低分辨率、非对齐、视频监控数据中的人脸识别(LFW, YTF)+CVPR2013
现有的人脸识别数据库,像Yale,YaleB,ORL等人脸数据库,分辨率高,良好对齐等datasets。。。
最近这方面的paper越来越少,逐渐向低分辨率、大数据库等监控中的images,更具挑战性的数据集转移~
最近看到一篇中科院的一篇CVPR2013中的paper:
“Fusing robust face region descriptors via multiple metric learning for face recognition in the wild, zhen cui, wen li, dong xu, shiguang shan, xilin chen” CVPR2013
作者地址:http://vipl.ict.ac.cn/members/zcui (并附有源码~ )
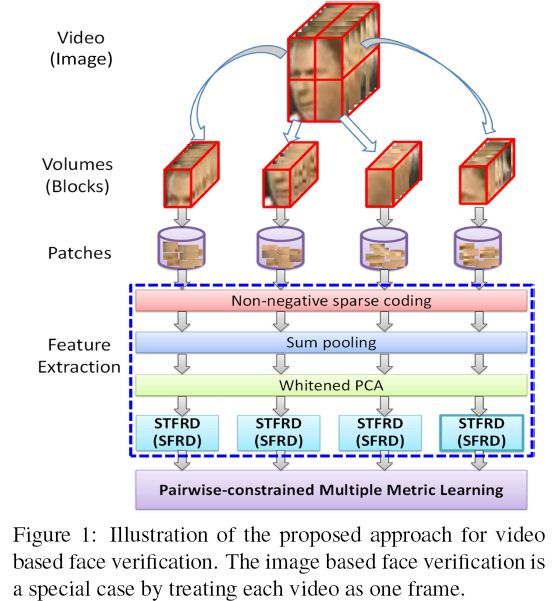
本文主要提供了一种抽取人脸区域描述子的方法。具体来说:
1、把每个图像分割为若干个空间块。
2、通过非负稀疏编码。。来表示每个块。 (represent each block by sum-pooling the nonnegative sparse codes of position-free patches sampled with the block.)
3、利用Whitened PCA 进行特征降维,从而产生区域人脸区域描述子。
4、介绍一种新的度量学习方法~ 名为:pairwise-constrained multiple metric learning。有效的整合所有block的脸部区域描述子。
最后再LFW 和 YouTube Faces (YTF)验证其方法。
LFW (Labeled Faces in the Wild)
YTF (YouTube Faces)
人脸识别的方法可以大致分为两种:
基于全局特征的方法:Eigenfaces、FisherFace
基于局部特征的方法:Gabor、LBP等 BoF (Bag of Feature)
在本文中,为了处理图像中的非对齐问题:
一方面,把每张图像分割为block集合,仅比较对应block的特征。
另一方面,每个block表示为无位置信息的patch集合
具体来说:
首先采用非负的稀疏编码,根据K-mean聚类得出的视觉字典,来量化每个patch;
然后通过sumpooling重构稀疏,为每个图像抽取TF(Token-Frequency)特征;
最后利用WPCA,降维,去噪,抽取空间脸部区域描述子。
废话少说,上图吧~ (发现中科院山老师那边,写文章很喜欢配个框架图,正应了无图不成文的说法,图示很清晰~)
分类方法:SVM+RBF kernel
这篇文章描述子的提取等,其实有分层的概念在里面,patch---》block便是分层的意思,另外一个便是局部信息,这是一个趋势:分层+局部
大致思想便是如此,其他便是公式和推导和细节~
这篇paper写的细节还是蛮清楚的~
但是dataset是个难点~ follow也是个问题~ 除非自己去crop and resize all images.