对WITH和from(select ...)的一点比较
在之前的工作中,我曾经遇到过表特别大的情况,这个时候我想到了使用with来降低查询的消耗,前文中已经有了描述:http://blog.csdn.net/uncle_six/article/details/7203078。今天我突然想到,其实用with和from (select)应该没有本质的差别。所以做了个小实验。
我的表大概7W行,使用with的SQL语句如下:
WITH A AS (SELECT T.OWNER,
T.OBJECT_NAME,
T.OBJECT_ID,
T.DATA_OBJECT_ID,
T.OBJECT_TYPE,
T.LAST_DDL_TIME,
T.EDITION_NAME,
T.NAMESPACE
FROM TEST1 T
WHERE T.OBJECT_NAME = 'I_USER1')
SELECT * FROM A; 另外一个SQL如下:
SELECT *
FROM (SELECT T.OWNER,
T.OBJECT_NAME,
T.OBJECT_ID,
T.DATA_OBJECT_ID,
T.OBJECT_TYPE,
T.LAST_DDL_TIME,
T.EDITION_NAME,
T.NAMESPACE
FROM TEST1 T
WHERE T.OBJECT_NAME = 'I_USER1'); 这个表的索引在OBJECT_NAME上。
这两个语句的执行计划:

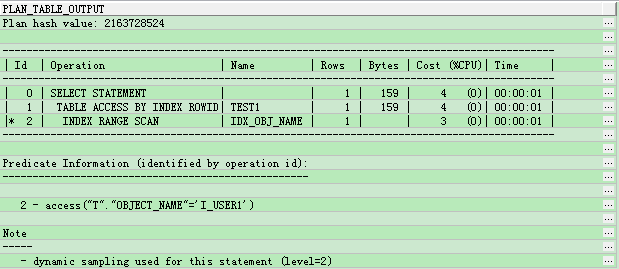
可以看到两者的执行计划没有任何区别。也就是说,在表的数据量十分巨大的情况下,不管是使用with还是from (select ...)这种形式,可以通过选择需要的列来降低bytes,从而达到提高效率的目的,但是两者孰优孰劣,应该说是没有太大的区别的。