ARM NEON 指令
在初学NDK时,接触到 HelloNeon例程,了解到 Neon是ARMv7-AR 系列中引入的并行模块,可以让你同时操作8个16位数据或4个32位数据,在信号处理,图像处理,视频编解码优化方面有很高的应用价值。在本文中罗列一些信息,供以后参考。
NEON 汇编指令一览
http://infocenter.arm.com/help/basic/help.jsp?topic=/com.arm.doc.dui0204ic/CJAJIIGG.html
ARM 体系结构参考手册 ARMv7-A 和 ARMv7-R 版
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0406c/index.htmlHelloNeon中FIR滤波器的C语言实现
/* this is a FIR filter implemented in C */
static void
fir_filter_c(short *output, const short* input, const short* kernel, int width, int kernelSize)
{
int offset = -kernelSize/2;
int nn;
for (nn = 0; nn < width; nn++) {
int sum = 0;
int mm;
for (mm = 0; mm < kernelSize; mm++) {
sum += kernel[mm]*input[nn+offset+mm];
}
output[nn] = (short)((sum + 0x8000) >> 16);
}
}HelloNeon中FIR滤波器的Neon实现 (在调用前需要确定芯片支持NEON指令,具体见例程)
void
fir_filter_neon_intrinsics(short *output, const short* input, const short* kernel, int width, int kernelSize)
{
int nn, offset = -kernelSize/2;
for (nn = 0; nn < width; nn++)
{
int mm, sum = 0;
int32x4_t sum_vec = vdupq_n_s32(0);
for(mm = 0; mm < kernelSize/4; mm++)
{
int16x4_t kernel_vec = vld1_s16(kernel + mm*4);
int16x4_t input_vec = vld1_s16(input + (nn+offset+mm*4));
sum_vec = vmlal_s16(sum_vec, kernel_vec, input_vec);
}
sum += vgetq_lane_s32(sum_vec, 0);
sum += vgetq_lane_s32(sum_vec, 1);
sum += vgetq_lane_s32(sum_vec, 2);
sum += vgetq_lane_s32(sum_vec, 3);
if(kernelSize & 3)
{
for(mm = kernelSize - (kernelSize & 3); mm < kernelSize; mm++)
sum += kernel[mm] * input[nn+offset+mm];
}
output[nn] = (short)((sum + 0x8000) >> 16);
}
}
经过一天的学习,将上面的代码中内循环部分改为了汇编代码,性能有一点点的提高。
int sum, mm, sum_buf[4]={1,4,9,16};
asm(
"MOV r6, %1 \n"
"MOV r3, %3 \n"
"ADD r2, %2, %4 \n"
"ADD r5, %5, r2, LSL #1 \n"
"BIC r3, r3, #3 \n"
"MOV r2, #0 \n"
"VDUP.16 Q8, r2 \n"
"loop_mm:\n"
"VLD1.16 {D0}, [r6]! \n"
"VLD1.16 {D4}, [r5]! \n"
"VMLAL.S16 Q8, D0, D4 \n"
"ADD r2, r2, #4 \n"
"CMP r2, r3 \n"
"BNE loop_mm \n"
"MOV r2, %0 \n"
"VST1.32 {D16-D17}, [r2]"
:
:"r"(sum_buf),"r"(kernel),"r"(nn),"r"(kernelSize),"r"(offset),"r"(input)
:"memory","r1","r2","r3","r4","r5","r6"
);
sum = sum_buf[0]+sum_buf[1]+sum_buf[2]+sum_buf[3];
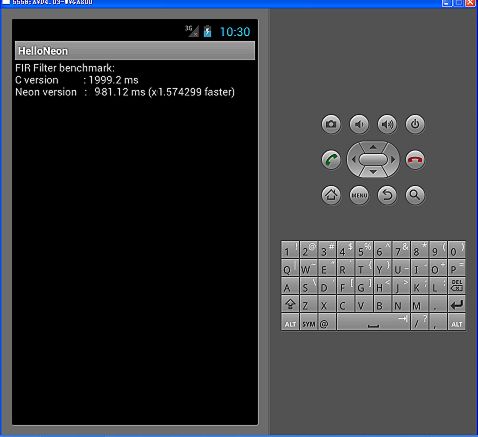
输出结果可能如下,下面这个图的数据是我ps出来的,由于台式机不支持NEON指令(除非你开发用的电脑是用ARM芯片 :-P),模拟器上输出的实际数据要么更慢,要么报告Not an ARMv7 CPU !