CRC32算法详细推导(1)
From: http://blog.csdn.net/sparkliang/article/details/5671510
CRC算法详解(1)
作为blog再次发出来,详细描述一下CRC32算法的推导过程。
CRC 算法的数学基础
CRC 算法的数学基础就不再多啰嗦了,到处都是,简单提一下。它是以 GF(2) 多项式算术为数学基础的,GF(2) 多项式中只有一个变量 x ,其系数也只有 0 和 1 ,比如:
1 *x^6 + 0*x^5 + 1*x^4 + 0*x^3 + 0*x^2 +1*x^1 + 1*x^0
= x^6 + x^4 + x + 1
加减运算不考虑进位和退位。说白了就是下面的运算规则:
0 + 0 = 0 0 - 0 = 0
0 + 1 = 1 0 - 1 = 1
1 + 0 = 1 1 - 0 = 1
1 + 1 = 0 1 - 1 = 0
看看这个规则,其实就是一个异或运算。
每个生成多项式的系数只能是 0 或 1 ,因此我们可以把它转化为二进制形式表示, 比如 g(x)=x^4 + x + 1 ,那么g(x) 对应的二进制形式就是 10011 , 于是我们就把 GF(2) 多项式的除法转换成了二进制形式,和普通除法没有区别,只是加减运算没有进位和退位。
比如基于上述规则计算 11010/1001 ,那么商是 11 ,余数就是 101 ,简单吧。
CRC 校验的基本过程
采用 CRC 校验时,发送方和接收方用同一个生成多项式 g(x) , g(x) 是一个 GF(2) 多项式,并且 g(x) 的首位和最后一位的系数必须为 1 。
CRC 的处理方法是:发送方用发送数据的二进制多项式 t(x) 除以 g(x) ,得到余数 y(x) 作为 CRC 校验码。校验时,以计算的校正结果是否为 0 为据,判断数据帧是否出错。设生成多项式是 r 阶的(最高位是 x^r )具体步骤如下面的描述。
发送方:
1 )在发送的 m 位数据的二进制多项式 t(x) 后添加 r 个 0 ,扩张到 m+ r 位,以容纳 r 位的校验码,追加 0 后的二进制多项式为 T(x) ;
2 )用 T(x) 除以生成多项式 g(x) ,得到 r 位的余数 y(x) ,它就是 CRC 校验码;
3 )把 y(x) 追加到 t(x) 后面,此时的数据 s(x) 就是包含了 CRC 校验码的待发送字符串;由于 s(x) = t(x) y(x) ,因此 s(x) 肯定能被 g(x) 除尽。
接收方:
1 )接收数据 n(x) ,这个 n(x) 就是包含了 CRC 校验码的 m+r 位数据;
2 )计算 n(x) 除以 g(x) ,如果余数为 0 则表示传输过程没有错误,否则表示有错误。从 n(x) 去掉尾部的 r 位数据,得到的就是原始数据。
生成多项式可不是随意选择的,数学上的东西就免了,以下是一些标准的 CRC 算法的生成多项式:
| 标准 |
生成多项式 |
16 进制表示 |
| CRC12 |
x^12 + x^11 + x^3 + x^2 + x + 1 |
0x80F |
| CRC16 |
x^16 + x^15 + x^2 + 1 |
0x8005 |
| CRC16-CCITT |
x^16 + x^12 + x^5 + 1 |
0x1021 |
| CRC32 |
x^32 + x^26 + x^23 + x^22 + x^16 + x^12 + x^11+ x^10 + x^8 + x^7 + x^5 + x^4 + x^2 + x + 1 |
0x04C11DB7 |
原始的 CRC 校验算法
根据多项式除法,我们就可以得到原始的 CRC 校验算法。假设生成多项式 g(x) 是 r 阶的,原始数据存放在 data中,长度为 len 个 bit , reg 是 r+1 位的变量。 以 CRC-4 为例,生成多项式 g(x)=x^4 + x + 1 ,对应了一个 5bits 的二进制数字 10011 ,那么 reg 就是 5 bits 。
reg[1] 表明 reg 的最低位, reg[r+1] 是 reg 的最高位。
通过反复的移位和进行除法,那么最终该寄存器中的值去掉最高一位就是我们所要求的余数。所以可以将上述步骤用下面的流程描述:
- reg = 0;
- data = data追加r个;
- pos = 1;
- while(pos <= len)
- {
- if(reg[r+1] == 1) // 表明reg可以除以g(x)
- {
- // 只关心余数,根据上面的算法规则可知就是XOR运算
- reg = reg XOR g(x);
- }
- // 移出最高位,移入新数据
- reg = (reg<<1) | (data[pos]);
- pos++;
- }
- return reg; // reg中的后r位存储的就是余数
改进一小步——从 r+1 到 r
由于最后只需要 r 位的余数,所以我们可以尝试构造一个 r 位的 reg ,初值为 0 ,数据 data 依次移入 reg[1] ,同时把reg[r] 移出 reg 。
根据上面的算法可以知道,只有当移出的数据为 1 时, reg 才和 g(x) 进行 XOR 运算;于是可以使用下面的算法:
- reg = 0;
- data = data追加r个;
- pos = 1;
- while(pos < len)
- {
- hi-bit = reg[r];
- // 移出最高位,移入新数据
- reg = (reg<<1) | (data[pos]);
- if(hi-bit == 1) // 表明reg可以除以g(x)
- {
- reg = reg XOR g(x);
- }
- pos++;
- }
- return reg; // reg中存储的就是余数
这种算法简单,容易实现,对任意长度生成多项式的 G ( x )都适用,对应的 CRC-32 的实现就是:
- // 以4 byte数据为例
- #define POLY 0x04C11DB7L // CRC32生成多项式
- unsigned int CRC32_1(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, idx = 0;
- for(int i = 0; i < 64; i++)
- {
- idx = i/8;
- int hi = (reg>>31)&0x01; // 取得reg的最高位
- // 把reg左移1bit,并移入新数据到reg0
- reg = (reg<<1)| (p[idx]>>7);
- if(hi) reg = reg^POLY; // hi=1就用reg除以g(x)
- p[idx]<<=1;
- }
- return reg;
- }
从 bit 扩张到 byte 的桥梁
但是如果发送的数据块很长的话,这种方法就不太适合了。它一次只能处理一个 bit 的数据,效率太低。考虑能不能每次处理一个 byte 的数据呢?事实上这也是当前的 CRC-32 实现采用的方法。
这一步骤是通往基于校验表方法的桥梁,让我们一步一步来分析上面逐 bit 的运算方式,我们把 reg 和 g(x) 都采用 bit 的方式表示如下:
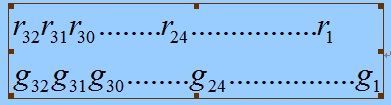
考虑把上面逐 bit 的算法执行 8 次,如果某次移出的不是 1 ,那么 reg 不会和 g(x) 执行 XOR 运算,事实上这相当于将 reg 和 0 执行了 XOR 运算。执行过程如下所示,根据 hi-bit 的值,这里的 G 可能是 g(x) 也可能是 0 。

从上面的执行过程清楚的看到,执行 8 次后, old-reg 的高 8bit 被完全移出, new-reg 就是 old-reg 的低24bit 和数据 data 新移入的 8bit 和 G 一次次执行 XOR 运算所得到的。
XOR 运算满足结合律,那就是: A XOR B XOR C = A XOR (B XOR C) ,于是我们可以考虑把上面的运算分成两步进行:
1 )先执行 R 高 8bit 与 G 之间的 XOR 运算,将计算结果存入 X 中,如下面的过程所示。
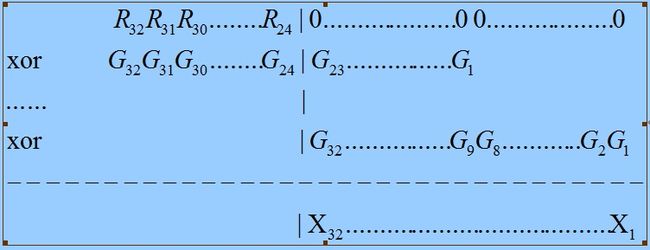
2 )将 R 左移 8bit ,并移入 8bit 的数据,得到的值就是 ![]() ,然后再与 X 做 XOR运算。
,然后再与 X 做 XOR运算。
根据 XOR 运算的结合率,最后的结果就等于上面逐 bit 的算法执行 8 次后的结果,根据这个分解,我们可以修改逐bit 的方式,写出下面的算法。
- // 以4 byte数据为例
- #define POLY 0x04C11DB7L // CRC32生成多项式
- unsigned int CRC32_2(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, sum_poly = 0;
- for(int i = 0; i < 8; i++)
- {
- // 计算步骤1
- sum_poly = reg&0xFF000000;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x80000000; // 测试reg最高位
- sum_poly <<= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
- }
- return reg;
- }