Linux内核网桥的实现分析
Linux内核网桥的实现分析
Linux 内核分别在2.2 和 2.4内核中实现了网桥。但是2.2 内核和 2.4内核的实现有很大的区别,2.4中的实现几乎是全部重写了所有的实现代码。本文以2.4.0内核版本为例进行分析。
在分析具体的实现之前,先描述几个概念,有助于对网桥的功能及实现有更深的理解。
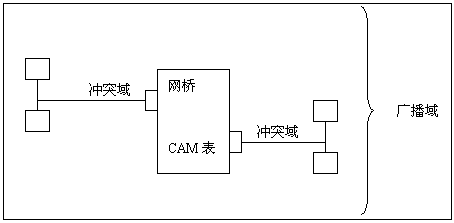
- 冲突域
一个冲突域由所有能够看到同一个冲突或者被该冲突涉及到的设备组成。以太网使用C S M A / C D(Carrier Sense Multiple Access with Collision Detection,带有冲突监测的载波侦听多址访问)技术来保证同一时刻,只有一个节点能够在冲突域内传送数据。网桥或者交换机,构成了一个冲突域的边界。缺省情况下,网桥中的每个端口实际上就是一个冲突域的结束点。
- 广播域
一个广播域由所有能够看到一个广播数据包的设备组成。一个路由器,构成一个广播域的边界。网桥能够延伸到的最大范围就是一个广播域。缺省的情况下,一个网桥或交换机的所有端口在同一个广播域中。VLAN技术可以把交换机或者网桥的不同端口分割成不同的广播域。一般情况下, 一个广播域代表一个逻辑网段。
- 网桥中的CAM表
网桥和交换机一样,为了能够实现对数据包的转发,网桥保存着许多(MAC,端口)项。所有的这些项组成一个表,叫做CAM表。每个项有超时机制,如果一定时间内未接收到以这个MAC为源MAC地址的数据包,这个项就会被删除。
图1:一个交换网络的逻辑图
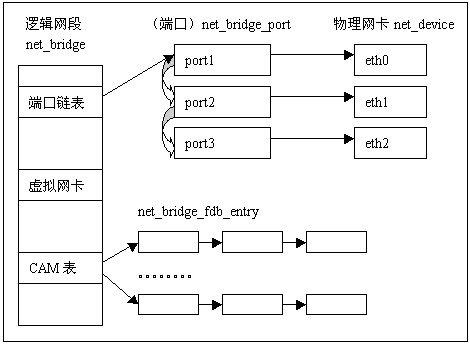
在Linux内核网桥的实现中,一个逻辑网段用net_bridge结构体表示。一个逻辑网段需要保留的信息有:
- 本逻辑网段中所有的端口(port_list)
每个端口用net_bridge_port结构体来表示,从net_bridge_port结构体中可以看出,它主要有:
- 逻辑网段中的下一个端口(next)
- 本端口所属的逻辑网段(br)
- 本端口所指向的物理网卡(dev)
- 本端口在网桥中的编号(port_no)
- 用于生成树管理的信息
-
一个逻辑网段中可以具有很多个端口,所有的端口都挂在以port_list为链表头的链表上。
本网段中CAM表(hash[BR_HASH_SIZE])CAM表中的每个项用net_bridge_fdb_entry结构体代表,每项中有:
- 用于CAM表连接的链表指针(next_hash,pprev_hash)
- 此项当前的引用计数(use_count)
- MAC地址(addr)
- 此项所对应的端口(dst)
- 处理MAC超时(ageing_timer)
- 是否是本机的MAC地址(is_local)
- 是否是静态MAC地址(is_static)
-
一个逻辑网段中的所有表项形成一个CAM表,他们之间的组织关系是一个HASH链表。HASH链的个数为BR_HASH_SIZE(256)。
本逻辑网段用于和外部通信的虚拟网络设备(dev)Linux网桥可以在网桥上为每个逻辑网段配置一个IP,用于和外部通信。实际上这个IP不是配置在一个特定的物理网卡上面, 而是建立一个虚拟的网卡,虚拟网卡可以附在每个同一逻辑网段的物理网卡上,让这个网卡可以象所有的物理网卡一样工作。从而使网桥可以和外部通信。
- 本逻辑网段虚拟网卡的统计数据(statistics)
按照Linux网卡驱动的接口,一个网卡的统计信息是由每个网卡的私有数据处理的。一般的写法是用dev->priv来指向每个网卡的统计数据。网卡的get_stats方法就是用来读取统计数据。
- 用户一个网段的生成树(STP)信息
以上对几个结构体的描述和分析可以通过下图来表示:
图2:Linux网桥数据结构描述图
描述了网桥的数据结构后,就可以开始数据包处理流程的分析。
网桥处理包遵循着以下几条原则:
- 在一个接口上接收到的包不会再在那个接口上发送这个数据包。
- 每个接收到的数据包都要学习其源MAC地址。
- 如果数据包是多播包或广播包,则要在同一个网段中除了接收端口外的其他所有端口发送这个数据包,如果上层协议栈对多播包感兴趣,则需要把数据包提交给上层协议栈。
- 如果数据包的目的MAC地址不能在CAM表中找到,则要在同一个网段中除了接收端口外的其他所有端口发送这个数据包。
- 如果能够在CAM表中查询到目的MAC地址,则在特定的端口上发送这个数据包,如果发送端口和接收端口是同一端口,则不发送。
在网络软中断处理函数net_rx_action中,嵌入了handle_bridge用于把数据包skb送入网桥模块处理。
#if defined(CONFIG_BRIDGE) || defined(CONFIG_BRIDGE_MODULE)
if (skb->dev->br_port != NULL &&
br_handle_frame_hook != NULL) {
handle_bridge(skb, pt_prev);
dev_put(rx_dev);
continue;
}
#endif
br_handle_frame_hook是网桥处理接收到数据包的中入口,网桥初始化(br_init)的时候,把br_handle_frame_hook赋值为br_handle_frame。skb->dev->br_port用于判断接收到这个数据包的接口是否是网桥中的一个端口,如果是,skb->dev->br_port不为NULL,那么数据包应该由网桥处理。反之,数据包由上层协议栈处理。网桥中虚拟网卡对应的数据包就是在这个判断点时不再进入网桥。(实际上虚拟网卡并不会自己主动接收数据包,而是在网桥处理中把数据包向本地上层协议栈提交,并且修改了skb->dev,使得数据包不会多次进入桥处理代码)。
前面提到,网桥处理接收包的入口是br_handle_frame(net/bridge/br_input.c)函数。
br_handle_frame函数首先从skb中获得这个包属于的逻辑网段。然后调用__br_handle_frame进行转发处理。 br_handle_frame函数里有一个值得了解的地方,里面有一个加读锁。因为在转发中需要读CAM表,所以必须加读锁,避免在这个过程中另外的内核控制路径(如多处理机上另外一个CPU上的系统调用)修改CAM表。
对输入包的转发决策都是在__br_handle_frame函数中。这个函数的处理可以分为以下几个部分:
- 如果网桥的虚拟网卡处于混杂模式,那么每个接收到的数据包都需要克隆一份送到AF_PACKET协议处理体(网络软中断函数net_rx_action中ptype_all链的处理)。
if (br->dev.flags & IFF_PROMISC) { struct sk_buff *skb2; skb2 = skb_clone(skb, GFP_ATOMIC); if (skb2) { passedup = 1; br_pass_frame_up(br, skb2); } } - 如果源MAC地址是多播或者是广播地址,那么这个包格式是错误的,简单的丢弃。
if (skb->mac.ethernet->h_source[0] & 1) goto freeandout;
- 如果是一个多播包,则需要向本机的上层协议栈传送这个数据包(如果在之前没有向上提交的话,即passedup为0。如果为1,则前面已经发送了,现在就不需要提交了,在后面中的处理都是一样的)。
if (!passedup && (dest[0] & 1) && (br->dev.flags & IFF_ALLMULTI || br->dev.mc_list != NULL)) { struct sk_buff *skb2; skb2 = skb_clone(skb, GFP_ATOMIC); if (skb2) { passedup = 1; br_pass_frame_up(br, skb2); } } - 如果启动了生成树协议,一个生成树包需要由生成树协议处理模块单独处理。如果不支持,则这个包的目的MAC肯定在CAM中查询不到,所以是向所有的端口发送(除接收口)。这样才不会影响整个网络的生成树协议运行。
if (br->stp_enabled && !memcmp(dest, bridge_ula, 5) && !(dest[5] & 0xF0)) goto handle_special_frame;
- 如果接收端口不是处于LEARNING或者FORWARDING,那么就学习这个包的源MAC地址,或者更新CAM表中相应项的定时器。
if (p->state == BR_STATE_LEARNING || p->state == BR_STATE_FORWARDING) br_fdb_insert(br, p, skb->mac.ethernet->h_source, 0);
- 如果是一个多播包或广播包,则调用br_flood函数向每个口发送(除接收口)这个数据包。如果之前没有提交上层协议,则需要克隆一个包提交上层协议。
if (dest[0] & 1) { br_flood(br, skb, 1); if (!passedup) br_pass_frame_up(br, skb); else kfree_skb(skb); return; } - 用接收到数据包的目的MAC地址查询CAM表。
dst = br_fdb_get(br, dest);
- 查询CAM表后,如果能够找到表项,并且目的MAC是到本机的虚拟网卡的,那么就需要把这个包提交给上层协议。网桥就是通过这个地方的处理和外部通信,实现远程管理的目的。
if (dst != NULL && dst->is_local) { if (!passedup) br_pass_frame_up(br, skb); else kfree_skb(skb); br_fdb_put(dst); return; } - 如果查询CAM表有结果,并且目的MAC不是到本地的,那么就通过调用br_forward发送到特定的端口。
if (dst != NULL) { br_forward(dst->dst, skb); br_fdb_put(dst); return; } - 如果在CAM表中查询不到数据包的目的MAC地址,那么就需要向别的每个端口发送这个数据包。调用br_flood来进行这个处理。
br_flood(br, skb, 0); return;
在br_forward和br_flood函数中都必须判断源接口和目的接口是否是同一个,如果是同一端口,就不发送这个数据包。数据包的最后发送都是通过统一的发送接口dev_queue_xmit函数来完成的。
以下就是数据包的处理流程:
图3:数据包处理流程图
前面多次提到网桥的虚拟网卡,实际上在网桥中,这个网卡存在着一个net_device结构(在net_bridge里),但是不存在着实际的物理设备,而是附在网桥中每个物理网卡上面。这个虚拟网卡的支持函数在(br_device.c)。因为是虚拟的网卡,所以没有物理中断产生,每个需要发送到这个设备的数据包都是靠判断数据包的目的MAC地址来决定是否需要提交到本地上层协议栈(在__br_handle_frame判断)。
如果数据包需要向上层协议提交,都调用br_pass_frame_up函数来处理。在这个函数中,首先把skb->dev设置成br->dev。然后再模拟在中断中处理数据包一样,进行相应的处理, 然后调用netif_rx放入接收队列。这里有一个要十分注意的地方,这个数据包的skb->dev已经变成br->dev。所以在网络接收软中断处理函数net_rx_action中不会再次进入handle_bridge了。
static void br_pass_frame_up(struct net_bridge *br, struct sk_buff *skb)
{
br->statistics.rx_packets++;
br->statistics.rx_bytes += skb->len;
skb->dev = &br->dev;
skb->pkt_type = PACKET_HOST;
skb_pull(skb, skb->mac.raw - skb->data);
skb->protocol = eth_type_trans(skb, &br->dev);
netif_rx(skb);
}