Intel Threading Building Blocks 编程指南:异常与终止
Intel TBB支持异常与终止(cancellation),当算法中的代码抛出异常时,会按依次发生:
- 捕获异常。算法内进一步的异常被忽略。
- 算法终止。挂起的迭代操作不被执行。如果内部存在嵌套的Intel TBB并行,那么它的取消与否取决于特定实现(下面会提到)
- 算法的所有部分都停止后,会在调用算法的线程(thread)上抛出异常。
步骤3中抛出的异常可能是初始的异常,也可能仅仅是captured_exception类型的摘要。后者常发生在当前的系统中,因为在线程间传递异常需要支持C++的std::exception_ptr机制。随着编译器在支持此项特性上的进展,将来的Intel TBB版本可能抛出初始的异常。所以,确保你的代码可以捕获两种异常中的任意异常。
#include "tbb/tbb.h"
#include <vector>
#include <iostream>
using namespace tbb;
using namespace std;
vector<int> Data;
struct Update {
void operator ()(const blocked_range<int>& r) const
{
for (int i = r.begin(); i != r.end(); ++i) Data.at(i) += 1;
}
};
int main()
{
Data.resize(1000);
try
{
parallel_for(blocked_range<int>(0, 2000), Update());
}
catch (captured_exception& ex)
{
cout << "captured_exception: " << ex.what() << endl;
}
catch (out_of_range& ex)
{
cout << "out_of_range: " << ex.what() << endl;
}
return 0;
}
无异常终止
要取消某个算法而不抛出异常,使用表达式 task::self().cancel_group_execution(). 其中的task::self()引用当前线程最靠内的Intel TBB任务。调用cancel_group_execution()取消它的task_group_context中的所以线程(下节会详细介绍)。如果的确导致了任务终止,此方法会返回 true ,如果task_group_context 已经被取消,就会返回 false。
#include "tbb/tbb.h"
#include <vector>
#include <iostream>
using namespace tbb;
using namespace std;
vector<int> Data;
struct Update {
void operator ()(const blocked_range<int>& r) const
{
for (int i = r.begin(); i != r.end(); ++i) if (i < Data.size())
{
++Data[i];
}
else
{
// Cancel related tasks.
if (task::self().cancel_group_execution())
cout << "Index " << i << " caused cancellation\n";
return;
}
}
};
int main()
{
Data.resize(1000);
parallel_for(blocked_range<int>(0, 2000), Update());
return 0;
}
终止与嵌套算法
目前还没有讨论嵌套算法,并且忽略了 task_group_context 的细节。本节将细述两者。
Intel TBB的算法的执行需要创建 task 对象,此对象会执行你提供给算法模板的代码片段。默认这些 task 对象会关联一个算法创建的 task_group_context。嵌套的Intel TBB算法创建一棵 task_group_context 对象树。终止一个 task_group_context 将会使其所有的子孙 task_group_context 对象终止。因此,一个算法和被它调用的所有算法可以通过一个请求终止。
异常向上传播。终止向下传播。这种对立的相互作用是为了在异常发生时能干净地停止一个嵌套计算。以下面图形中的书为例,想象每个节点表示一个算法以及它的 task_group_context:
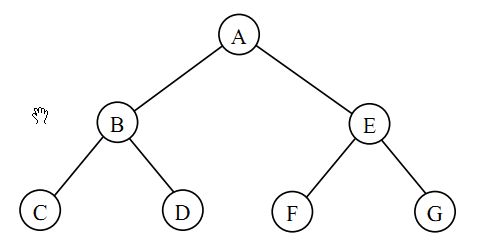
假设节点C抛出一个异常,并且没有节点捕获这个异常。Intel TBB 将此异常往上传递,终止下面相关的子树:
1. 在C节点处理异常:
a. 在C处捕获异常
b. 终止C处的任务
c. 抛出异常 C->B
2. 在B节点处理异常:
a. 在B处捕获异常
b. 终止B中的任务,根据向下传播原则,再终止D中的
c. 抛出异常 B->A
3. 在A节点处理异常
a. 在A处捕获异常
b. 终止A中的人物,根据向下传播的原则,终止E,F和G的任务
c. 从A点“向上”抛出异常
只要你的代码捕获了异常(别管在哪层),Intel TBB 都不会继续传播该异常了。例如,一个异常如果没有脱离外部的 parallel_for 函数体,就不会导致其他的迭代操作终止。
为了防止终止操作的向下传播进入某个算法,在栈上构造一个“孤立”的 task_group_context,并将其显式传递给算法。详情见下面的代码(简洁起见,使用了C++0X的lambda表达式):
#include "tbb/tbb.h"
bool Data[1000][1000];
int main()
{
try
{
parallel_for(0, 1000, 1,
[](int i)
{
task_group_context root(task_group_context::isolated);
parallel_for(0, 1000, 1,
[](int j)
{
Data[i][j] = true;
},
root);
throw "oops";
});
}
catch (...)
{
}
return 0;
}
该例执行两个并行循环:外部在 i 上循环,内部在 j 上循环。内部的代码[ task_group_context root ]保护内部的循环,使其不被 i 循环中发生异常后的向下传播规则影响。当异常传递给外部循环时,所有挂起状态的外部迭代都会终止,但已经开始运行的外部迭代的内层迭代不会。因此,当程序完工后,Data 的每一行都可能不同,取决于它的 i 迭代是否完全执行。但是在同一行,元素都统一为 false 或者 true , 而不是混合的。
如果去掉创建 root 对象的代码,将会允许终止操作向下传播到内层循环中。这样,Data 的一行中可能会包含 true、false 两种值