高性能复杂事件处理---模式匹配
原论文:High-PerformanceComplex Event Processing over Streams
本篇论文的算法是基于SASE语言。对该语言不作详细介绍,这里只描述模式匹配的算法。
1. 基于查询计划的方法
1.1 基本查询计划
SASE中的查询计划由6个操作符的某个子集组成:
Ø 序列扫描(sequencescan)
Ø 序列构造(sequenceconstruction)
Ø 选择(selection)
Ø 窗口(window)
Ø 否定(negation)
Ø 转换(transformation)
考虑一个具体的例子,查询Q3:
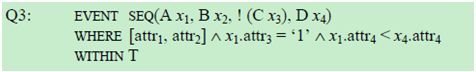
在该查询中,A、B、C、D表示四种不同的事件类型。WHERE子句包含了3个谓词:(1)两个等值测试,attr1和attr2是A、B、C、D 共有的属性;(2)A类型事件属性attr3的一个简单谓词;(3)比较A和B类型事件的attr4属性的谓词。大写字母T表示指定的窗口大小。
图1显示了Q3的基本查询计划和一个事件流的例子。
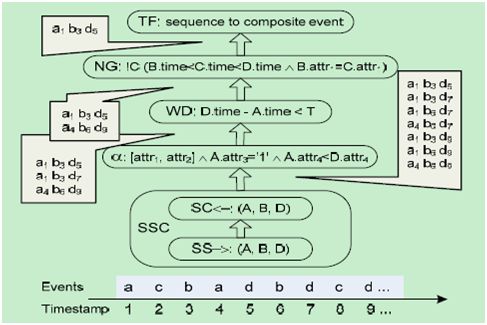
图1 查询Q3的执行计划
在图1下方的事件流中,小写字母表示事件,对应的大写字母表示事件类型,每个事件底下的数字是事件的时间戳。圆角矩形表示查询计划中的操作符,从下往上,它们依次是:
序列扫描和构造(Sequence Scan and Construction,简写为SSC)
序列扫描和序列构造总是一起使用。对于使用了SEQ结构的查询来说,SSC处理SEQ的正组件,这些正组件组成了原SEQ中一个“子序列类型”。例如,Q3的子序列类型是(A,B,D),其中删除了“!C”。
SSC把事件流转换进入一个事件流序列中;每个事件序列表示唯一的SSC子序列类型匹配。在图1中,SSC的输出创建了7个事件序列。
SSC包含序列扫描操作符(SS->),它扫描事件流,检测子序列类型中对应的匹配序列;还包含序列构造操作符(SC<-),用来创建所有的事件序列。之后会详细介绍它们。
选择(Selection)
选择操作符通过使用所有的谓词,过滤每个事件序列,将满足条件的序列输出。图1中,选择操作符过滤出了7个输入事件序列中的3个。
窗口(Window)
窗口操作符把WITHIN子句的限制条件加到了模式匹配中。对于每个事件序列,它检查第一个和最后一个事件的时间戳的差值是否小于窗口大小T。在图1中,T的值是6,结果第二个输入事件序列被过滤掉了。
否定(Negation)
否定操作符处理SEQ结构中的负组件,就是被SSC忽略的组件。在图1中,对于每个输入的事件序列,否定操作符检查在序列中b和d事件的中间是否存在c事件,且c的属性与b的相同(同样,这个属性也与a和d的相同)。如果这样的c存在,事件序列就被删除。在图1中,第二个输入事件序列被过滤掉了。
转换(Transformation)
最后,转换操作符通过把输入序列中所有事件的属性连接在一起,从而把每个事件序列转换成一个组合事件。
在余下的部分,我们详细阐述SSC和否定操作符的实现。
1.2 序列扫描和构造
序列扫描(SS->)
对于每个SSC子序列类型,通过把连续的事件类型映射到连续的NFA状态上,进而创建一个NFA。例如,图2展示了由子序列类型(A,B,D)创建的NFA,状态0是起始状态。状态1是识别出A事件之后的状态,状态2是识别出事件B之后的状态,状态3是识别出事件D之后的状态。状态3用两层圆圈画出,表示它是NFA的“接受状态(即最终状态)”(此状态只有一个)。注意状态1和状态2包含了带有通配符“*”的循环箭头。给定一个事件,这种状态允许NFA在该状态上循环转换,当然,也可以同时向后一个状态转换。
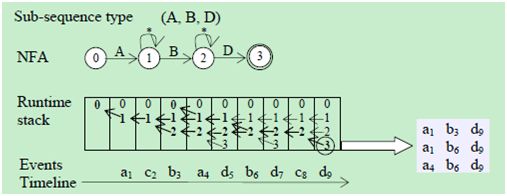
图2 基于NFA的序列扫描和构造
为了跟踪这些同时发生的状态,我们使用运行时栈来记录在特定时间点上产生的活动的状态集合,并记录当一个事件到达时,这个集合怎样导致了一个新的活动状态集合的产生。图2展示了运行时栈(从左到右)的变化,图的下方是事件流。栈中每个活动状态实例有一个或两个前向指针,这个指针指向该状态来自于哪个状态。每当有a事件到达时,状态0就要被激活,用以初始化一次新的搜索。
序列构造(SC<-)
在序列扫描期间,一旦到达接受状态,就会调用序列构造来创建事件序列。序列构造的一种方法是从运行时栈中提取出一个单源的有向无环图(Directed Acyclic Graph,DAG),这个图从栈最右侧单元的接受状态开始,沿着前向指针遍历,直到到达了起始状态。在图2中,粗体数字和箭头标识出了这样的DAG,这个图是当到达时产生的。通过枚举从DAG的源点到终点的所有可能路径,就能得到事件序列。对于每条路径,连接相同状态的两个实例的边(也就是“自循环边”)被删除了;剩下的边产生了唯一的事件序列。图2展示了由DAG创建的三个事件序列。
一个搜索DAG的简单算法的复杂度是O(P)。P是DAG中路径的数量,最坏的情况将是指数级的。我们使用深度优先搜索来进行改善,其复杂度是O(E),E是DAG中边的数量。因为每个活动状态实例有至多两个指针,E的上限是O(2LS),L是子序列类型的长度(即NFA中状态的数量),S是事件的数量。实际上,S可以被设置为窗口大小W,这样就要在DAG的搜索中动态检查窗口的条件限制,因此复杂度就是O(2LW)。
1.3 否定
如前所述,否定操作符(NG)处理SEQ 结构中被SSC忽略的负组件。对于每个输入事件序列,NG对每个负组件执行两个任务:(1)检查负组件中指定的事件是否出现在特定的时间段中;(2)如果这样的事件存在,检查它是否满足所有的相关谓词。通过了这两个检查的任意事件,都会把当前事件序列标识为False。在以下部分,我们关注于对任务(1)的编辑时和运行时的支持。对于任务(2)的支持是直观的,我们不再进一步讨论。
在编辑时,任务(1)的时间段按如下方式产生:对于序列(A,!B,C),时间段定义为(A.timestamp, C.timestamp);对于序列(!A,B),使用窗口大小T来定义时间段(B.timestamp-T,B.timestamp);对于序列(A,!B)的处理有些特殊,给定窗口大小T,查询不允许a事件之后的T时间内出现b事件,那么时间段就是(A.timestamp, A.timestamp+T)。
2. 优化技术
2.1 优化序列扫描和构造
当使用的窗口很大时,我们前面描述的算法是极其低效的。为此,我们使用一种辅助数据结构,Active Instance Stack(AIS),来促进序列构造。算法描述如下。
序列扫描
在序列扫描中,NFA的执行方式与之前相同。除此之外,在每个NFA状态处创建一个AIS,用来存储触发了转换到当前状态的事件;这样的事件就是当前状态的活动实例(active instance)。对应于图2,图3展示了三个AIS的内容。在每个栈中,从上到下,活动实例(粗体字标识)表示了它们当时出现的顺序。从左到右,在两个相邻的栈之间,我们使用每个活动实例e的一个额外字段,其中存储的是当e到达时“前一个栈中最近的实例(most recent instance in the previous stack, 简写为RIP)”。以B栈中活动实例为例,在A栈中位于之前的最近的实例是,所以的RIP字段设置为。RIP字段的意思是,如果与有关的序列需要被创建时,那么在A栈中出现在之前的任何实例(也就是)都要与作匹配。
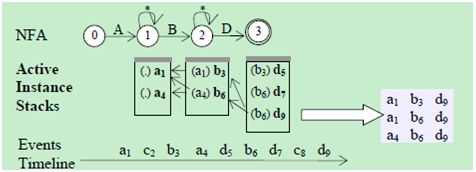
图3 使用AIS的SSC
序列构造
这个方法中不需要使用指针记录路径,图中的箭头只是为了方便查看路径。当从开始搜索时,因为的RIP字段是,所以要匹配前一个栈中出现在之前的所有b事件,也就是和。
2.2 向下推进谓词
为了减小中间结果集的大小,我们将谓词的条件判断放到SSC中。
2.2.1 把一个等值测试放到SSC中
等值测试实际上起到了“分组”的作用。一个等值测试会把一个大的事件流分成多个小的事件流;每个分组中事件具有相同的属性值。一个直观的解决方案是,先把事件流分组,然后对每个分组执行查询计划。为了获得更好的性能,我们使用一种高级的技术,称为PAIS(Partitioned Active Instance Stack),它有两个优点:(1)同时创建多个分组,在序列扫描阶段为每个分组创建一个AIS序列;(2)不会对那些与查询无关的事件类型产生额外开销(也就是分组的开销)。
PAIS的基本思想是,在每个状态中,基于等值测试的属性对活动实例(Active Instance)分组,在同一个分组中创建一个AIS。并且,一个状态的栈必须与相同分组中前一个状态中栈连接(使用2.1节的算法)。图4展示了这样一个例子。放到SSC中的等值测试基于属性。每个事件的属性值显示在图4下方。
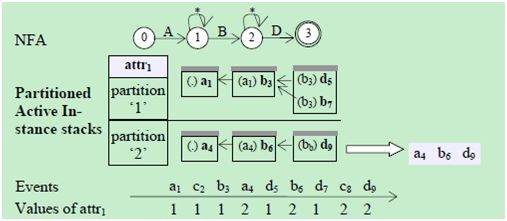
图4 PAIS
PAIS算法对AIS算法进行了两点修改:
1) 基于属性的转换过滤:在任意一个非起始状态中,当NFA决定对当前事件作转换时(例如,从状态1对进行转换),PAIS从当前事件中取得等值测试的属性值(从中取得’2’),然后检查当前状态的相应分组(状态1的分组’2’)的AIS是否为空。如果AIS是非空的,就说明具有相等属性值的前一个事件存在,所以转换到新的状态是必要的;否则(状态1的分组2的AIS是空的),就把当前事件丢弃。
2) 栈的维护:一旦作出转换,当前事件就被添加到新状态的AIS中(被添加到状态2的分组2的栈里),它的RIP字段被设置为前一个状态的对应的分组中的最后一个实例(的RIP字段设为)。
使用PAIS,只需要在同一个分组的栈中执行序列构造,因此产生的结果数量将大大减少。在图4中,为执行序列构造只产生了一个事件序列,而之前的方法产生了三个。
2.2.2 把多个等值测试放到SSC中
查询中可以包含多个等会测试,如果等值测试被放到SSC中,那么中间结果的数量可以进一步减少。对PAIS算法的扩展是创建多个属性分组,并为每个分组创建一个AIS序列。这里,我们提出两种可选的方法。
2.2.2.1 Eager Filtering in SS->
第一种方法称为Multi-PAIS,把所有的等值测试放到序列扫描中,目的是为了在PAIS算法的“转换过滤”阶段过滤掉更多的事件。我们考虑一个简单的子序列类型(A, B)和两个等值测试属性和。图5展示了这个例子。
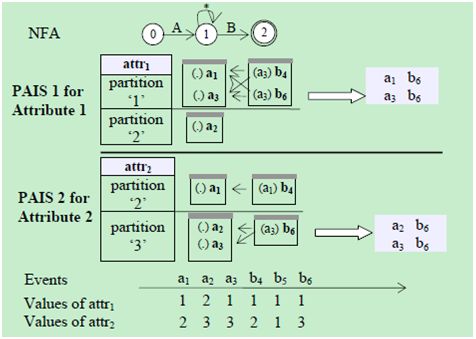
图5 多分组AIS(Multi-PAIS)
在每个NFA状态中,是针对一个属性创建的一个PAIS。为了理解这些栈里的内容,我们描述一下栈是如何构造的:
1) 交叉属性的转换过滤:在每个非起始状态,当NFA决定对当前事件作转换时(例如,从状态1对进行转换),分两步进行:
(1)对于每个属性,找到当前状态的(状态1对应的),根据属性值取得相应的栈(, );
(2)对所有的求交集(结果是)。
如果交集是非空的,就说明存在一个之前的事件与当前事件的所有测试的属性值都相等。
2) 多栈的维护:在转换之后的新状态中,根据当前事件的值,把它添加到的合适的栈中。例如,在状态2中,被添加到的分组’1’的栈中,同时也被添加到的分组’3’的栈中。
当对执行序列构造时,在中都会得到两个事件序列,尽管最终只有一个正确的结果序列。于是,选择操作符还需要进一步过滤掉其余3个序列。
2.2.2.2 Dynamic Filtering in SC<-
第二种方法称为DynamicFiltering,把一个等值测试放到序列扫描中,把其他等值测试放到序列构造中。当在AIS中搜索DAG时,再执行其他的等值测试。与Multi-PAIS相比,Dynamic Filtering不会在序列扫描中过滤掉很多的事件,因此在栈中存在更多的实例,但是它不需要在“交叉属性的转换过滤”和“多栈的维护”上产生开销。
SASE也可以把简单谓词(应用于单个事件的谓词,如)放到序列扫描中。
2.3 优化后的查询计划
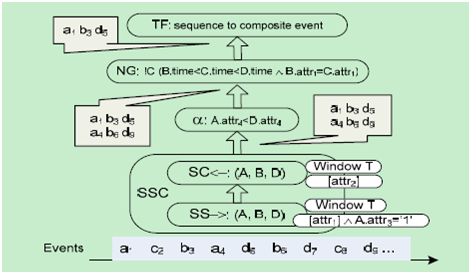
图6 优化后的查询计划
图6是采用了优化技术之后的查询计划,它与基本的查询计划相比,具有以下不同点:
Ø 窗口操作符被放到了SS->和SC<-中;
Ø 关于的等值测试被放到了SS->中;
Ø 简单谓词被放到了SS->中;
Ø 关于的等值测试被放到了SC<-中。
另外,图6也展示了一个事件流,优化后的查询计划只产生两个事件序列(基本查询计划产生7个),所以中间结果的数量大幅度减少了。