消息总线授权设计
我曾在之前的一篇文章中对比过消息队列跟消息总线。它们其中的一个不同点就是:消息总线更关注通信安全,消息总线可以管控通信双方,对通信的管控是建立在授权的基础上。因此授权模型的设计是消息总线必须考虑的问题。所谓的授权,就是校验通信双方有没有建立可信任的通信关系。这篇文章我们来谈谈消息总线的权限设计。
消息总线使用场景及RabbitMQ通信简介
在介绍授权设计之前,我们先了解一些必要信息。通常我们将消息总线应用于以下这些场景:
- 缓冲类——自生产自消费
- 解耦类、异步类——生产者消费者模型
- 服务调用类(RPC)——请求/响应
- 管控协调类——发布/订阅
- 通知类——广播
- Publish(发送方):只需要了解exchange,routingkey
- Consume(接收方):需要了解queue,routingkey
申请方app跟通信队列建立关联关系
其实所谓的授权,对应到数据库的模型里就是建立通信双方的数据库记录之间的关系。在建立关系的时候接收方肯定是以queueId作为队列主键来创建关系。而发送方呢?如果像上面假设的那样:它不需要队列就只能以appId作为创建关系了。这种授权方式也很普遍,比如在服务注册中心申请调用某个服务时,以一个appId的身份向服务管控台申请调用服务。但这种建立关系的方式,在消息总线的授权上遇到如下两个方面的问题。
多重身份问题
第一个场景是缓冲类的场景,很多消息都是自生产自消费的。对于这种场景,只需依靠本应用下的一个队列,而不需要跟外部应用通信;第二个场景是pipeline-filter模型下的某个stage或component。如图示:
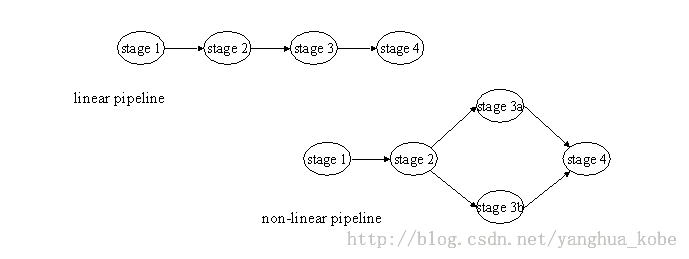
它接收来自上一个stage的中间结果,处理完数据之后,再将最新的中间结果发送给下一个stage。
这两种情况下,发送方必须拥有队列。
request/response模型的问题
对web服务而言,一次调用从通信模型上看是一个request/response模型。但这个通信依靠的是http协议,而RabbitMQ的消费基于的是队列(队列的好处就是缓冲、异步、解耦这些特征与阻塞等待是对立的)。在这种情况下,我们要基于RabbitMQ模拟出request/response模型(注意这不是为了违背队列的初衷,而是为了简化特定业务场景的通信),就必须依赖一个接收response响应的队列,因此这种模型注定了request端也必须拥有一个队列。当然或许你觉得,如果基于一个临时生成的队列,接收完响应消息立即销毁队列,就如同http的无状态特征一样,也是可行的。我不是没想过这种做法,只是这取决于request/response模型使用的频度,如果频度不高是可以接收的;但如果非常频繁的话,创建队列的成本肯定远大于一直维持一个固定队列的成本。
虚拟队列
看起来给发送方也分配一个队列是比较可行的解决方案。但对于单纯的发送方,分配队列造成了消息服务器资源的浪费,因为从通信的角度来看,完全不需要一个真实队列的存在,而在这里它存在的目的却是为了契合对等授权模型。因此,我们可以选择一种折中的处理方案——对单纯的发送方而言,用虚拟队列代替真实队列。
当某个app申请队列时,我们将其分为三类:单纯的发送方、单纯的接收方、既是发送方同时也是接收方。只有后两者才会在RabbitMQServer上创建真实的队列,单纯的发送方不会在RabbitMQServer上创建真实队列,只在数据库中为其创建一个队列记录而已。以下我们谈及的队列既可能是真实队列,也可能是虚拟队列。每个队列都会被分配有一个secret,以唯一全局标识该队列,并且从安全角度而言,该队列的secret只有申请者自身以及管控台知道。
队列按通信模型进行隔离
一个队列在创建的时候,它必须选择是作为发送方还是接收方还是两者都有以及是哪种通信类型。只有指定了通信类型,才能让它正确地绑定到合适的exchange下去。另外通信的两个队列只能处于相同的模型内,比如,永远不可能出现produce/response或者request/consume这些交叉的通信模型。
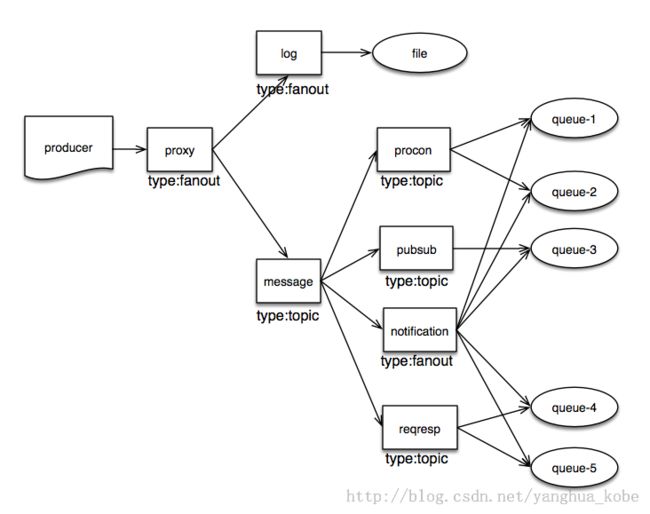
这种隔离既是技术上的约束也是语义上的约束。
授权实现
上面谈到一些设计的前提以及理由。下面我们谈谈,我们是如何来实现授权的。授权主要分为如下三个方面。
队列申请
首先,必须经历的一步是审核队列申请。也就是一个应用要跟别的队列进行通信,它必须来申请一个队列,然后管控台的审核人员需要对其进行审核。其实这里的审核主要是针对publish以及broadcast。因为produce/consume、request/response这两组点对点的通信模型,它们的通信还需要经过一次建立连接的审核。而broadcast,publish作为公共或半公开的服务,在它们发送消息时是不需要被授权的。
信道
根据通信模型不同,我们对发送方跟接收方建立的关系也有所不同。对于produce/consume以及request/response这两个模型而言,创建的是点对点的通信链路,这里我们称其为信道(Sink)。
一个信道是一条单向的链路,基于源队列跟目的队列建立。关于接收方有一个原则:因为每个接收方只能消费自己队列里的消息,因此我们主要把控从发送方到接收方这条有向线路的发送权限,这就跟http请求一样,通常你只在server校验请求发起方是否是可信任的。
信道的控制台展示:
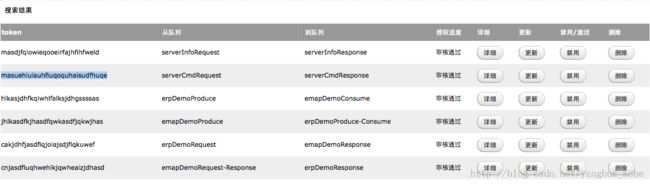
对于这种模型下的通信,发送者需要持有:
- 自身队列的标识:secret
- 目标队列的名称:targetQueueName(该名称默认对外公开)
- 信道授权后获取到的token
频道
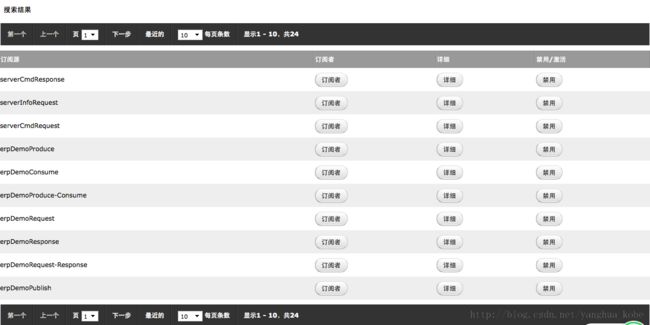
基于这种模型的通信,发送方(publish)只需要持有:自身队列的标识:secret就可以了。授权体现在publish的时候,查找要发送的订阅者的过程。
而订阅方只需要持有自身队列的标识:secret,即可消费自己订阅的发送方的消息。