snort源码分析
转自 http://hi.baidu.com/freeze9527/blog/item/4cae511ff1debfcca786699d.html|
序:
1 . 包捕获模块 2 . 包解码模块 3 . 预处理模块 4 . 检测模块(模式匹配) 5 . 输出模块 第一部分:包捕获模块 本部分由 snort.c 文件中的 OpenPcap 函数实现。该函数依次调用下图的 libpcap 库中的函数 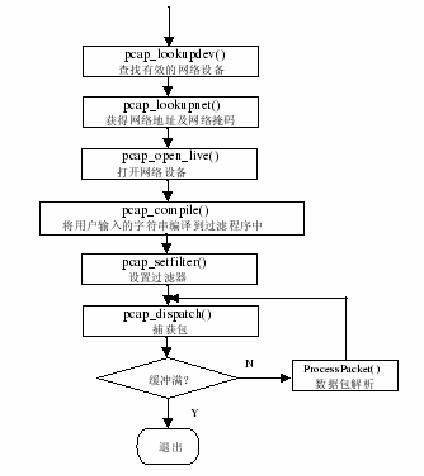 这里需要提醒的是本模块实现的功能实现到 libpcap 库流程的循环抓包前为止,循环抓包是 到 snort.c 主流程的 InterfaceThread 函数中实现。 以下是 libpcap 库各个函数的作用: 1 、 pcap_lookupdev pcap_lookupdev 用来查找系统第一个可以使用的网络适配器,查找成功后, 返回该设备的名称;如果系统有多个网卡,也可以使用 pcap_findalldevs 函数 来查找选取; 2 、 pcap_open_live 函数用于打开指定网络适配器,准备截取数据。其调用形式为: pd = pcap_open_live () /* 以下是参数 */ ( pv.interface, /* 设备名称 */ snaplen, /* 捕获包的长度,通常设置为 65536 ,表示捕获链路层上的所有数据 */ pv.promisc_flag ? PROMISC : 0, /* 网卡是否工作于混杂模式 */ READ_TIMEOUT, /* 超时时间控制,单位毫秒 */ Errorbuf ); /* 出错信息存储 */ 3 、 pcap_open_offline Libpcap 使用库函数 pcap_open_offline 进行脱机方式截获,即先将网络上的 数据截获下来,以文件形式储存到磁盘上,等事后方便时再从磁盘上读取数 据文件来做进一步分析。 4 、 pcap_snapshot 函数用于获取数据链路层协议的类型; 5 、 pcap_compile 和 pcap_setfilter 我们在进行数据包截获时,常常并不需要捕获所有的包,如只需要捕获 ARP 协议等,这就需要过滤规则。 Pcap_compile 用于将设置的过滤字符串编译成 一个过滤器程序。而 pcap_setfilter 则用来设置过滤器的过滤规则; 6 、 pcap_loop 前面的函数都可以看做捕获数据包的准备工作, pcap_loop 用来从网络中捕 获数据包。需要注意的是函数的第三个参数,它是一个回调函数,捕获到的 数据包,就交由它来处理; 第二部分:包解码模块 本模块由 snort.c 文件中的 SetPktProcessor 函数实现。该函数根据 datalink (由上面的 li bpcap 库函数得到)的值来判断并关联解码函数。解码结构如下图:  程序大致结构如下: int SetPktProcessor() { switch(datalink) { case DLT_EN10MB: /* Ethernet */ grinder = DecodeEthPkt; break; case DLT_IEEE802: /* Token Ring */ grinder = DecodeTRPkt; break; /* 以下略 */ } } 其中 grinder 是 snort.c 中的全局的函数指针,其定义如下: typedef void (*grinder_t)(Packet *, struct pcap_pkthdr *, u_char *); /* ptr t o the packet processor */ |
第三部分:预处理模块
Snort 系统在初始化(详见附录一)完成后,在进入检测引擎模块(处理前面两个模块传过
来的网络封包)前,需要对数据包进行预处理。这里请注意 SNORT 所使用的插件的思想, S
nort 的插件结构允许开发者扩展 snort 的功能。
需要再次说明的是,循环抓包是在 snort.c 主流程的 InterfaceThread 函数中实现,该函数
调用 libpcap 库中的 pcap_loop 循环抓包函数,这个函数有个回调函数 ProcessPacket ,这
个回调函数先通过上一个包解码模块得到的相应的解码函数对抓到的数据包进行解码 ( 实现
语句是: (*grinder) (&p, pkthdr, pkt); ) ,下一步判断 snort.c 文件中的 runMode 全局
遍变量,若 SNORT 工作在包记录模式,则调用输出插件 CallLogPlugins 函数;否则工作在
IDS 模式,继而进入预处理 Preprocess 函数。
该预处理函数遍历在初始化预处理插件(详见附录一)后得到的 PreprocessKeywordList 链
表,调用配置文件中要求的预处理插件函数对所抓的数据包进行预处理。函数实现如下:
idx = PreprocessList;
while(idx != NULL)
{
assert(idx->func != NULL);
idx->func(p);
idx = idx->next;
}
预处理器在调用检测引擎之前,在数据包被解码之后运行。通过这种机制, snort 可以以一
种 out of band 的方式对数据包进行修改或者分析。以下是几个常用的预处理插件:
1 . HTTP 解码预处理模块用来处理 HTTP URI 字符串,把它们转换为清晰的 ASCII 字符串。这
样就可以对抗 evasice web URL 扫描程序和能够避开字符串内容分析的恶意攻击者。
2 . frag2 模块 : 使 snort 能够消除 IP 碎片包,给黑客使用 IP 碎片包绕过系统的检测增加了
难度。
3 . stream4 插件为 snort 提供了 TCP 数据包重组的功能。在配置的端口上, stream4 插件能
够对 TCP 数据包的细小片段进行重组成为完整的 TCP 数据包,然后 snort 可以对其可疑行为进
行检查。
4 . Portscan 预处理程序的用处: 向标准记录设备中记录从一个源 IP 地址来的端口扫描的
开始和结束。端口扫描可以是对任一 IP 地址的多个端口,也可以是对多个 IP 地址的同一端
口进行。可以处理分布式的端口扫描(多对一或多对多)。端口扫描也包括单一的秘密扫
描( stealth scan )数据包,比如 NULL , FIN , SYNFIN , XMAS 等。
5 . Portscan2 模块将检测端口扫描。它要求包含 Conversation 预处理器以便判定一个会话
是什么时间开始的。它的目的是能够检测快速扫描,例如,快速的 nmap 扫描。
6 . Conversation 预处理器使 Snort 能够得到关于协议的基本的会话状态而不仅仅是由 s
pp_stream4 处理的 TCP 状态。当它接收到一个你的网络不允许的协议的数据包时,它也能产
生一个报警信息。要做到这一点,请在 IP 协议列表中设置你允许的 IP 协议,并且当它收到
一个不允许的数据包时,它将报警并记录这个数据包。
7 . Http Flow 模块可以忽略 HTTP 头后面的 HTTP 服务响应。
由于 SNORT 的各种预处理模块很有借鉴性,我将在另一章中给出详解。
第四部分 : 检测模块(模式匹配)
SNORT 系统的快速匹配模块有最重要的设计特色,其在初始规则链表的基础上,重新构造了
一套快速匹配的数据结构,并采用了多模式匹配搜索引擎。按其功能可分三个步骤:
1. 构造初始的规则链表结构,由 ParseRule 函数实现。 ( 详见附录三 )
2. 读入规则链表各节点,并构造用快速匹配的新的数据结构,这是在初始化各个插件和建
立三维链表后,在调用处理模块函数 InterfaceThread 前完成的。它是由 fpcreate.c 文件中
的 fpCreateFastPacketDetection 函数完成的。(详见附录四)
3. 对当前数据包执行具体的快速规则匹配任务,主要在 fpEvalPacket() 上。(本模块实现
)
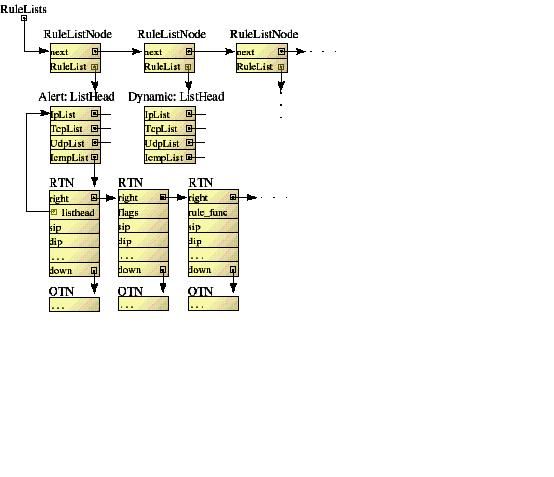
注意现在存在两个链表:一个是 RuleListNode->ListHead->RTN/OTN/OutputFuncNode 链表
,表头是 parser.c 文件中全局变量 RuleLists ;另一个是 PORT_RULE_MAP -> PROT_GROUP -
> RULE_NODE 链表,表头是 fpcreate.c 文件中全局数据结构指针 prmTcpRTNX/prmUdpRTNX/p
rmIcmpRTNX/prmIpRTNX 。
通过第一个链表中 OTN 的规则内容建立第二个链表。
在 Preprocess 函数中,在处理完预处理模块后,调用 Detect 函数对捕获的 packet 结构类型
参数的数据包内容进行特征规则匹配。该函数调用 fpEvalPacket 函数,进而根据捕获数据
包的协议类型判断 Tcp/Udp/Icmp 协议,若不能规为这三种协议的就算作 Ip 协议,然后调用
相应的处理函数。以 Tcp 协议为例,调用 fpEvalHeaderTcp 函数。
下面以 fpEvalHeaderTcp 函数源码为例解析:
static INLINE int fpEvalHeaderTcp(Packet *p)
{
/* 根据给定参数的源端口和目的端口决定应根据哪个 PORT_RULE_MAP->PORT_GROUP*/
/* 结构进行匹配 ( 该链表的建立参照附录四 ) */
prmFindRuleGroupTcp(p->dp, p->sp, &src, &dst, &gen);
/* 遍历 Tcp 类型的 PORT_RULE_MAP->PORT_GROUP 链表进行 http_decode 模式特征匹配 */
fpEvalHeaderSW(dst, p, 1) ;
}
继续对 fpEvalHeaderSW 函数进行解析。该函数遍历 PORT_RULE_MAP->PORT_GROUP 链表,进
行 uri-conetnt/content/non-conetnt 匹配:
int fpEvalHeaderSW(PORT_GROUP *port_group, Packet *p, int check_ports)
{
/* 循环 HttpUri 类型全局指针数组 UriBufs[URI_COUNT] */
for( i=0; i<p->uri_count; i++)
{
/* 以下分别进行 uri-conetnt/content/non-conetnt 匹配,仅以 content 为例 */
stat = mpseSearch ( so, p->data, p->dsize, otnx_match, &omd );
fpLogEvent(otnx->rtn, otnx->otn, p);
}
}
下面对以上各函数分别解析:
1 . mpseSearch 函数:
SNORT 提供三种完全不同的模式匹配算法: Aho-Corasick/Wu-Manber/Boyer-Moore ,默认
使用第三种。注意 mpseSearch 函数中有两个参数分别是: 所要匹配的数据包指针 (Packet
*) 和先前为了快速匹配特征串而建立的对应的结构指针( PORT_RULE_MAP->PORT_GROUP* )
,后面的所调用的函数参数都是从这两个参数中得到。
mpseSearch 函数调用 mwmSearch ,继续调用 mwmSearch ,继续调用 hbm_match 函数。这个函数
即是用 Boyer-Moore-Horspool 模式匹配算法进行特征匹配。具体算法实现请参照 msting.c
文件。
2 . fpLogEvent 函数:
若匹配成功,则调用本函数记录或报警。该函数的参数分别是:匹配的 RTN/ONT 指针和数据
包指针 (Packet*) ,具体实现如下:
switch(rtn->type)
{
case RULE_PASS: PassAction();
case RULE_ACTIVATE: ActivateAction(p, otn, &otn->event_data);
case RULE_ALERT: AlertAction(p, otn, &otn->event_data);
case RULE_DYNAMIC: DynamicAction(p, otn, &otn->event_data);
case RULE_LOG: LogAction(p, otn, &otn->event_data);
}
若是应用 pass 规则动作,则仅设置通过包的数目加一;
若是 dynamic/log 规则动作,则调用 detect.c 文件中的 CallLogFuncs 函数进行记录;
若是 activate/alert 规则动作,则调用 detect.c 文件中的 CallAlertFuncs 函数进行报警。
|
附录一:初始化插件函数 |

附录四:初始化快速包检测引擎
由fpCreateFastPacketDetection函数实现,该函数遍历RuleListNode->ListHead->RTN/O
TN类型的链表(如:rule->RuleList->TcpList),在此每一条规则根据其内容(Content/
UriContent/NoContent)被分类,内容信息存储在OTN中:在OTN中有一项指针数组ds_list
,指向不同的根据规则设置的数据结构。
根据每一条规则的ds_list内容类型分别调用prmAddRule/prmAddRuleUri/prmAddRuleNC函
数。fpCreateFastPacketDetection函数根据各条规则中给出的源端口和目的端口把规则排
序加入到合适的 PORT_RULE_MAP -> PROT_GROUP -> RULE_NODE链表中。这样做的目的是为
了能够快速和捕获包进行特征匹配。下图是用到的数据结构:

我们在fpcreate.c文件中定义了四个PORT_RULE_MAP类型的全局数据结构指针prmTcpRTNX/
prmUdpRTNX/prmIcmpRTNX/prmIpRTNX,该结构主要包含三个PORT_GROUP类型的结构的指针
数组表:prmSrcPort[MAX_PORTS]/prmDstPort[MAX_PROTS]/prmGeneric,其中MAX_PORTS对
应端口号0到65535,prmGeneric通用表被用作源端口和目的端口都为ANY的情况。
SNORT系统快速匹配规则引擎的设计思想是如何更有效地划分规则集合具体实现是通过规则
中的目的端口和源断口值来划分类别。
1。 如果源端口值为特定值,目的端口为任意值(ANY),则该规则加入到源端口值对应的子
集合中。如果目的端口的值为特定值,则该规则同时加入到目的端口对应的子集合中。
2。 如果源端口值为特定值,目的端口为任意值(ANY),则该规则加入到源端口值对应的子
集合中。如果目的端口的值也为任意值(ANY),则该规则同时加入到目的端口对应的子集合
中。
3。 如果目的端口和源端口都为任意值(ANY),则该规则加入到通用子集合中。
4。 对于规则中端口值求反操作或者指定值范围的情况,等于端口值为ANY情况。
以下是源码解析:
int fpCreateFastPacketDetection()
{
/* 以TCP为例 */
/* 遍历 RuleListNode->ListHead->RTN->OTN 链表 */
if(rule->RuleList->TcpList) {
for(rtn = rule->RuleList->TcpList; rtn != NULL; rtn = rtn->right){
for( otn = rtn->down; otn; otn=otn->next ) {
/* 以下把Content、UriContent、NoContent 加入到端口规则映射表 */
if( OtnHasContent( otn ) )
prmAddRule(prmTcpRTNX, dport, sport, otnx);
if( OtnHasUriContent( otn ) )
prmAddRuleUri(prmTcpRTNX, dport, sport, otnx);
if( !OtnHasContent( otn ) && !OtnHasUriContent( otn ) )
prmAddRuleNC(prmTcpRTNX, sport, dport, otnx);
prmCompileGroups(prmTcpRTNX);
BuildMultiPatternGroups(prmTcpRTNX);
}
下面分别对prmAddRule/ prmCompileGroups/ BuildMultiPatternGroups三个函数分别解析
:
1。以OtnHasContent为例:调用prmAddRule函数,该函数根据源端口和目的端口来判断,
把OTNX中相应的信息加入到对应的PORT_RULE_MAP结构中。
int prmAddRule( PORT_RULE_MAP * p, int dport, int sport, RULE_PTR rd )
{
/* 若根据目的端口(0 -> 65535)来汇聚信息 */
if( dport != ANYPORT && dport < MAX_PORTS )
prmxAddPortRule( p->prmDstPort[ dport ], rd );
/* 若根据目的端口(0 -> 65535)来汇聚信息 */
if( sport != ANYPORT && sport < MAX_PORTS)
prmxAddPortRule( p->prmSrcPort[ sport ], rd );
/* generic(-1)指本规则可应用于任何值 */
if( sport == ANYPORT && dport == ANYPORT) //ANYPORT==-1
prmxAddPortRule( p->prmGeneric, rd );
}
继续调用prmxAddPortRule函数最终把RULE_NODE节点加入到PORT_GROUP形成规则内容链表
:
static int prmxAddPortRule( PORT_GROUP *p, RULE_PTR rd )
{
p->pgTail->rnNext = (RULE_NODE*)malloc( sizeof(RULE_NODE) );
p->pgTail = p->pgTail->rnNext;
p->pgTail->rnNext = 0;
p->pgTail->rnRuleData = rd;
}
需要注意的是:RULE_PTR类型的结构定义是typedef void * RULE_PTR,其实就对应的OTN
X结构类型的数据——这是从RuleListNode->ListHead->RTN/OTN传过来的规则内容数据。
2。fpCreateFastPacketDetection函数再调用prmCompileGroups函数。
对于通用规则节点链表而言,在构建快速规则匹配引擎中,它仅是作为一个过渡性的函数
结构。对于未来的规则检测任务而言,每个数据包都有特定的源/目的端口值。
为了达成根据端口进行快速规则匹配的任务,函数fpCreateFastPacketDetection在完成遍
历操作后,对各个 PORT_RULE_MAP结构中的通用规则链表进行了进一步处理,调用prmCom
pileGroups函数。该函数功能将通用规则链表中的各个规则节点加入到另外对应于特定端
口值的两个规则链表中,前提条件是目标规则链表中已经存在节点,既在Port_Rule_Map结
构中的Port_Group数组中每个非空元素中加入。
3。最后为适应多模式引擎算法,fpCreateFastPacketDetection再调用BuildMultiPatern
Groups()在每个Port_Group结构中构建多模式搜索引擎所需的数据结构。
函数fpCreateFastPacketDetection在完成规则链表的遍历操作后,既完成了各个规则子集
合的划分,所有的规则节点都已经加入了如下三种类型之一的子集合里:
1。对应于特定源端口值的PORT_GROUP结构的规则链表
2。对应于特定目的端口值的PORT_GROUP结构的规则链表
3。通用一般的规则节点链表
总结:
可以把SNORT功能实现分成两大块:一是SNORT系统的初始化,二是在SNORT系统功能框架建
立起来后,抓包并进行模式匹配。
初始化分两步:第一步把所有的三类插件(output/preprocess/plugins)串成三个链表(
OutputKeywordList/PreprocessKeywordList/KeywordXlateList)以供下一步调用;第二
步是读取配置文件,并从上一步中插件链表中挑出配置文件中相应的要用到的插件建立Ru
leListNode->ListHead->RTN/OTN/OutputFuncNode,这其中的RTN/OTN链表构成SNORT的有
特色的三维链表,供模式匹配用。
第二步:模式匹配。分两步:第一步,在模式匹配初始化时另外建立一个PORT_RULE_MAP
-> PROT_GROUP -> RULE_NODE链表以供快速匹配用;第二步循环抓包并用Boyer-Moore -H
orspool算法匹配。
1. 包捕获模块
2. 包解码模块
3. 预处理模块
4. 检测模块(模式匹配)
5. 输出模块
