java数据库连接(一)--从最简单地jdbc连接说起
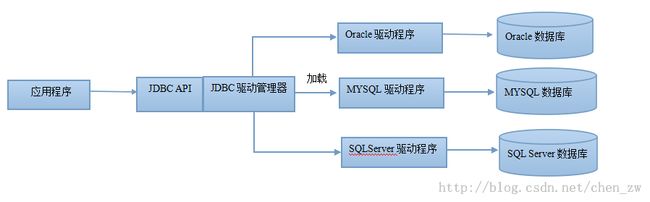
JDBCJDBC全称"Java DataBase Connectivity",它是一套面向对象的应用程序接口(API),并且制定了统一的访问各类关系数据库的标准接口,为各个数据库厂商提供了标准的接口实现。通过使用JDBC技术,开发人员可以用纯Java语言和标准的SQL语句编写完整的数据库应用程序,真正地实现软件的跨平台。
本文地址:http://blog.csdn.net/chen_zw/article/details/18514723
JDBC对多种关系型数据库的驱动和操作都进行了封装,因此,开发者不需要编写额外的程序来兼容不同的数据库连接,只需要通过加载不同的数据库驱动程序即可完成连接,我们首先简单地封装JDBC连接类:
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import oracle.jdbc.driver.OracleConnection;
/**
* @Description: JDBC连接类(示例连接Oralce)
* @CreateTime: 2014-1-19 下午9:46:44
* @author: chenzw
* @version V1.0
*/
public class JdbcUtil {
//驱动名
private static String DRIVER = "oracle.jdbc.driver.OracleDriver";
//获得url
private static String URL = "admin";
//获得连接数据库的用户名
private static String USER = "jdbc:oracle:thin:@localhost:7001:test";
//获得连接数据库的密码
private static String PASS = "";
static {
try {
//1.初始化JDBC驱动并让驱动加载到jvm中,加载JDBC驱动后,会将加载的驱动类注册给DriverManager类。
Class.forName(DRIVER);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static Connection getConnection(){
Connection conn = null;
try {
//2.取得连接数据库
conn = DriverManager.getConnection(URL,USER,PASS);
//3.开启自动提交
conn.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
//开启事务
public static void beginTransaction(Connection conn) {
if (conn != null) {
try {
if (conn.getAutoCommit()) {
conn.setAutoCommit(false);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//提交事务
public static void commitTransaction(Connection conn) {
if (conn != null) {
try {
if (!conn.getAutoCommit()) {
conn.commit();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//回滚事务
public static void rollBackTransaction(Connection conn) {
if (conn != null) {
try {
if (!conn.getAutoCommit()) {
conn.rollback();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//关闭连接
public static void close(Object o){
if (o == null){
return;
}
if (o instanceof ResultSet){
try {
((ResultSet)o).close();
} catch (SQLException e) {
e.printStackTrace();
}
} else if(o instanceof Statement){
try {
((Statement)o).close();
} catch (SQLException e) {
e.printStackTrace();
}
} else if (o instanceof Connection){
Connection c = (Connection)o;
try {
if (!c.isClosed()){
c.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//重载关闭连接
public static void close(ResultSet rs, Statement stmt,
Connection conn){
close(rs);
close(stmt);
close(conn);
}
//重载关闭连接
public static void close(ResultSet rs,
Connection conn){
close(rs);
close(conn);
}
//重载关闭连接
public static void close(ResultSet rs, PreparedStatement ps,
Connection conn){
close(rs);
close(ps);
close(conn);
}
}
JDBC数据库连接的查询主要通过Statement对象来执行各种SQL语句。Statement对象主要分为以下3种类型:
1. Statement :执行静态SQL语句的对象。
Statement接口常用的2个方法:
(1) executeUpdate(String sql) :执行insert / update / delete 等SQL语句,成功返回影响数据库记录行数的int整数型。
(2) executeQuery(String sql) : 执行查询语句,成功返回一个ResultSet类型的结果集对象。
ResultSet rs = null;
Statement stmt = null;
try {
stmt = conn.createStatement();
int num = stmt.executeUpdate("insert into company values('No.1','CSDN')");
rs = stmt.executeQuery("select * from company");
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
1.1 Statement批量处理函数:
(1) addBatch(String sql) :添加批量处理的数据;
(2) executeBatch():提交批量数据;
(3) clearBatch():清空已添加的批量数据;
/**
* 实验一:Statement.executeBatch();
*/
ResultSet rs = null;
Statement stmt = null;
try {
conn.setAutoCommit(false); //切记:必须设置成手动提交模式,否则每次addBatch都会提交一次,而不是批量提交
stmt = conn.createStatement();
Long startMemory = Runtime.getRuntime().freeMemory();
Long startTime = System.currentTimeMillis();
for(int i = 0; i < 10000; i++){
stmt.addBatch("insert into t_dept values('No.1','CSDN')");
//stmt.executeUpdate("insert into t_dept values('No.1','CSDN')");
}
stmt.executeBatch();
conn.commit();
Long endMemory = Runtime.getRuntime().freeMemory();
Long endTime = System.currentTimeMillis();
System.out.println("使用内存大小:"+ (startMemory-endMemory)/1024 + "KB");
System.out.println("用时:"+ (endTime-startTime)/1000 + "s");
} catch (SQLException e) {
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
//执行结果:
使用内存大小:488KB
用时:116s --汗,原谅我的电脑龟速。
/**
* 实验二:Statement.executeUpdate();
*/
//而如果直接使用executeUpdate更新(其实一样是批量提交),竟然比executeBatch速度更快,效率更高,这个真的百思不得其解,留待以后解决。。
ResultSet rs = null;
Statement stmt = null;
try {
conn.setAutoCommit(false); //切记:必须设置成手动提交模式,否则每次addBatch都会提交一次,而不是批量提交
stmt = conn.createStatement();
Long startMemory = Runtime.getRuntime().freeMemory();
Long startTime = System.currentTimeMillis();
for(int i = 0; i < 10000; i++){
//stmt.addBatch("insert into t_dept values('No.1','CSDN')");
stmt.executeUpdate("insert into t_dept values('No.1','CSDN')");
}
//stmt.executeBatch();
conn.commit();
Long endMemory = Runtime.getRuntime().freeMemory();
Long endTime = System.currentTimeMillis();
System.out.println("使用内存大小:"+ (startMemory-endMemory)/1024 + "KB");
System.out.println("用时:"+ (endTime-startTime)/1000 + "s");
} catch (SQLException e) {
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
//执行结果:
<span style="font-family: Arial, Helvetica, sans-serif;">使用内存大小:329KB</span>
用时:98s
Note:
本次实验得出的结论是使用executeUpdate的批量提交法比executeBatch效率高,速度更快,占用内存更小,如果有朋友有不同结论的话,欢迎留言交流。
1.3 Statement可滚动ResultSet配置:
(1) java.sql.Connection.creatStatement(int resultSetType,int resultSetConcurrency);
(2) java.sql.Connection.creatStatement(int resultSetType,int resultSetConcurrency,int resultSetHoldability);
参数:
[1] resultSetType: -- 生成的ResultSet的类型
ResultSet.TYPE_FORWARD_ONLY -- 结果集只允许向前滚动,默认缺省值
ResultSet.TYPE_SCROLL_INSENSITIVE -- 结果集对数据库中的的数据变动是不敏感的
ResultSet.TYPE_SCROLL_SENSITIVE -- 结果集对数据库中的的数据变动是敏感的(实际上只对Update的数据敏感)
Note:ResultSet为TYPE_SCROLL_INSENSITIVE时,我们取出的是数据库中真实数据,并且保存在内存中,一旦取出后,数据库中数据进行变动将不能及时更新到ResultSet中; 而ResultSet为TYPE_SCROLL_SENSITIVE时,我们取出的是数据库中数据的索引值(类似于rowid),每次rs.next()时将根据该索引时重新从数据库中取出数据,所以说是敏感的,但是如果数据库中进行的是添加或是删除操作,那敏感性也将无效。(自己思考,索引值)
[2] resultSetConcurrency: -- 生成的ResultSet的并发性(指定是否可修改ResultSet结果集)
ResultSet.CONCUR_READ_ONLY -- 结果集不可修改(只读),默认缺省值
ResultSet.CONCUR_UPDATABLE -- 结果集可修改
ResultSet rs = null;
Statement stmt = null;
try {
stmt = conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY); //可滚动,
rs = stmt.executeQuery("select * from staff");
System.out.println(rs.isBeforeFirst()); //true,判断指针是否在结果集的开头
rs.beforeFirst(); //指针定位到开头,该行取不到数据
rs.next(); //必须先把指针移到数据上,才算是结果集的第一行
System.out.println(rs.isFirst()); //true,判断指针是否在结果集的第一行
rs.first(); //指针重新定位到结果集的第一行
rs.absolute(20); //指针定位到结果集的第20行
rs.previous(); //指针移动到上一行
System.out.println(rs.getString(1));
rs.last(); //指针定位到结果集的最后一行
System.out.println(rs.isLast()); //true,判断指针是否在结果集最后一行
rs.afterLast(); //指针定位到末尾,该行取不到数据
System.out.println(rs.isAfterLast()); //true,判断指针是否在结果集的末尾
} catch (SQLException e) {
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
} <span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);"> </span>
2. PrepareStatement: 执行预编译SQL语句对象。
PrepareStatement接口常用的2个方法:
(1) executeUpdate(String sql) :执行insert / update / delete 等SQL语句,成功返回影响数据库记录行数的int整数型。
(2) executeQuery(String sql) : 执行查询语句,成功返回一个ResultSet类型的结果集对象。
ResultSet rs = null;
PreparedStatement ps;
try {
ps = conn.prepareStatement("insert into company values(?,?)");
ps.setString(1, "No1.");
ps.setString(2, "csdn");
int num = ps.executeUpdate();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
try {
ps = conn.prepareStatement("select * from company");
ps.setString(1, "No1.");
ps.setString(2, "csdn");
rs = ps.executeQuery();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
优点:(1)可以有效SQL注入式攻击,提高安全性。(2)使用预处理语句在性能上提升很多。
2.1 PrepareStatement批量处理函数:
(1) addBatch(String sql) :添加批量处理的数据;
(2) executeBatch():提交批量数据;
(3) clearBatch():清空已添加的批量数据;
/**
* 实验三:PreparedStatement.executeBatch();
*/
ResultSet rs = null;
PreparedStatement ps = null;
try {
conn.setAutoCommit(false); //切记:必须设置成手动提交模式,否则每次addBatch都会提交一次,而不是批量提交
Long startMemory = Runtime.getRuntime().freeMemory();
Long startTime = System.currentTimeMillis();
ps = conn.prepareStatement("insert into t_dept values(?,?)");
for(int i = 0 ; i < 10000; i++){
ps.setString(1, "No1.");
ps.setString(2, "csdn");
ps.addBatch();
//ps.executeUpdate();
}
ps.executeBatch();
conn.commit();
Long endMemory = Runtime.getRuntime().freeMemory();
Long endTime = System.currentTimeMillis();
System.out.println("使用内存大小:"+ (startMemory-endMemory)/1024 + "KB");
System.out.println("用时:"+ (endTime-startTime)/1000 + "s");
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
JdbcUtil.close(rs, ps, conn);
}
//执行结果:
使用内存大小:2110KB
用时:0s --无语了,实在太快了,10000条。。。
/**
* 实验四:PreparedStatement.executeUpdate();
*/
//直接使用executeUpdate批量提交,速度慢的可怕。。
ResultSet rs = null;
PreparedStatement ps = null;
try {
conn.setAutoCommit(false); //切记:必须设置成手动提交模式,否则每次addBatch都会提交一次,而不是批量提交
Long startMemory = Runtime.getRuntime().freeMemory();
Long startTime = System.currentTimeMillis();
ps = conn.prepareStatement("insert into t_dept values(?,?)");
for(int i = 0 ; i < 10000; i++){
ps.setString(1, "No1.");
ps.setString(2, "csdn");
//ps.addBatch();
ps.executeUpdate();
}
//ps.executeBatch();
conn.commit();
Long endMemory = Runtime.getRuntime().freeMemory();
Long endTime = System.currentTimeMillis();
System.out.println("使用内存大小:"+ (startMemory-endMemory)/1024 + "KB");
System.out.println("用时:"+ (endTime-startTime)/1000 + "s");
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
JdbcUtil.close(rs, ps, conn);
}
//执行结果:
使用内存大小:1617KB
用时:190s --内存占用少了点,但是时间嘛,我只能说呵呵。。
总结:
使用批量提交数据一定要选用预编译的executeBatch()方法,虽然内存占用多了点,但是速度快才是王道。
2.2 PrepareStatement可滚动ResultSet配置:
(2) java.sql.Connection.PreparedStatement prepareStatement(String sql,int resultSetType,int resultSetConcurrency,int resultSetHoldability);
参数及其用法详见上面1.3。
3. CallableStatement接口常用的2个方法:
(1) executeUpdate(String sql) :执行insert / update / delete 等SQL语句,成功返回影响数据库记录行数的int整数型。
(2) executeQuery(String sql) : 执行查询语句,成功返回一个ResultSet类型的结果集对象。
ResultSet rs = null;
CallableStatement cs;
try {
cs = conn.prepareCall("{call p_insert(?,?)}");
cs.setString(1, "No1.");
cs.setString(2, "csdn");
int num = cs.executeUpdate();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}
try {
cs = conn.prepareCall("{call p_select(?)}");
cs.setString(1, "No1.");
rs = cs.executeQuery();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
conn.rollback();
}finally{
JdbcUtil.close(rs, stmt, conn);
}