深度学习总结——感自中科院吴怀宇教授
深度学习总结——
感自中科院吴怀宇教授
参考http://www.sigvc.org/bbs/forum.php?mod=viewthread&tid=3322
提示:
图灵测试(Turing Testing)是计算机是否真正具有人工智能的试金石。“计算机科学之父”及“人工智能之父”英国数学家阿兰·图灵(1912—1954)在1950年的一篇著名论文《机器会思考吗?》里提出图灵测试的设想。即把一个人和一台计算机分别隔离在两间屋子,然后让屋外的一个提问者对两者进行问答测试,如果提问者无法判断哪边是人,哪边是机器,那就证明计算机已具备人的智能。
视觉系统的信息分级处理
David Hubel和Torsten Wiesel(1981年诺贝尔医学奖获得者)发现了人的视觉系统的信息处理是分级的。如图1所示,从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。即高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化,越来越能表现语义或者意图。大脑是一个深度架构,认知过程也是深度的。

图1 人脑的视觉处理系统 (图片来源:blogspot)
启发:大脑的工作过程,或许是一个不断迭代、不断抽象概念化的过程,如图2所示。
例如,从原始信号摄入开始(瞳孔摄入像素),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定眼前物体的形状,比如是椭圆形的),然后进一步抽象(大脑进一步判定该物体是张人脸),最后识别眼前的这个人。这个过程其实和我们的常识是相吻合的,因为复杂的图形往往就是由一些基本结构组合而成的。
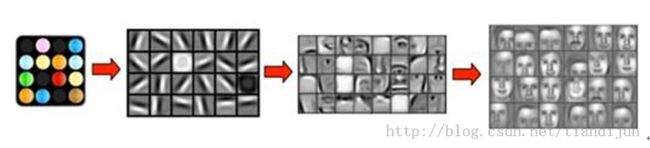
图2 视觉的分层处理结构 (图片来源:Stanford)
深度学习(Deep Learning)通过组合低层特征形成更加抽象的高层特征(或属性类别)。例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层次表达,例如边缘检测器、小波滤波器等,然后在这些低层次表达的基础上,通过线性或者非线性组合,来获得一个高层次的表达。声音方面,研究人员从某个声音库中通过算法自动发现了20种基本的声音结构,其余的声音都可以由这20种基本结构来合成!
机器学习是人工智能的一个分支,就是通过算法,使得机器能从大量历史数据中学习规律,从而对新的样本做智能识别或对未来做预测。深度学习作为机器学习研究中的一个新的领域,其动机在于建立可以模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如,图像、声音和文本。深度学习是无监督学习的一种(解释见下文)。
深度学习的“深度”是相对于以前的机器学习方法的“浅层学习”。深度学习可以简单理解为传统神经网络(NeuralNetwork)的发展。如图3所示,深度学习与传统的神经网络的相同之处在于,深度学习采用了与神经网络相似的分层结构:一个包括输入层、隐层(可单层、可多层)、输出层的多层网络,只有相邻层节点之间有连接,而同一层以及跨层节点之间相互无连接。
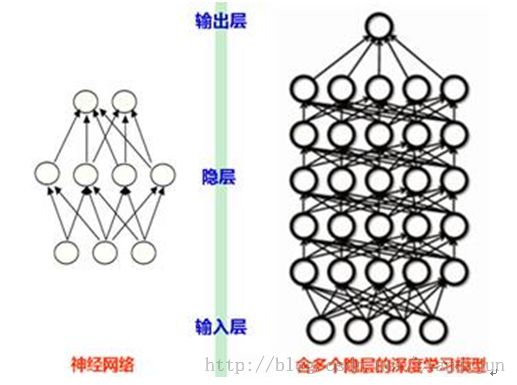
图3 传统的神经网络与深度神经网络
提示:
神经网络包含输入层、输出层以及中间的若干隐层(Hidden Layer),每层都有若干结点及连接这些点的边,在训练数据集上会学习出边的权值,从而建立模型。随着边所表征的函数的不同,可以有各种不同的神经网络。
神经网络(如采用误差反向传播算法:Back Propagation,简称BP算法)在层次深的情况下性能变得很不理想(传播时容易出现所谓的梯度弥散Gradient Diffusion,根源在于非凸目标代价函数导致求解陷入局部最优,且这种情况随着网络层数的增加而更加严重),所以只能处理浅层结构(小于等于3),从而限制了性能。
20世纪90年代,有更多各式各样的浅层模型相继被提出,如只有一层隐层节点的支撑向量机(SVM,Support Vector Machine)和Boosting,以及没有隐层节点的最大熵方法(例如LR,Logistic Regression)等,在很多应用领域取代了传统的神经网络。
浅层结构算法有很多局限性:
1) 在有限样本和计算单元情况下对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受到一定的制约。
2) 浅层模型需要依靠人工来抽取样本的特征。手工地选取特征费力、很大程度上靠经验和运气。
提示:
实现对象的分类前需要抽取一些特征正确表达一个对象,深度学习可以自动地学习特征,将特征和分类器结合到一个框架中,用数据去学习特征,在使用中减少了手工设计特征的巨大工作量。深度学习别名:无监督特征学习(Unsupervised Feature Learning),意思就是不需要通过人工方式进行样本类别的标注来完成学习。
提示:
准确地说,深度学习首先利用无监督学习对每一层网络进行逐层预训练(LayerwisePre-Training);每次用无监督学习只训练一层,并将训练结果作为更高一层的输入;最后用监督学习去调整所有层。
深度学习特点:
1) 深度学习通过学习一种深层非线性网络结构,只需简单的网络结构即可实现复杂函数的逼近,能从大量无标注样本集中学习数据集本质特征的能力。
2) 深度学习能够获得可更好地表示数据的特征,同时由于模型的层次深(通常有5层、6层,甚至10多层的隐层节点)、表达能力强,因此有能力表示大规模数据。
成功应用:
对于图像、语音这种特征不明显(需要手工设计且很多没有直观的物理含义)的问题,深度模型能够在大规模训练数据上取得更好的效果。深度学习使得在语音识别方面错误率下降了大约30%,取得了显著的进步。相比于传统的神经网络,深度神经网络作出了重大的改进,在训练上的难度(如梯度弥散问题)可以通过“逐层预训练”来有效降低。
缺点:
1)需要结合特定领域的先验知识,需要和其他模型结合才能得到最好的结果
2)针对自己的项目去仔细地调参数,tuning
3)可解释性不强,像个“黑箱子”一样不知为什么能取得好的效果,以及不知如何有针对性地去具体改进,而这有可能成为产品升级过程中的阻碍。
科研发展:
1) Yahn Lecun在1993年提出的卷积神经网络(ConvolutionalNeural Network:CNN)是第一个真正成功训练多层网络结构的学习算法,但应用效果一直欠佳。
2) 2006年,Geoffrey Hinton基于深度置信网(Deep Belief Net:DBN)——其由一系列受限波尔兹曼机(RestrictedBoltzmann Machine:RBM)组成,提出非监督贪心逐层训练(Layerwise Pre-Training)算法,应用效果才取得突破性进展,
3) Ruslan Salakhutdinov提出的深度波尔兹曼机(DeepBoltzmann Machine:DBM)重新点燃了人工智能领域对于神经网络(NeuralNetwork)和波尔兹曼机(BoltzmannMachine)的热情,掀起了深度学习的浪潮。
从目前的最新研究进展来看,只要数据足够大、隐层 足够深,即便不加“Pre-Training”预处理,深度学习也可以取得很好的结果,反映了大数据和深度学习相辅相成的内在联系。此外深度学习也可用于带监督的情况(也即给予了用户手动标注的机会),目前带监督的CNN方法目前就应用得越来越多,乃至正在超越DBM。
如果 隐层足够多(“足够深”),选择适当的连接函数和架构,深度学习能获得很强的表达能力。近年来,得益于大数据、计算机速度的提升、基于MapReduce的大规模集群技术的兴起、GPU的应用以及众多优化算法的出现,耗时数月的训练过程可缩短为数天甚至数小时,深度学习才在实践中有了用武之地。
研究成果:
1)2012年6月,由著名的斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家Jeff Dean共同主导,用16,000个CPU Core的并行计算平台去训练含有10亿个节点的深度神经网络(DNN,Deep Neural Networks),使其能够自我训练,对2万个不同物体的1,400万张图片进行辨识。在开始分析数据前,并不需要向系统手工输入任何诸如“脸、肢体、猫的长相是什么样子”这类特征。系统自己发明或领悟了‘猫’的概念。”
2)2014年3月,基于深度学习方法,Facebook的 DeepFace 项目使得人脸识别技术的识别率已经达到了 97.25%,只比人类识别 97.5% 的正确率略低一点点,该项目利用了 9 层的神经网络来获得脸部表征,神经网络处理的参数高达1.2亿。
展望:
面对海量的大数据,无论是推荐系统还是3D模型检索,也许只有比较复杂的模型、表达能力强的模型才能充分发掘海量数据中蕴藏的有价值信息。
深度学习(即所谓“深度”)应大数据(即所谓“广度”)而生,给大数据提供了一个深度思考的大脑,而3D打印(即所谓“力度”)给了智能数字化一个强健的躯体,三者共同引发了“大数据+深度模型+3D打印”浪潮的来临。