scikit-learn:3.1. Cross-validation: evaluating estimator performance
参考:http://scikit-learn.org/stable/modules/cross_validation.html
overfitting很常见,所以提出使用test set来验证模型的performance。给个直观的例子:
>>> import numpy as np >>> from sklearn import cross_validation >>> from sklearn import datasets >>> from sklearn import svm >>> iris = datasets.load_iris() >>> iris.data.shape, iris.target.shape ((150, 4), (150,))
>>> X_train, X_test, y_train, y_test = <strong>cross_validation.train_test_split</strong>( ... iris.data, iris.target, <strong>test_size=0.4, random_state=0</strong>) #<span style="font-family: Arial, Helvetica, sans-serif;"><strong>holding out 40% of the data for testing</strong></span> >>> X_train.shape, y_train.shape ((90, 4), (90,)) >>> X_test.shape, y_test.shape ((60, 4), (60,)) >>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train) >>> clf.score(X_test, y_test) 0.96...
还有个问题就是,超参数( C=1)是人工设置,这样会造成overfitting。所以提出training set、validation set、test set的三级概念: training proceeds on the training set, after which evaluation is done on the validation set, and when the experiment seems to be successful, final evaluation can be done on the test set。
三级概念也有问题,数据量少时,进一步加重了训练数据的量少。所以提出 cross-validation (CV for short,k-fold CV)的概念:
- A model is trained using
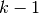 of the folds as training data;
of the folds as training data; - the resulting model is validated on the remaining part of the data (i.e., it is used as a test set to compute a performance measure such as accuracy).
1、 Computing cross-validated metrics
使用CV最简单的方法是,同时对estimator和dataset调用 cross_val_score helper function:
均值和95%的置信区间(The mean score and the 95% confidence interval of the score estimate are hence given by:)
自定义scoring函数(默认是score函数,其实有十几种内置函数,比如f1、log_loss等,具体参考:The scoring parameter: defining model evaluation rules ):
这里恰巧accuracy和f1-score相等。
自定义CV策略(cv是整数的话默认使用KFold):
注意:test set要和training set做相同的预处理操作(standardization、data transformation、etc):
pipeline能简化该过程( See Pipeline and FeatureUnion: combining estimators .,翻译之后的文章:http://blog.csdn.net/mmc2015/article/details/46991465):
另一个接口cross_val_predict ,可以返回每个元素作为test set时的确切预测值(只有在CV的条件下数据集中每个元素都有唯一预测值时才不会出现异常),进而评估estimator:
几个不错的例子:
- Receiver Operating Characteristic (ROC) with cross validation,
- Recursive feature elimination with cross-validation,
- Parameter estimation using grid search with cross-validation,
- Sample pipeline for text feature extraction and evaluation,
- Plotting Cross-Validated Predictions,
2、Cross validation iterators
介绍不同CV策略对应的产生indices的utilities。所有的方法都是先产生indices、再生成子集。
1)K-fold:
随机产生K个subsets的indices(train、test),然后通过下面方式获取subsets的具体内容:
2)Stratified K-fold(分层kfold):
对于每个subsets,要求每个类别的samples的数量的百分比大致相等。
3)Leave-One-Out(LOO):
As a general rule, most authors, andempirical evidence, suggest that 5- or 10- fold cross validation should be preferred to LOO.
4)Leave-P-Out(LPO):
creates all(组合关系) the possible training/test sets by removing ![]() samples from the complete set.
samples from the complete set.
5)Leave-One-Label-Out (LOLO):
6)Leave-P-Label-Out(LPLO):
7)Random permutations cross-validation a.k.a. Shuffle & Split:
打乱,再随机;有可能同一个sample在任何一个subsets中都不出现,也可能出现多次。ShuffleSplit is thus a good alternative to KFold cross validation that allows a finer control on the number of iterations and the proportion of samples in on each side of the train / test split.
8)Predefined Fold-Splits / Validation-Sets:
3、A note on shuffling
(如果数据不是任意顺序<例如相同label的sample排在一起>,CV之前shuffle非常必要。但如果samples不独立或者分布不同,shuffle反而有害,例如news articles按发布时间排序,shuffle可能造成test set与training set相似<close in publish time>。)
If the data ordering is not arbitrary (e.g. samples with the same label are contiguous), shuffling it first may be essential to get a meaningful cross- validation result. However, the opposite may be true if the samples are not independently and identically distributed. For example, if samples correspond to news articles, and are ordered by their time of publication, then shuffling the data will likely lead to a model that is overfit and an inflated validation score: it will be tested on samples that are artificially similar (close in time) to training samples.
Some cross validation iterators, such as KFold, have an inbuilt option to shuffle the data indices before splitting them. Note that:
- This consumes less memory than shuffling the data directly.(更省memory)
- By default no shuffling occurs, including for the (stratified) K fold cross- validation performed by specifying cv=some_integer to cross_val_score, grid search, etc. Keep in mind that train_test_split still returns a random split.(默认不shuffle,但train_test_split返回的仍然是随机indices)
- The random_state parameter defaults to None, meaning that the shuffling will be different every time KFold(..., shuffle=True) is iterated. However,GridSearchCV will use the same shuffling for each set of parameters validated by a single call to its fit method.(random_state默认为None,意味着每个fold都重新shuffle一次。单GridSearchCV却不受该参数的影响。)
- To ensure results are repeatable (on the same platform), use a fixed value for random_state.
4、Cross validation and model selection
Cross validation iterators can also be used to directly perform model selection using Grid Search for the optimal hyperparameters of the model. This is the topic if the next section: Grid Search: Searching for estimator parameters.(翻译文章参考:http://blog.csdn.net/mmc2015/article/details/47100091)