Denosing Autoencoder原理以及结果简介
本文是看了,bengio的论文Extracting and composing robust features with denoisingautoencoders,整理而得。
文章开始先提出什么是好的特征,或者好的特征应该具有的性质:
1最大化的保留原始信息,
2稀疏性
3 鲁棒性,即使局部输入数据被污染的时候,也能够学习到稳定的特征表达
原理简介:
Denosing autoencoder就是为了学习到较鲁棒的特征,在网络的可视层(即数据的输入层)按照一定比例,引入随机噪声;然后通过autoencoder网络,是重构误差Lh最小,从而重构出原始数据,学习到更加鲁棒性的特征y。

作者尝试从流行学习(例如PCA等),信息论,生成模型的角度解释da算法;但是看了半天重构误差的推导过程;先是假设一堆分布函数,然后通过提高对数似然的下限来达到最大化X和Y之间的互信息,具体没看明白。
实验结果:
作者在基本minist数据集,以及经过变换的数据集上面做测试,结果如图:
其中加粗的部分为,测试结果最好的算法。可以看出sda算法在多个数据集中达到了state-of-art的水平。
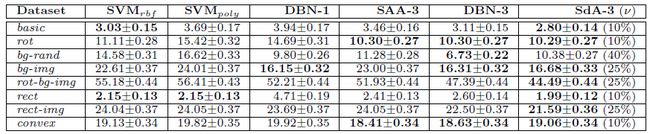
其中SAA是sda在加噪比例为0时的情况,可以看出加噪后分类错误率明显降低;达到了说明加噪后学习的特征不仅具有鲁棒性,还具有更好的可分性;但是从sda算法中不同的加噪比例来看,本来需要很多trick的dl网络,这次又多了一个加噪比例参数需要调整。
结果分析:
没有加噪的数据,很多学习到的特征很相似,并且没有明显的轮廓特征(部分乱成一团,例如下图a中,每个patch相似性很大,而且不具有明显的特征结构);而加噪后学习到的噪声,捕捉到了相互不同的特征;并且提高加噪比例,可以学习到局部性更少的特征,对于大的结构更加敏感。如图所示

所以加噪声的无监督特征学习帮助捕捉更加有意义的特征。
此外,通过实验结果对比,RBM学习到的特征也具有鲁棒性,作者分析是因为RBM的随机本质,在训练过程中加入了噪音。