MapReduce Design Patterns-chapter 4
CHAPTER 4:Data Organization Patterns
Structured to Hierarchical
Problem: Given a list of posts and comments, create a structured XML hierarchy to nest comments with their related post.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "PostCommentHierarchy");
job.setJarByClass(PostCommentBuildingDriver.class);
MultipleInputs.addInputPath(job, new Path(args[0]),
TextInputFormat.class, PostMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),
TextInputFormat.class, CommentMapper.class);
job.setReducerClass(UserJoinReducer.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 2);
} map中用PostId为key,value前缀为P是Post,前缀为C是comment
public static class PostMapper extends Mapper<Object, Text, Text, Text> {
private Text outkey = new Text();
private Text outvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
// The foreign join key is the post ID
outkey.set(parsed.get("Id"));
// Flag this record for the reducer and then output
outvalue.set("P" + value.toString());
context.write(outkey, outvalue);
}
}
public static class CommentMapper extends Mapper<Object, Text, Text, Text> {
private Text outkey = new Text();
private Text outvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
// The foreign join key is the post ID
outkey.set(parsed.get("PostId"));
// Flag this record for the reducer and then output
outvalue.set("C" + value.toString());
context.write(outkey, outvalue);
}
}
public static class PostCommentHierarchyReducer extends
Reducer<Text, Text, Text, NullWritable> {
private ArrayList<String> comments = new ArrayList<String>();
private DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
private String post = null;
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// Reset variables
post = null;
comments.clear();
// For each input value
for (Text t : values) {
// If this is the post record, store it, minus the flag
if (t.charAt(0) == 'P') {
post = t.toString().substring(1, t.toString().length())
.trim();
} else {
// Else, it is a comment record. Add it to the list, minus
// the flag
comments.add(t.toString()
.substring(1, t.toString().length()).trim());
}
}
// If there are no comments, the comments list will simply be empty.
// If post is not null, combine post with its comments.
if (post != null) {
// nest the comments underneath the post element
String postWithCommentChildren = nestElements(post, comments);
// write out the XML
context.write(new Text(postWithCommentChildren),
NullWritable.get());
}
}
...
private String nestElements(String post, List<String> comments) {
// Create the new document to build the XML
DocumentBuilder bldr = dbf.newDocumentBuilder();
Document doc = bldr.newDocument();
// Copy parent node to document
Element postEl = getXmlElementFromString(post);
Element toAddPostEl = doc.createElement("post");
// Copy the attributes of the original post element to the new one
copyAttributesToElement(postEl.getAttributes(), toAddPostEl);
// For each comment, copy it to the "post" node
for (String commentXml : comments) {
Element commentEl = getXmlElementFromString(commentXml);
Element toAddCommentEl = doc.createElement("comments");
// Copy the attributes of the original comment element to
// the new one
copyAttributesToElement(commentEl.getAttributes(),
toAddCommentEl);
// Add the copied comment to the post element
toAddPostEl.appendChild(toAddCommentEl);
}
// Add the post element to the document
doc.appendChild(toAddPostEl);
// Transform the document into a String of XML and return
return transformDocumentToString(doc);
}
private Element getXmlElementFromString(String xml) {
// Create a new document builder
DocumentBuilder bldr = dbf.newDocumentBuilder();
return bldr.parse(new InputSource(new StringReader(xml)))
.getDocumentElement();
}
private void copyAttributesToElement(NamedNodeMap attributes,
Element element) {
// For each attribute, copy it to the element
for (int i = 0; i < attributes.getLength(); ++i) {
Attr toCopy = (Attr) attributes.item(i);
element.setAttribute(toCopy.getName(), toCopy.getValue());
}
}
private String transformDocumentToString(Document doc) {
TransformerFactory tf = TransformerFactory.newInstance();
Transformer transformer = tf.newTransformer();
transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION,
"yes");
StringWriter writer = new StringWriter();
transformer.transform(new DOMSource(doc), new StreamResult(
writer));
// Replace all new line characters with an empty string to have
// one record per line.
return writer.getBuffer().toString().replaceAll("\n|\r", "");
}
}
Partitioning
Problem: Given a set of user information, partition the records based on the year of last.access date, one partition per year.
Driver Code
... // Set custom partitioner and min last access date job.setPartitionerClass(LastAccessDatePartitioner.class); LastAccessDatePartitioner.setMinLastAccessDate(job, 2008); // Last access dates span between 2008-2011, or 4 years job.setNumReduceTasks(4); ...
public static class LastAccessDateMapper extends
Mapper<Object, Text, IntWritable, Text> {
// This object will format the creation date string into a Date object
private final static SimpleDateFormat frmt = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS");
private IntWritable outkey = new IntWritable();
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
// Grab the last access date
String strDate = parsed.get("LastAccessDate");
// Parse the string into a Calendar object
Calendar cal = Calendar.getInstance();
cal.setTime(frmt.parse(strDate));
outkey.set(cal.get(Calendar.YEAR));
// Write out the year with the input value
context.write(outkey, value);
}
}
Partitioner code.
public static class LastAccessDatePartitioner extends
Partitioner<IntWritable, Text> implements Configurable {
private static final String MIN_LAST_ACCESS_DATE_YEAR =
"min.last.access.date.year";
private Configuration conf = null;
private int minLastAccessDateYear = 0;
public int getPartition(IntWritable key, Text value, int numPartitions) {
return key.get() - minLastAccessDateYear;
}
public Configuration getConf() {
return conf;
}
public void setConf(Configuration conf) {
this.conf = conf;
minLastAccessDateYear = conf.getInt(MIN_LAST_ACCESS_DATE_YEAR, 0);
}
public static void setMinLastAccessDate(Job job,
int minLastAccessDateYear) {
job.getConfiguration().setInt(MIN_LAST_ACCESS_DATE_YEAR,
minLastAccessDateYear);
}
}
Reducer code.
public static class ValueReducer extends
Reducer<IntWritable, Text, Text, NullWritable> {
protected void reduce(IntWritable key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
for (Text t : values) {
context.write(t, NullWritable.get());
}
}
}
Binning
The major difference is in how the bins or partitions are built using the MapReduce framework.
Binning splits data up in the map phase instead of in the partitioner. This has the major advantage of eliminating the need for a reduce phase, usually leading to more efficient resource allocation. The downside is that each mapper will now have one file per possible output bin.
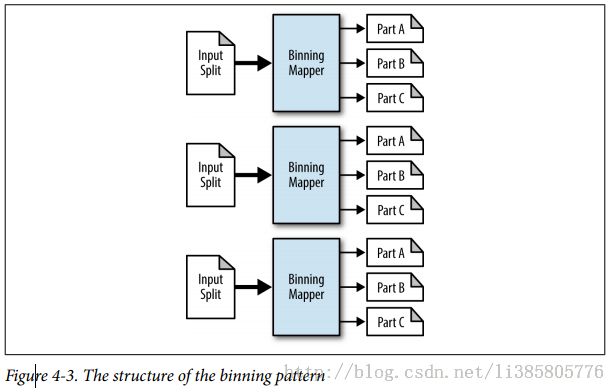
Data should not be left as a bunch of tiny files. At some point, you should run some postprocessing that collects the outputs into larger files.
Problem: Given a set of StackOverflow posts, bin the posts into four bins based on the tags hadoop, pig, hive, and hbase. Also, create a separate bin for posts mentioning hadoop in the text or title.
Driver Code:
...
// Configure the MultipleOutputs by adding an output called "bins"
// With the proper output format and mapper key/value pairs
MultipleOutputs.addNamedOutput(job, "bins", TextOutputFormat.class,
Text.class, NullWritable.class);
// Enable the counters for the job
// If there are a significant number of different named outputs, this
// should be disabled
MultipleOutputs.setCountersEnabled(job, true);
// Map-only job
job.setNumReduceTasks(0);
... Mapper code:
public static class BinningMapper extends
Mapper<Object, Text, Text, NullWritable> {
private MultipleOutputs<Text, NullWritable> mos = null;
protected void setup(Context context) {
// Create a new MultipleOutputs using the context object
mos = new MultipleOutputs(context);
}
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
String rawtags = parsed.get("Tags");
// Tags are delimited by ><. i.e. <tag1><tag2><tag3>
String[] tagTokens = StringEscapeUtils.unescapeHtml(rawtags).split(
"><");
// For each tag
for (String tag : tagTokens) {
// Remove any > or < from the token
String groomed = tag.replaceAll(">|<", "").toLowerCase();
// If this tag is one of the following, write to the named bin
if (groomed.equalsIgnoreCase("hadoop")) {
mos.write("bins", value, NullWritable.get(), "hadoop-tag");
}
if (groomed.equalsIgnoreCase("pig")) {
mos.write("bins", value, NullWritable.get(), "pig-tag");
}
if (groomed.equalsIgnoreCase("hive")) {
mos.write("bins", value, NullWritable.get(), "hive-tag");
}
if (groomed.equalsIgnoreCase("hbase")) {
mos.write("bins", value, NullWritable.get(), "hbase-tag");
}
}
// Get the body of the post
String post = parsed.get("Body");
// If the post contains the word "hadoop", write it to its own bin
if (post.toLowerCase().contains("hadoop")) {
mos.write("bins", value, NullWritable.get(), "hadoop-post");
}
}
protected void cleanup(Context context) throws IOException,
InterruptedException {
// Close multiple outputs!
mos.close();
}
}
addNamedOutput
public static void addNamedOutput(Job job,
String namedOutput,
Class<? extends OutputFormat> outputFormatClass,
Class<?> keyClass,
Class<?> valueClass)
- Adds a named output for the job.
-
- Parameters:
-
job- job to add the named output -
namedOutput- named output name, it has to be a word, letters and numbers only, cannot be the word 'part' as that is reserved for the default output. -
outputFormatClass- OutputFormat class. -
keyClass- key class -
valueClass- value class
write
public <K,V> void write(String namedOutput,
K key,
V value,
String baseOutputPath)
throws IOException,
InterruptedException
- Write key and value to baseOutputPath using the namedOutput.
-
- Parameters:
-
namedOutput- the named output name -
key- the key -
value- the value -
baseOutputPath- base-output path to write the record to. Note: Framework will generate unique filename for the baseOutputPath - Throws:
-
IOException -
InterruptedException
Total Order Sorting
Shuffling
Problem: Given a large data set of StackOverflow comments, anonymize each comment by removing IDs, removing the time from the record, and then randomly shuffling the records within the data set.
public static class AnonymizeMapper extends
Mapper<Object, Text, IntWritable, Text> {
private IntWritable outkey = new IntWritable();
private Random rndm = new Random();
private Text outvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
if (parsed.size() > 0) {
StringBuilder bldr = new StringBuilder();
// Create the start of the record
bldr.append("<row ");
// For each XML attribute
for (Entry<String, String> entry : parsed.entrySet()) {
// If it is a user ID or row ID, ignore it
if (entry.getKey().equals("UserId")
|| entry.getKey().equals("Id")) {
} else if (entry.getKey().equals("CreationDate")) {
// If it is a CreationDate, remove the time from the date
// i.e., anything after the 'T' in the value
bldr.append(entry.getKey()
+ "=\""
+ entry.getValue().substring(0,
entry.getValue().indexOf('T')) + "\" ");
} else {
// Otherwise, output the attribute and value as is
bldr.append(entry.getKey() + "=\"" + entry.getValue()
+ "\" ");
}
}
// Add the /> to finish the record
bldr.append("/>");
// Set the sort key to a random value and output
outkey.set(rndm.nextInt());
outvalue.set(bldr.toString());
context.write(outkey, outvalue);
}
}
}
public static class ValueReducer extends
Reducer<IntWritable, Text, Text, NullWritable> {
protected void reduce(IntWritable key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
for (Text t : values) {
context.write(t, NullWritable.get());
}
}
}