Ubuntu下eclipse开发hadoop应用程序环境配置
第一步:下载eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
注意:如果电脑是64位,就下载linux下的64位eclipse,不要下载32位的eclipse,不然会无法启动eclipse
第二步:下载最新版本的hadoop插件
重命名:将下载的插件重命名为"hadoop-eclipse-plugin-1.1.1.jar"
将hadoop-eclipse-plugin-1.1.1.jar复制到eclipse/plugins目录下,重启eclipse。
第三步:配置hadoop路径
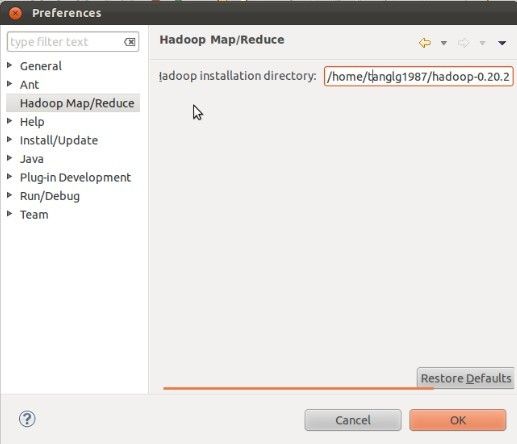
Window-> Preferences选择 “HadoopMap/Reduce”,点击“Browse...”选择Hadoop文件夹的路径。
这个步骤与运行环境无关,只是在新建工程的时候能将hadoop根目录和lib目录下的所有jar包自动导入。
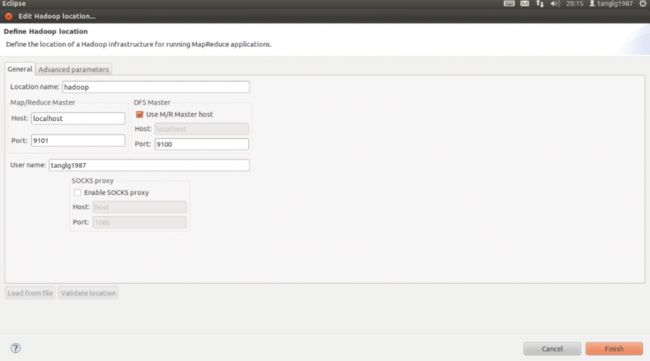
第四步:添加一个MapReduce环境

在eclipse下端,控制台旁边会多一个Tab,叫“Map/ReduceLocations”,在下面空白的地方点右键,选择“NewHadoop location...”,如图所示:
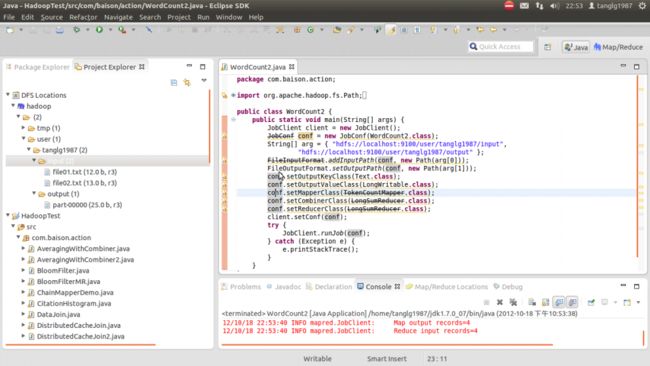
第五步:使用eclipse对HDFS内容进行修改
经过上一步骤,左侧“ProjectExplorer”中应该会出现配置好的HDFS,点击右键,可以进行新建文件夹、删除文件夹、上传文件、下载文件、删除文件等操作。注意:每一次操作完在eclipse中不能马上显示变化,必须得刷新一下。
在hadoop下新建input文件夹,在input目录下新建两个文件file01.txt,file02.txt
file01.txt内容如下:
hello hadoop
file02.txt内容如下:
hello world
上传本地文件到hdfs:(在终端下)
首先创建input
bin/hadoop fs -mkdir /input
上传
hadoopfs -put input/× /input
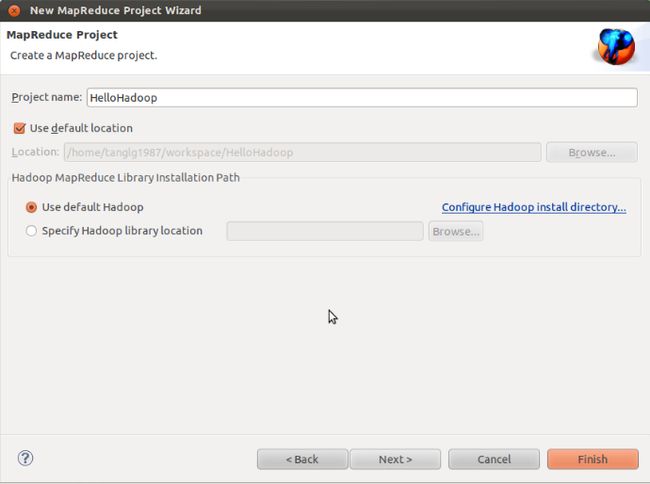
第六步:创建工程
File-> New -> Project选择“Map/ReduceProject”,然后输入项目名称,创建项目。插件会自动把hadoop根目录和lib目录下的所有jar包导入。

第七步:新建一个WordCount.java(注意包名要相同),代码如下:
<span style="font-family:SimHei;font-size:14px;">package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}</span>
第八步:运行WordCount
1.选择Run As-》Run Configurations,将其对话框下的Argument改为如下(main方法的参数传递)
hdfs://localhost:9000/input
hdfs://localhost:9000/output
2.运行之前,删除output文件。Run As -> Run on Hadoop 选择之前配置好的MapReduce运行环境,点击“Finish”运行。
3.
查看运行结果:
在输出目录中,可以看见WordCount程序的输出文件。除此之外,还可以看见一个logs文件夹,里面会有运行的日志。
