libsvm 使用介绍
一、介绍:
LIBSVM是台湾大学林智仁(Chih-Jen Lin)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross Validation)的功能。
二、安装使用
1、下载
总共需要三个软件:libsvm, python, gnuplot。(python安装就不用说了,记得加python路径到环境变量)
gnuplot是用来画图用的。可以直接去这里下载http://download.csdn.net/detail/kuaile123/6252717
放置路径如下:
E:\labSoftWare\gp373w32
E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9
2、修改参数
在c:\libsvm-2.9\tools中修改easy.py和grid.py的路径:
①打开easy.py 修改地方如下:
else:
# example for windows
svmscale_exe = r"E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows\svm-scale.exe"
svmtrain_exe = r"E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows\svm-train.exe"
svmpredict_exe = r"E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows\svm-predict.exe"
gnuplot_exe = r"E:\labSoftWare\gp373w32\pgnuplot.exe"
grid_py = r"E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\tools\grid.py"
②点中grid.py修改路径如下:
else:
# example for windows
svmtrain_exe = r"E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows\svm-train.exe"
gnuplot_exe = r"E:\labSoftWare\gp373w32\pgnuplot.exe"
三、训练步骤
里面的语法和参数说明:按照 E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9和E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\tools下的README
(1)按照LIBSVM软件包所要求的格式准备数据集;
libSVM的数据格式
Label 1:value 2:value ….
Label:是类别的标识,比如1 -1,可以自己随意定,比如-10,0,15。当然,如果是回归,这是目标值,就要实事求是了。
Value:就是要训练的数据,从分类的角度来说就是特征值,数据之间用空格隔开
需要注意的是,如果特征值为0,特征冒号前面的(姑且称做序号)可以不连续。如:
-15 1:0.708 3:-0.3333
表明第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度。
准备的数据存放于txt中,如 heart.txt
可以在这里下载http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/heart
(2)对数据进行缩放操作;
svm-scale是用来对原始样本进行缩放的,范围可以自己定,一般是[0,1]或[-1,1]。缩放的目的主要是
1)防止某个特征过大或过小,从而在训练中起的作用不平衡;
2)为了计算速度。因为在核计算中,会用到内积运算或exp运算,不平衡的数据可能造成计算困难。
用法:svm-scale [-l lower] [-u upper]
[-y y_lower y_upper]
[-s save_filename]
[-r restore_filename] filename
其中,[]中都是可选项:
-l:设定数据下限;lower:设定的数据下限值,缺省为-1
-u:设定数据上限;upper:设定的数据上限值,缺省为 1
-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;
-s save_filename:表示将缩放的规则保存为文件save_filename;
-r restore_filename:表示将按照已经存在的规则文件restore_filename进行缩放;
filename:待缩放的数据文件,文件格式按照libsvm格式。
默认情况下,只需要输入要缩放的文件名就可以了:
svm-scaleheart.txt
这时,test.txt中的数据已经变成[-1,1]之间的数据了。但是,这样原来的数据就被覆盖了,为了让规划好的数据另存为其他的文件,我们用一个dos的重定向符 > 来另存为(假设为out.txt):
svm-scaleheart.txt > out.txt
运行后,我们就可以看到目录下多了一个out.txt文件,那就是规范后的数据。假如,我们想设定数据范围[0,1],并把规则保存为heart.range文件:
svm-scale –l 0 –u 1 -sheart.range heart.txt > out.txt
将数据heart.txt保存在E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows文件夹下
svm-scale -l 0 -u 1 heart.txt > heart.scale.txt
(3)选用适当的核函数;
(4)采用交叉验证选择惩罚系数C与g的最佳参数;
cd 到所要保存文件的路径下 输入
python E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\tools\grid.py -log2c -10,10,1 -log2g -10,10,1 E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows\heart.scale.txt > test.txt
会出错显示 libsvm NameError: global name 'split' is not defined
原因是split使用语法错误,跟python版本不一致造成的,将split(argv[i],",") 都替换为argv[i].split(",")
这个需要一段时间,产生一个test.txt文件,其中记录了参数寻优的结果
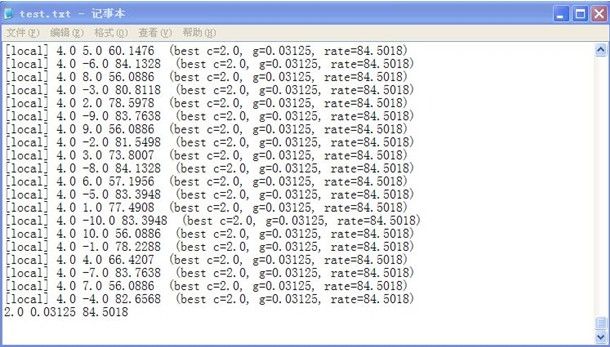
可以看到,参数分别为c 2.0,g 0.03125,正确率mse为84%。
还可以得到heart.scale.txt.png

(5)采用获得的最佳参数对整个训练集进行训练获取支持向量机模型;
svm-train用法:
用法: svm-train [options] training_set_file [model_file]
其中,options为操作参数,可用的选项即表示的涵义如下所示:
-s设置svm类型:
0 – C-SVC
1 – v-SVC
2 – one-class-SVM
3 –ε-SVR
4 – n - SVR
-t设置核函数类型,默认值为2
0 -- 线性核:u'*v
1 -- 多项式核: (g*u'*v+coef0)degree
2 -- RBF 核:exp(-γ*||u-v||2)
3 -- sigmoid 核:tanh(γ*u'*v+coef0)
-d degree:设置多项式核中degree的值,默认为3
-gγ:设置核函数中γ的值,默认为1/k,k为特征(或者说是属性)数;
-r coef 0:设置核函数中的coef 0,默认值为0;
-c cost:设置C-SVC、ε-SVR、n - SVR中从惩罚系数C,默认值为1;
-n v:设置v-SVC、one-class-SVM与n - SVR中参数n ,默认值0.5;
-pε:设置v-SVR的损失函数中的e,默认值为0.1;
-m cachesize:设置cache内存大小,以MB为单位,默认值为40;
-eε:设置终止准则中的可容忍偏差,默认值为0.001;
-h shrinking:是否使用启发式,可选值为0或1,默认值为1;
-b概率估计:是否计算SVC或SVR的概率估计,可选值0或1,默认0;
-wi weight:对各类样本的惩罚系数C加权,默认值为1;
-v n:n折交叉验证模式;
model_file:可选项,为要保存的结果文件,称为模型文件,以便在预测时使用。
默认情况下,只需要给函数提供一个样本文件名就可以了,但为了能保存结果,还是要提供一个结果文件名,比如:test.model,则命令为:
svm-train heart.txttest.model
利用上步所得到的的参数 c 2.0,g 0.03125 对heart.scale.txt进行训练,cd 到 E:\labSoftWare\libsvm-2.9.tar\libsvm-2.9\windows 下输入:
svm-train –c 2.0 –g 0.03125 -b 1 heart.scale.txt heart.scale.txt.model
注意此处这里会生成 heart.scale.txt.model
注意要加 -b 1 不然进行c++连接训练时会出错。probability_estimates train a SVR model for probability estimates
(6)利用获取的模型进行测试与预测。
svm-predict 是根据训练获得的模型,对数据集合进行预测。用法:svm-predict [options] test_file model_file output_file
其中,options为操作参数,可用的选项即表示的涵义如下所示:
-b probability_estimates——是否需要进行概率估计预测,可选值为0或者1,默认值为0。
model_file ——是由svmtrain产生的模型文件;
test_file——是要进行预测的数据文件,格式也要符合libsvm格式,即使不知道label的值,也要任意填一个,svmpredict会在output_file中给出正确的label结果,如果知道label的值,就会输出正确率;
output_file ——是svmpredict的输出文件,表示预测的结果值。
如在一个test1.txt文件输入一个符合规则的值,输出结果保存在result1.txt中,则 cmd下输入 svm-predict test1.txt heart.scale.txt.model result1.txt
四、svm.cpp 等的理解
自己下载:
http://download.csdn.net/detail/kuaile123/6253085
更多理解参考:http://xgli0910.blog.163.com/blog/static/469621682012313101327710/