Word2vec在事件挖掘中的调研
Word2vec在事件挖掘中的调研
最近有一个项目,需要从每天的搜索日志中挖掘出每天的热点事件。现在把这些调研的思路给记录下来。
事件挖掘的整体流程如下:

数据源
这次主要用到的数据源有 “Query PV数据”和session数据”(我厂最不差的就是这两种资源了)。
Session数据:即一个session周期内用户的搜索query数据。
TopN热门Query挖掘
考虑了当天PV和前N天的总PV两个因素(N取7天)。query热点 计算公式为:
T = PV1 / (PV2+ m)
(注:其中T 为query的 热度,m>=1(我取20),pv1为query当前日的pv ,pv2为前7天的平均pv)
统计分析了 3.5号的比较热门的query,结果如下:
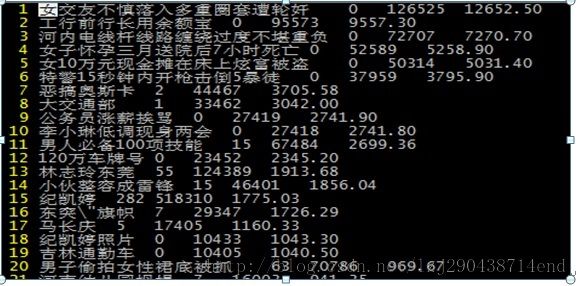
从这些看query比较靠谱,不过 为什么网民会对 排名第一和第20的query这么感兴趣呢(跟我调研的方向无关,就没有深究了)?
Word2vec模型训练
Word2vec模型训练,在之前更多的应用场景是对语料切词,训练得到一个term的vector向量。
我使用的输入语料是session下的query,作为上下文,因为一般来说一个session下的query是比较相关的。。希望通过训练能够把相关的query映射到一个空间下。
模型训练完之后,抽样了几个query,效果图如下:

层次聚类
在之前已经得到了每天前1万个热门query,并且通过session数据训练得到了query的语义向量表述。这样使用query的向量对1万个query进行聚类,得到的每个类即为每一个事件。选择层次聚类是因为对簇的个数未知,只要聚类之间的相似度小于指定阈值,即退出聚类过程。簇之间的计算公式采用的是簇之间每个点之间的距离求平均(热门query,效率问题不需要考虑)
聚类之后的效果如下:

因此,从结果可以很容易的分析热点事件为:“纪凯婷”“男子头牌被抓”“特警15秒搞定暴徒”“李克强政府报告”
总结:
1. 使用word2vec训练的模型,能够很好的语义表述query,不需要query之间一定有字面交集。如:“特警15秒钟内开枪击倒5暴徒”和“车站事件"和”3.1昆明事件"有很强的语义关联,这是 传统的 tf-idf方法是达不到的。
2. word2vec模型也有其不足的地方,会有大量的query是低频的,甚至直接被 -min-count给过滤掉了,所以query的召回会存在问题。
3. 是用word2vec向量进行聚类,解决了传统的只考虑字面特征的特征稀疏和语义表达不明确的问题
4. 使用层次聚类优于k-means聚类算法。k-means算法k值不好确定,从而使得每个类的query过于混杂的问题。
就写这么多了,第一次写blog,迈出第一步,很开心。