可以用任意的数值。这样就只有一个小组。在reduced里求总数。返回。 可以得到一共有9条记录
二:求分组后小组的记录条数(这里我们用国家来分组)
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(
this.country, // how to group
{count: 1} // associated data point (document)
);
},
reduce : function Reduce(key, values) {
Total=0;
values.forEach(function(val) {
Total += val.count;
});
return Total;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
结果:

分析:map函数中emit函数分组,用country当key。有两个小组:中国和澳大利亚。在reduced里求每一个小组的总数。返回。 可以得到一共有中国有7条记录,澳大利亚有2条记录
2.实现聚合函数:
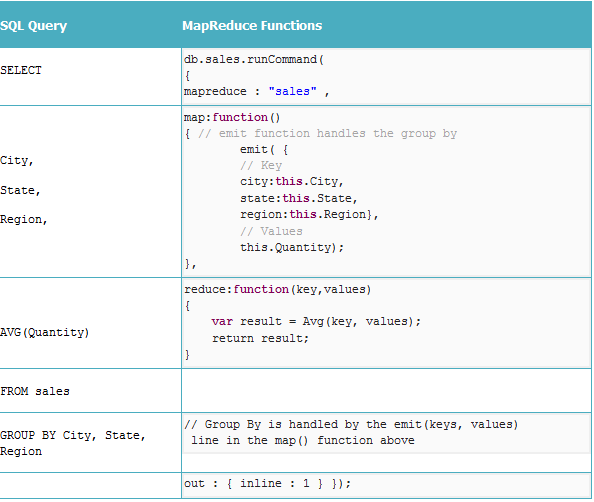
求平均:
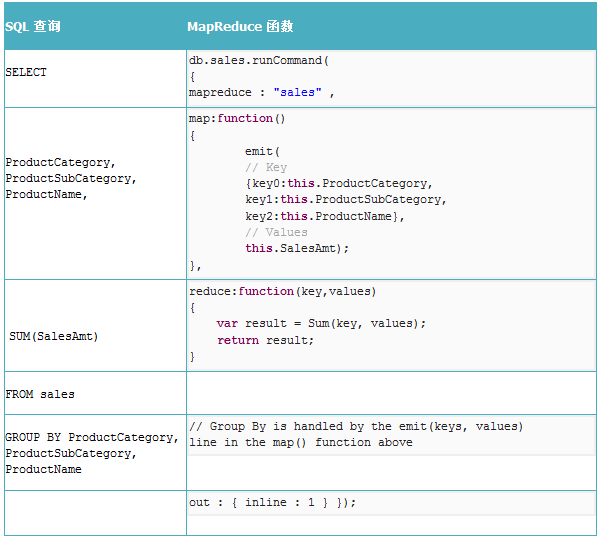
求总和:
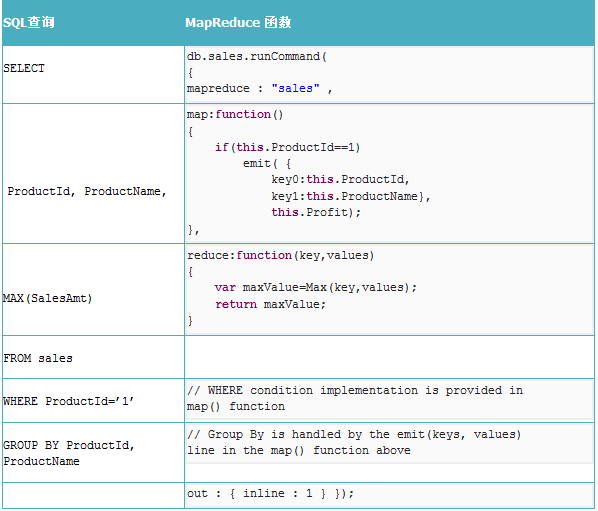
求最大:
用法二:
1.分组去除重复的运用(分组的key可自由拼接组合)
如果我们要去除重复,只要找出它们的共同点,再用emit函数的分组功能来分组就能实现了。分组的key可以多个标签的值构造。
例如计数例子中的数据,我们每个省只想要一条记录,其他的去掉:
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(
this.province,
{country:this.country,province:this.province,city:this.city,temprature:this.temprature,weather:this.weather}
);
},
reduce : function Reduce(key, values) {
var reduced={country:{},province:{},city:{},temprature:{},weather:{}};
reduced.country=values[0].country;
reduced.province=values[0].province;
reduced.city=values[0].city;
reduced.temprature=values[0].temprature;
reduced.weather=values[0].weather;
return reduced;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
结果:


分析:map函数中我们用省province来分组,一共有四个小组。则每一次values数组代表一个省的数据。values数组中对应则是每一个城市的数据。
这里我们只取values[0]里的数据。
2.分组后把同一组的数据放在同一条文档中(foreach--数组.push)
如果我们经过省分组后,但是又想把每一个省其中的城市的数据都取出来,而不是只取一个城市。那可以用如下方法:
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(
this.province, // how to group
{country:this.country,province:this.province,city:this.city,temprature:this.temprature,weather:this.weather} // associated data point (document)
);
},
reduce : function Reduce(key, values) {
var reduced={country:{},province:{},city:[],temprature:[],weather:[]};
values.forEach(function(val) {
reduced.country=val.country;
reduced.province=val.province;
reduced.city.push(val.city);
reduced.temprature.push(val.temprature);
reduced.weather.push(val.weather);
});
return reduced;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
结果:
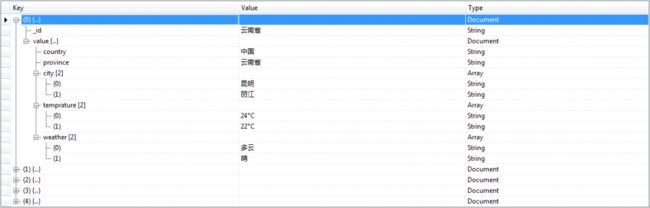
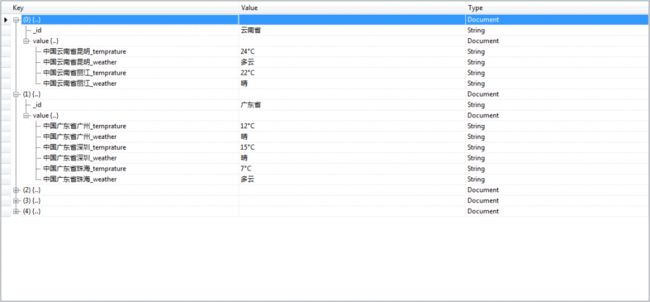
3.用提取的数据当key名
从上面的例子我们可以知道文档的标签都是我们一开始就定义的,那能不能用从数据库中提取的数据来当标签呢?
例子如下:
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(
this.province, // how to group
{country:this.country,province:this.province,city:this.city,temprature:this.temprature,weather:this.weather} // associated data point (document)
);
},
reduce : function Reduce(key, values) {
var reduced={};
values.forEach(function(val) {
reduced[val.country+val.province+val.city+"_temprature"]=(val.temprature);
reduced[val.country+val.province+val.city+"_weather"]=(val.weather);
});
return reduced;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
结果:
4.嵌套文档的格式构造(构造数组中的数组)
db.runCommand({ mapreduce: "c",
map : function Map() {
emit(this.province, {country:this.country,province:this.province,city:this.city,temprature:this.temprature,weather:this.weather}
)
},
reduce : function Reduce(key, values) {
var result=[];
for(c=0;c<values.length;c++)
{
result[c]={country:values[c].country,province:values[c].province,data:[]};
for(i=0;i<values.length;i++)
{
result[c].data[i]={nature:[]};
result[c].data[i].nature[0]={city:values[c].city};
result[c].data[i].nature[1]={temprature:values[c].temprature};
result[c].data[i].nature[2]={weather:values[c].weather};
}
}
return result[0];
},
finalize : function Finalize(key, reduced) {
/*
// Make final updates or calculations
reduced.avgAge = reduced.age / reduced.count;
*/
return reduced;
},
out : { inline : 1 }
});
结果:

分析:从结果可以看出已经构造出了数组里的数组这种结构,关键的构造方法部分已经用蓝颜色标出。
三:根据条件进行筛选
db.runCommand({ mapreduce: "data",
map : function Map() {
if(this.location=="青岛")
{
emit(
"result", // how to group
this // associated data point (document)
);
}
},
reduce : function Reduce(key, values) {
var reduced = {city:[]}; // initialize a doc (same format as emitted value)
values.forEach(function(val) {
reduced.city.push(val);
});
return reduced;
},
finalize : function Finalize(key, reduced) {
/*
// Make final updates or calculations
reduced.avgAge = reduced.age / reduced.count;
*/
return reduced;
},
out : { inline : 1 }
});
疑问:
1.对一个集合做mapreduce时 能引用到另一个集合的数据么? 用DBf能不能做到?
2.分组后还能更改_id么 拼接分组后 想改成标准_Id(可在emit时用new ObjectId()创建新_id,但不再具有分组功能)
例如:
![]()
用省份作为key分组后,_id就是显示的省份,能不能让它变成一个正常的id如下格式的id

3.提取的数据能声明成为全局变量么? 即在map时只对第一条文档,提出数据,然后在第二条文档时能使用第一条的数据。类似于在scope里声明[now_date:new data();],now_date就能在全局使用,可以对map,reduce,finalize函数 以及对每一条文档处理时都能使用。但这个变量我需要从数据中提取。
4.第一组文档要与第二组文档的数据进行比较,怎么实现(感觉mapreduce处理的流程是处理完一条文档后开始第二条文档)
我们知道比如用国家分组。 reduce : function Reduce(key, values)中values数组中第一次只包含了中国的数据,values[0]里装的是中国的第一个城市数据,values[1]装的是中国的第二个城市数据,。。。处理完中国的数据后,才进行第二次reduce : function Reduce(key, values) values里包含了澳大利亚的数据,values[0]中装的是澳大利亚第一个城市的数据。。。
我想用中国城市的数据跟澳大利亚的对比 怎么进行