Oracle Parallelism concepts
一,可以执行并行的操作:
访问方式:
1,表扫描,快速索引扫描(即把索引的索引都扫描出来),索引是不可以并行操作的,因为它要知道下一个扫描谁。
2,分区索引范围扫描
表连接:
1,嵌套扫描,排序合并
2,哈希,星型转换,智能化分区连接(partitionwise join)
DDL 语句:
CTAS,cteate index,rebuild index [PARTITION]
MOVE,SPLIT,COALESCE PARTITION(其中COALESCE PARTITION是针对HASH的)
DML 语句:
insert select,update,delete,merge
二,并行是如何工作的
*串行操作某一个时刻只有一个进程被使用,而并行操作则可以:
1,每个并行操作都有一个coordinator(协调者)进程在使用
2,并行操作有多个(servers)服务器进程在同时使用
3,表会被动态的均匀的分割成粒度(granules)
三,何为granules
1,并行工作的一个基本单元被称为GRANULES,它有如下类型:
a, Block range granules: Server进程在执行的时候就动态的产生。
b,Partition granules : 有分区的数量静态的决定。
2,一个granule只能有一个并行执行的server进行读的操作
3,并行的一个server可以从一个granule到另外一个granule的执行任务,即当一个任务完成了就去接着执行下一个任务。
4,granule的类型由并行操作决定。
例下图就是一个并行操作,假设DOP(Degree of Parallelism并行度为3)
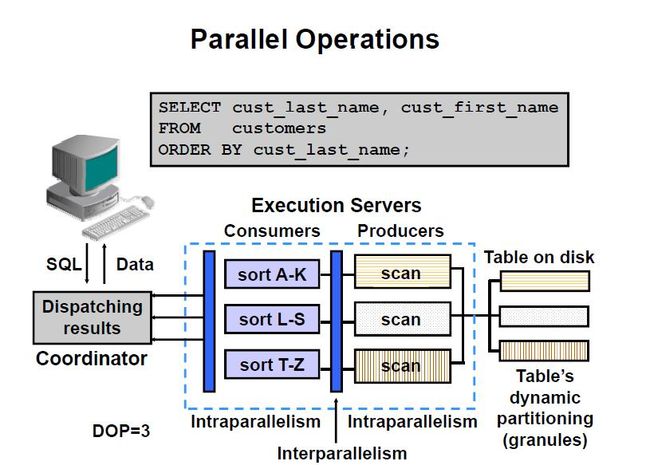
select cust_last_name,cust_first_name from customers order by cust_last_name;
customers 表会被动态的分成3个granules,分别由3个producers去负责scan,即每个producer负责扫描自己的一个granule.扫描结束后把结果按照cust_last_name分别交给3个不同的consumers。每一个producer都会把自己扫描的结果分别交给三个不同的consumers。等consumers排序结束后,就把这个record set一起交给coordinator. 它负责把结果展现给终端客户看。
四:什么是DOP(Degree of Parallelism)并行度
1,DOP是并行操作的所使用的服务器进程的数量
2,DOP只能在intraoperation parallelism里使用
3,如果使用了interoperation parallelism,则并行的服务器进程就是DOP的2倍个数量。
4,最多就两套进程,最少一倍DOP个进程。
五,并行度默认值
1,如果一个并行操作没有指定并行度(DOP),则就用DOP的default值。
2,它是在运行的时候动态的分配的
3,它的值主要由以下两个信息决定:
a, CPU的总数量
b,parallel_threads_per_cpu 它默认值是2
SQL> show parameter parallel_threads_
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
parallel_threads_per_cpu integer 2
六,如何查看并行执行计划
1,并行的执行计划和串行的执行计划有很多的差别
2,为了能看并行执行计划,我们可以使用EXPLAIN PLAN命令或者执行语句:
3,为了能查看执行计划,我们可以使用下面的方法:
a, 通过PLAN_TABLE
b,通过v$SQL_PLAN
c,运行$ORACLE_HOME/rdbms/admin/utlxplp.sql, 通过查看该SQL,可以看出他就是执行下面的语句:
select * from table(dbms_xplan.display());
d,使用DBMS_XPLAN.DISPLAY 函数
4,我们需要注意的列:
--OBJECT_NODE
--OTHER_TAG
--DISTRIBUTION
七,查看执行计划
注意:串行的执行计划是从上往下执行的,而并行的执行计划是从下往上执行的。
1,串行执行计划:
SQL> set autotrace traceonly exp
SQL>SELECT cust_city, sum(amount_sold)
FROM sales s, customers c
WHERE s.cust_id=c.cust_id
GROUP BY cust_city;
Execution Plan
----------------------------------------------------------
Plan hash value: 3821284699
--------------------------------------------------------------------------------
---------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)|
Time | Pstart| Pstop |
--------------------------------------------------------------------------------
---------------------------
| 0 | SELECT STATEMENT | | 620 | 15500 | | 1931 (10)|
00:00:24 | | |
| 1 | HASH GROUP BY | | 620 | 15500 | | 1931 (10)|
00:00:24 | | |
|* 2 | HASH JOIN | | 918K| 21M| 1464K| 1813 (4)|
00:00:22 | | |
| 3 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 812K| | 331 (2)|
00:00:04 | | |
| 4 | PARTITION RANGE ALL| | 918K| 8973K| | 426 (9)|
00:00:06 | 1 | 28 |
| 5 | TABLE ACCESS FULL | SALES | 918K| 8973K| | 426 (9)|
00:00:06 | 1 | 28 |
--------------------------------------------------------------------------------
---------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."CUST_ID"="C"."CUST_ID")
2,并行执行计划:
SQL>set autotrace traceonly exp
SQL> set linesize 200
SQL>SELECT /*+ PARALLEL(s) PARALLEL(c) */ cust_city, sum(amount_sold)
FROM sales s, customers c
WHERE s.cust_id=c.cust_id
GROUP BY cust_city;
Execution Plan
----------------------------------------------------------
Plan hash value: 2890400653
--------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 620 | 15500 | 489 (19)| 00:00:06 | | | | | |
| 1 | PX COORDINATOR | | | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | 620 | 15500 | 489 (19)| 00:00:06 | | | Q1,02 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 620 | 15500 | 489 (19)| 00:00:06 | | | Q1,02 | PCWP | |
| 4 | PX RECEIVE | | 620 | 15500 | 489 (19)| 00:00:06 | | | Q1,02 | PCWP | |
| 5 | PX SEND HASH | :TQ10001 | 620 | 15500 | 489 (19)| 00:00:06 | | | Q1,01 | P->P | HASH |
| 6 | HASH GROUP BY | | 620 | 15500 | 489 (19)| 00:00:06 | | | Q1,01 | PCWP | |
|* 7 | HASH JOIN | | 918K| 21M| 426 (7)| 00:00:06 | | | Q1,01 | PCWP | |
| 8 | PX RECEIVE | | 55500 | 812K| 183 (1)| 00:00:03 | | | Q1,01 | PCWP | |
| 9 | PX SEND BROADCAST | :TQ10000 | 55500 | 812K| 183 (1)| 00:00:03 | | | Q1,00 | P->P | BROADCAST
|
| 10 | PX BLOCK ITERATOR | | 55500 | 812K| 183 (1)| 00:00:03 | | | Q1,00 | PCWC | |
| 11 | TABLE ACCESS FULL| CUSTOMERS | 55500 | 812K| 183 (1)| 00:00:03 | | | Q1,00 | PCWP | |
| 12 | PX BLOCK ITERATOR | | 918K| 8973K| 236 (9)| 00:00:03 | 1 | 28 | Q1,01 | PCWC | |
| 13 | TABLE ACCESS FULL | SALES | 918K| 8973K| 236 (9)| 00:00:03 | 1 | 28 | Q1,01 | PCWP | |
--------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("S"."CUST_ID"="C"."CUST_ID")
当使用了并行执行,SQL的执行计划中就会多出一列:in-out。 该列帮助我们理解数据流的执行方法。它的一些值的含义如下:
Parallel to Serial(P->S): 表示一个并行操作发送数据给一个串行操作,通常是并行incheng将数据发送给并行调度进程。
Parallel to Parallel(P->P):表示一个并行操作向另一个并行操作发送数据,疆场是两个从属进程之间的数据交流。
Parallel Combined with parent(PCWP): 同一个从属进程执行的并行操作,同时父操作也是并行的。
Parallel Combined with Child(PCWC): 同一个从属进程执行的并行操作,子操作也是并行的。
Serial to Parallel(S->P): 一个串行操作发送数据给并行操作,如果select 部分是串行操作,就会出现这个情况。
八,并行执行服务器进程池
1,服务器进程池是在实例启动时创建的。
2,池的最小服务器进程个数由PARALLEL_MIN_SERVERS决定
3,池的服务器进程可以按照需求增加
4,池的最大服务器进程个数由PARALLEL_MAX_SERVERS决定
5,如果一个服务器进程idle的时间超过了阀值,则该进程会被终止。
6,为了能进行并行操作,至少要有两个并行操作的服务器进程。
九,进行并行操作的几个例子
create index ord_customer_ix on orders (customer_id) onlogging parallel;
alter table customers parallel 5;
alter table sales split partition sales_q4_2000 at ('15-NOV-2000') into
(partition sales_q4_1, partition sales_q4_2) parallel 2;
十,如何运行在DML,DDL,QUERY上并行
1,alter session enable|disable|force parallel DML|DDL|QUERY parallel n
2,可以通过V$SESSION查看session状态
--PDML_STATUS
--PDDL_STATUS
--PQ_STATUS
3,上面三个列的值可以是:ENABLED|DISABLED|FORCED
十一,使用并行提示
可以通过下面的并行提示来覆盖已经存在的DOPs
1,PARALLEL (table_name,DOP_value)
select /*+ PARALLEL(SALES,9)*/ * FROM SALES;
2,NOPARALLEL (TABLE_NAME)
3,PARALLEL_INDEX (TABLE_NAME,INDEX,DOP_VALUE)
SELECT /*+ PARALLEL_INDEX(c,ic,3)*/ * from customers c where cust_city='CLERMONT';
4,NOPARALLEL_INDEX (TABLE_NAME,INDEX)
十二,并行需要遵守的一些规则
1,一个SQL语句可以在下面的规则下进行并行操作:
a,如果SQL语句包含了PARALLEL提示
b,执行了alter session force 命令
c,使用SQL中引用的表或者索引上设定的并行度,原则上Oracle 使用这些对象中并行度最高的那个值作为当前执行的并行度。
总结:
并行的实现机制是: 首先,Oracle 会创建一个进程用于协调并行服务进程之间的信息传递,这个协调进程将需要操作的数据集(比如表的数据块)分割成很多部分,称为并行处理单元,然后并行协调进程给每个并行进程分配一个数据单元。比如有四个并行服务进程,他们就会同时处理各自分配的单元,当一个并行服务进程处理完毕后,协调进程就会给它们分配另外的单元,如此反复,直到表上的数据都处理完毕,最后协调进程负责将每个小的集合合并为一个大集合作为最终的执行结果,返回给用户。并行处理的机制实际上就是把一个要扫描的数据集分成很多小数据集,Oracle 会启动几个并行服务进程同时处理这些小数据集,最后将这些结果汇总,作为最终的处理结果返回给用户。这种数据并行处理方式在OLAP系统中非常有用,OLAP系统的表通常来说都是非常大,如果系统的CPU比较多,让所有的CPU共同来处理这些数据,效果就会比串行执行要高的多。然而对于OLTP系统,通常来讲,并行并不合适,原因是OLTP系统上几乎在所有的SQL操作中,数据访问路劲基本上以索引访问为主,并且返回结果集非常小,这样的SQL 操作的处理速度一般非常快,不需要启用并行。
并行处理的机制:
当Oracle 数据库启动的时候,实例会根据初始化参数:PARALLEL_MIN_SERVERS=n的值来预先分配n个并行服务进程,当一条SQL 被CBO判断为需要并行执行时发出SQL的会话进程变成并行协助进程,它按照并行执行度的值来分配进程服务器进程。 首先协调进程会使用ORACLE 启动时根据参数: parallel_min_servers=n的值启动相应的并行服务进程,如果启动的并行服务器进程数不足以满足并行度要求的并行服务进程数,则并行协调进程将额外启动并行服务进程以提供更多的并行服务进程来满足执行的需求。 然后星星协调进程将要处理的对象划分成小数据片,分给并行服务进程处理;并行服务进程处理完毕后将结果发送给并行协调进程,然后由并行协调进程将处理结果汇总并发送给用户。