MySQL源码分析——代码结构与基本流程
MySQL基本架构
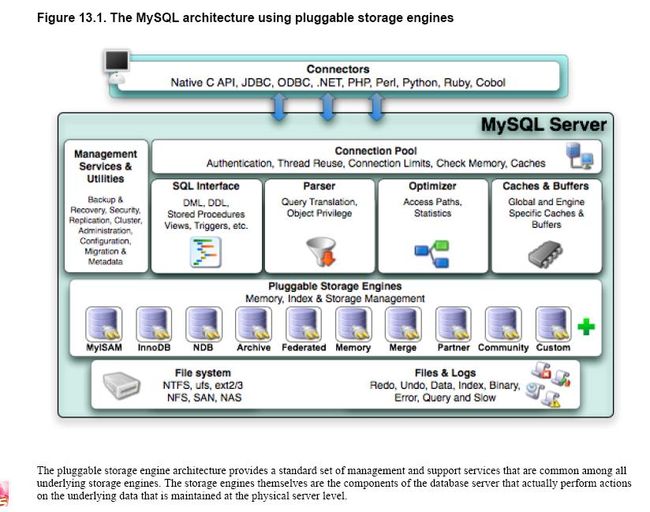
MySQL
目录结构
•build: 内含有各个平台、各种编译器下进行编译的脚本。如compile-pentium-debug表示在pentium架构上进行调试编译的脚本。
•client: 客户端工具,如mysql,mysqladmin之类。
•cmd-line-utils: readline,libedit工具。
•config: 给aclocal使用的配置文件。
•dbug: 提供一些调试用的宏定义。
•Docs: MySQL在不同平台下的参考手册
•extra: 提供innochecksum,resolveip等额外的小工具。
•include: 包含的头文件
•libmysql: 库文件,生产libmysqlclient.so。
•libmysql_r: 线程安全的库文件,生成libmysqlclient_r.so。
•libmysqld: 嵌入式MySQL Server库.
•libservices: 5.5.0中新加的目录,实现了打印功能。
•man: 适合man命令查看的帮助文件。
•mysql-test: mysqld的测试工具套件。
•mysys: 为实现跨平台,MySQL自己实现了一套常用的数据结构和算法,如string, hash等。还包含一些底层函数的跨平台封装,一般以my_开头。
•netware: 在netware平台上进行编译时需要的工具和库。
•plugin: MySQL 5.1开始支持一个插件式API接口,不需要重启mysqld即可动态载入插件,FullText就是一个例子。
•pstack: GNU异步栈追踪工具。
•regex: 正则表达式实现(来自多伦多大学Henry Spencer大牛的源码)。
•scripts: 提供脚本工具,如mysql_install_db/mysqld_safe等。
•server-tools: 包含instance_manager子目录,负责实例的本地和远程管理。
•sql: MySQL Server主要代码,将会生成mysqld文件。
•sql-bench: 一些基准测试代码代码,主要是Perl程序(虽然后缀是sh)。
•sql-common: 存放部分服务器端和客户端都会用到的代码,有些地方的同名文件是这里lin过去的。
•storage: 存储引擎所在目录。
•strings: string库,包含很多字符串处理的函数。
•support-files: my.cnf示例配置文件及编译所需的一些工具。
•tests: 测试文件所在目录。
•unittest: 单元测试文件。
•vio: 虚拟io系统,是对network io的封装,把不同的协议封装成统一的IO函数。
•win: 在windows平台编译所需的文件和一些说明。
•zlib: zlib算法库(GNU)
InnoDB目录结构
•btr: B+树的实现
•buf: 缓冲池的实现,包括LRU算法,Flush刷新算法等
•dict: InnoDB内存数据字典的实现
•dyn: InnoDB动态数组的实现
•fil: InnoDB文件数据结构以及对于文件的一些操作
•fsp: 对InnoDB物理文件的管理,如页/区/段等(即File Space)
•ha: 哈希算法的实现
•handler: 继承与MySQL的handler,实现handler API与Server交互
•ibuf: 插入缓冲(Insert Buffer)的实现
•include: InnoDB所有头文件都放在这个目录,是查找结构定义的最佳地点
•lock: InnoDB的锁实现及三种锁算法实现
•log: 日志缓冲(Log Buffer)和重做日志组(Redo Log)的实现
•mem: 辅助缓冲池(Additional Memory Pool)的实现,用来申请一些内部数据结构的内存
•mtr: 事务的底层实现(日志,缓冲)
•os: 封装一些对于操作系统的操作
•page: 页的实现,研究InnoDB文件结构,这个目录至关重要
•pars: 重载部分MySQL的SQL Parser(有待商榷)
•que: Query graph,基本上没啥用
•read: 读取游标的实现
•rem: 行管理操作(比较操作,打印等)
•row: 对于各种类型行数据操作的实现
•srv: InnoDB后台线程,启动服务,Master Thread,SQL队列等
•sync: InnoDB互斥变量(Mutex)的实现,基本同步机制
•thr: InnoDB封装的可移植线程库
•trx: 事务的实现
•usr: Session管理
•ut: 各种通用小工具
核心类库
•THD: 线程类
•Item: Item类(查询条目,函数,WHERE,ORDER,GROUP,ON子句等)
•TABLE: 表描述符
•TABEL_LIST: JOIN操作描述符
•Field: 列数据类型及属性定义
•LEX: 语法树
•Protocol: 通讯协议
•NET: 网络描述符
•handler: 存储引擎接口
核心函数库
•
内存操作:
•init_alloc_root: 内存池初始化,生成内存池根(MEM_ROOT)
•alloc_root: 申请内存池内存,从mem_root制定的内存池申请内存块
•free_root: 释放内存池,通过MyFlags指定哪种内存可以被释放
•
文件操作:
•my_open: 打开一个文件
•my_close: 关闭一个文件
•my_b_flush_io_cache: 讲数据从内存缓冲写到物理磁盘
•end_io_cache: 释放一个IO_CACHE对象
•
哈希操作:
•_hash_init: 初始化HASH描述符
•hash_search: 搜索哈希表,调用hash_first
•hash_first: 返回哈希表中找到的第一个行指针,否则返回0
•
字符串操作:
•strappend:填充字符串
•strmov: 移动字符串到新地址
核心算法
•Bitmaps
•bitmap_init/bimap_free: 创建与释放一个位图 (8*n个位为单位)
•bitmap_set_bit/bitmap_fast_test_and_set: 设置位图的一个位
•bitmap_clear_all/bitmap_set_all: 清空或全部设置一个位图
•bitmap_cmp: 对两个位图的特定位比较
•Join Buffer
•如果存在条件过滤,则第一次过滤完的记录将放入Join Buffer,避免第二次再判断
•Sort Buffer
•算法一: 将排序字段和主键放入Sort Buffer排序,按照结果用主键取出数据返回
•算法二: 将整行数据放入Sort Buffer,排序完成后直接从Sort Buffer返回数据
MySQL数据流
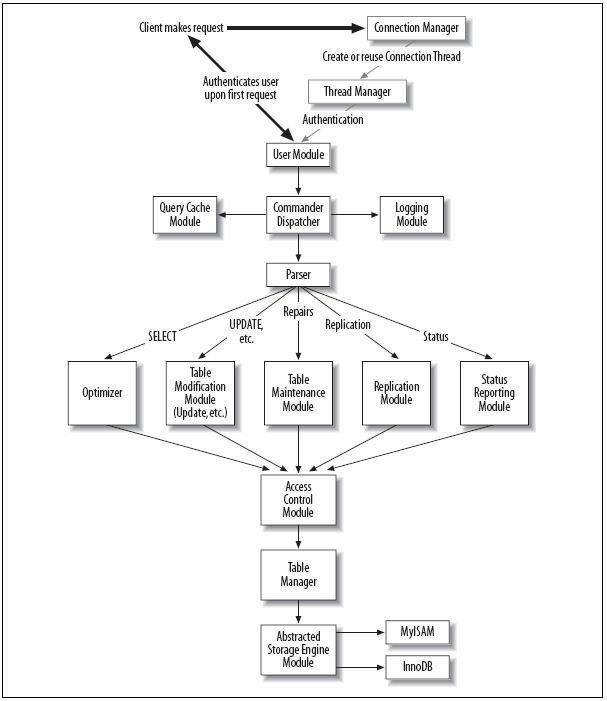
MySQL
启动流程
•主要代码在sql/mysqld.cc中,精简后的代码如下:
•
int main(int argc, char **argv) //标准入口函数
•
MY_INIT(argv[0]);//调用mysys/My_init.c->my_init(),初始化mysql内部的系统库
•
logger.init_base(); //初始化日志功能
•
init_common_variables(MYSQL_CONFIG_NAME,argc, argv, load_default_groups) //调用load_defaults(conf_file_name, groups, &argc, &argv),读取配置信息
•
user_info = check_user(mysqld_user);//检测启动时的用户选项
•
set_user(mysqld_user, user_info);//设置以该用户运行
•
init_server_components();//初始化内部的一些组件,如table_cache, query_cache等。
•
network_init();//初始化网络模块,创建socket监听
•
start_signal_handler();// 创建pid文件
•
mysql_rm_tmp_tables() || acl_init(opt_noacl)//删除tmp_table并初始化数据库级别的权限。
•
init_status_vars(); // 初始化mysql中的status变量
•
start_handle_manager();//创建manager线程
•
handle_connections_sockets();//主要处理函数,处理新的连接并创建新的线程处理
MySQL
监听连接
•主要代码在sql/mysqld.cc中(handle_connections_sockets),精简后的代码如下:
•
pthread_handler_t handle_connections_sockets(void *arg __attribute__((unused))) {
•
FD_SET(unix_sock,&clientFDs); // unix_socket在network_init中被打开
•
while (!abort_loop) { // abort_loop是全局变量,在某些情况下被置为1表示要退出。
•
readFDs=clientFDs; // 需要监听的socket
•
select((int) max_used_connection,&readFDs,0,0,0); // select异步(?科学家解释下是同步还是异步)监听,当接收到??以后返回。
•
new_sock = accept(sock, my_reinterpret_cast(struct sockaddr *) (&cAddr), &length); // 接受请求
•
thd= new THD; // 创建mysqld任务线程描述符,它封装了一个客户端连接请求的所有信息
•
vio_tmp=vio_new(new_sock, VIO_TYPE_SOCKET, VIO_LOCALHOST); // 网络操作抽象层
•
my_net_init(&thd->net,vio_tmp)); // 初始化任务线程描述符的网络操作
•
create_new_thread(thd); // 创建任务线程
•
}
•
}
MySQL
创建连接
•主要代码在sql/mysqld.cc中(create_new_thread/create_thread_to_handle_connection),精简后的代码如下:
•
static void create_new_thread(THD *thd) {
•
NET *net=&thd->net;
•
if (connection_count >= max_connections + 1 || abort_loop) { // 看看当前连接数是不是超过了系统配置允许的最大值,如果是就断开连接。
•
close_connection(thd, ER_CON_COUNT_ERROR, 1);
•
delete thd;
•
}
•
++connection_count;
•
thread_scheduler.add_connection(thd); // 将新连接加入到thread_scheduler的连接队列中。
•
}
•而thread_scheduler转而调用create_thread_to_handle_connection,精简后的代码如下:
•
void create_thread_to_handle_connection(THD *thd) {
•
if (cached_thread_count > wake_thread) { //看当前工作线程缓存(thread_cache)中有否空余的线程
•
thread_cache.append(thd);
•
pthread_cond_signal(&COND_thread_cache); // 有的话则唤醒一个线程来用
•
} else {
•
threads.append(thd);
•
pthread_create(&thd->real_id,&connection_attrib, handle_one_connection, (void*) thd))); //没有可用空闲线程则创建一个新的线程
•
}
•
}
•创建连接使用handle_one_connection函数,精简代码如下:
•
pthread_handler_t handle_one_connection(void *arg) {
•
thread_scheduler.init_new_connection_thread(); // 初始化线程预处理操作
•
setup_connection_thread_globals(thd); //载入一些Session级变量
•
for (;;) {
•
lex_start(thd); //初始化LEX词法解析器
•
login_connection(thd); // 进行连接身份验证
•
prepare_new_connection_state(thd); // 初始化线程Status,即show status看到的
•
do_command(thd); // 处理命令
•
end_connection(thd); //没事做了关闭连接,丢入线程池
•
}
•
}
MySQL执行Query
•do_command函数在sql/sql_parse.cc定义,代码如下:
•
bool do_command(THD *thd) {
•
NET *net= &thd->net;
•
packet_length = my_net_read(net);
•
packet = (char*) net->read_pos;
•
command = (enum enum_server_command) (uchar) packet[0]; // 解析客户端传过来的命令类型
•
dispatch_command(command, thd, packet+1, (uint) (packet_length-1));
•
}
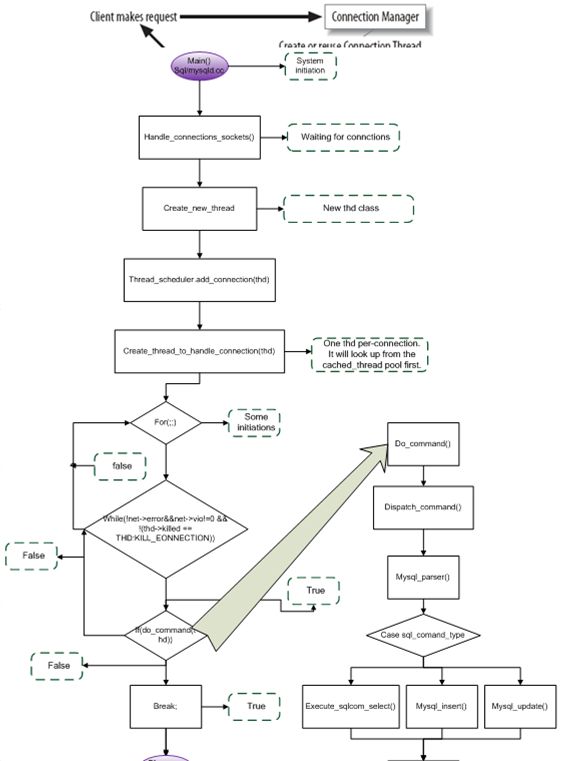
•再看dispatch_command函数在sql/sql_parse.cc定义,精简代码如下:
•
bool dispatch_command(enum enum_server_command command, THD *thd, char* packet, uint packet_length) {
•
NET *net = &thd->net;
•
thd->command = command;
•
switch (command) { //判断命令类型
•
case COM_INIT_DB: ...;
•
case COM_TABLE_DUMP: ...;
•
case COM_CHANGE_USER: ...;
•
...
•
case COM_QUERY: //如果是Query
•
alloc_query(thd, packet, packet_length); //从网络数据包中读取Query并存入thd->query
•
mysql_parse(thd, thd->query, thd->query_length, &end_of_stmt); //送去解析
•
}
•
}
•mysql_parse函数负责解析SQL(sql/sql_parse.cc),精简代码如下:
•
void mysql_parse(THD *thd, const char *inBuf, uint length, const char ** found_semicolon) {
•
lex_start(thd); //初始化线程解析描述符
•
if (query_cache_send_result_to_client(thd, (char*) inBuf, length) <= 0) { // 看query cache中有否命中,有就直接返回结果,否则进行查找
•
Parser_state parser_state(thd, inBuf, length);
•
parse_sql(thd, & parser_state, NULL); // 解析SQL语句
•
mysql_execute_command(thd); // 执行
•
}
•
}
•终于开始执行鸟~mysql_execute_command接近3k行......,非常精简代码如下:
•
int mysql_execute_command(THD *thd) {
•
LEX *lex= thd->lex; // 解析过后的SQL语句的语法结构
•
TABLE_LIST *all_tables = lex->query_tables; // 该语句要访问的表的列表
•
switch (lex->sql_command) {
•
...
•
case SQLCOM_INSERT:
•
insert_precheck(thd, all_tables);
•
mysql_insert(thd, all_tables, lex->field_list, lex->many_values, lex->update_list, lex->value_list, lex->duplicates, lex->ignore);
•
break; ...
•
case SQLCOM_SELECT:
•
check_table_access(thd, lex->exchange ? SELECT_ACL | FILE_ACL : SELECT_ACL, all_tables, UINT_MAX, FALSE); // 检查用户对数据表的访问权限
•
execute_sqlcom_select(thd, all_tables); // 执行select语句
•
break;
•
}
•
}
•我们看一个例子, mysql_insert (在sql/sql_insert.cc),精简代码如下:
•
bool mysql_insert(THD *thd,
•
TABLE_LIST *table_list, // 该INSERT要用到的表
•
List<Item> &fields, // 使用的项
•
....) {
•
open_and_lock_tables(thd, table_list); // 这里的锁只是防止表结构修改
•
mysql_prepare_insert(...);
•
foreach value in values_list {
•
write_record(...);
•
}
•
} //里面还有很多处理trigger,错误,view之类的杂七杂八的东西,我们都忽略。
•我们接着看真正写数据的函数write_record (在sql/sql_insert.cc),精简代码如下:
•
int write_record(THD *thd, TABLE *table,COPY_INFO *info) { // 写数据记录
•
if (info->handle_duplicates == DUP_REPLACE || info->handle_duplicates == DUP_UPDATE) { //如果是REPLACE或UPDATE则替换数据
•
table->file->ha_write_row(table->record[0]);
•
table->file->ha_update_row(table->record[1], table->record[0]));
•
} else {
•
table->file->ha_write_row(table->record[0]);
•
}
•
}
•
•
int handler::ha_write_row(uchar *buf) { //这是啥? Handler API !
•
write_row(buf); // 调用具体的实现
•
binlog_log_row(table, 0, buf, log_func)); // 写binlog
•
}
Query流程