大数据学习笔记——Hadoop1.x基本概念和安装
Hadoop生态圈十分庞大,最近Spark又很火热并且速度也是Hadoop的百倍级别的,曾想就只看Spark吧,后来发现还是需要从基础打起,Spark是基于内存的,其没有存储系统,需要添加第三方分布式存储,而大多数Spark项目都安装在Hadoop上,因此学习Hadoop是必然的,学习Hadoop生态圈也是必须的。
一、概念性知识
1.概念
Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
2.Hadoop版本

Hadoop2.x相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:
- HDFS的NameNodes可以以集群的方式布署,增强了NameNodes的水平扩展能力和可用性;
- MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator)。
Hadoop1.x与Hadoop2.x在架构上是不同的,hadoop社区对这两个版本都在提供维护更新,所以Hadoop2.x的某些版本不一定比Hadoop1.x要新。
过去很多公司都在使用Hadoop1.x,目前在逐步进行Hadoop2.x的更新换代,因此在学习hadoop时,hadoop1.x的版本也是有必要去学习的。
3.Hadoop组成
Hadoop主要由HDFS、MapReduce、HBase组成。
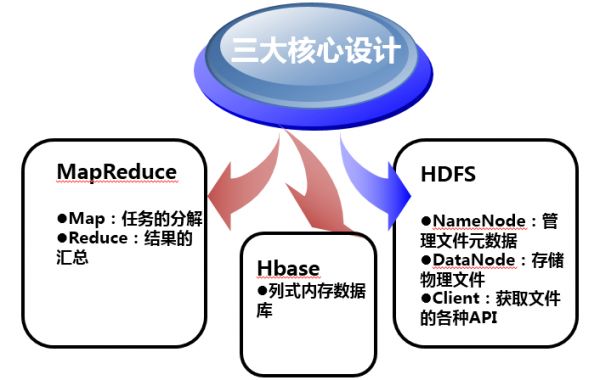
4.Hadoop中需要学习的内容
- Core:一套分布式文件系统以及支持Map-Reduce的计算框架
- Avro:定义了一种用于支持大数据应用的数据格式,并为这种格式提供了不同的编程语言支持。
- HDFS:Hadoop分布式文件系统
- Map/Reduce:是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
- ZooKeeper:是高可用的和可靠的分布式协同系统。
- Pig:建立于Hadoop Core之上为并行计算环境提供了一套数据工作流语言和执行框架(目前使用的人数少)。
- Hive:是为提供简单的数据操作而设计的下一代分布式数据仓库。它提供了简单的类似SQL的语法的HiveQL语言进行数据查询。
- HBase:建立于Hadoop Core之上提供一个可扩展的数据库系统。
- Flume:一个分布式、可靠和高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据。
- Mahout:是一套具有可扩充能力的机器学习类库。
- Sqoop:是Apache下用于RDBMS和HDFS互相导数据的工具。
5.HDFS介绍
1)概念
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
2)HDFS的设计特点是
- 大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
- 文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
- 流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
- 廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
- 硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
3)HDFS的关键元素
NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在Hadoop2.*开始支持activity-standy模式—-如果主NameNode失效,启动备用主机运行NameNode。
DataNode:分布在廉价的计算机上,用于存储Block块文件。
Block:将一个文件进行分块,通常是64M。

4)HDFS其他概念
SecondayNameNode:它不是NameNode的备份(但可以做备份),它的主要工作是帮助NameNode合并edits log,减少NameNode的启动时间。
edits:日志文件,记录引发元数据改变的操作。
fsimage:元数据的镜像文件,可以理解为元数据保存在磁盘上的一个副本。
SecondaryNameNode合并fimage与edits log时间:
A)根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒。
B)根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大值默认是64MB。
SecondaryNameNode合并流程:

注:
第一步:secondary namenode请求namenode停止使用edits,暂时记录在edits.new文件中
第二步:secondary namenode从namenode复制fsimage、edits到本地
第三步:secondary namenode合并fsimage、edits为fsimage.ckpt
第四步:secondary namenode发送fsimage.ckpt到namenode
第五步:namenode用新的fsimage覆盖旧的fsimage,用新的edits覆盖旧的edits
第六步:更新checkpoint时间
到这里fsimage更新完毕,即保证了primary正常服务,也完成了fsimage的更新。
5)HDFS架构图:

注:Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的。
6)HDFS写文件流程:
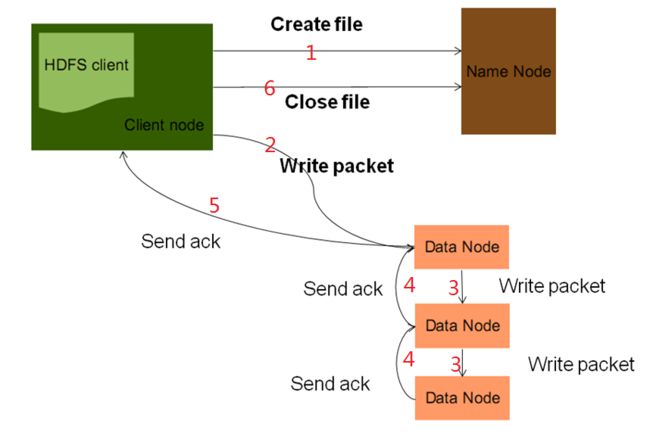
7)HDFS读文件流程:

二、Hadoop1.x安装
1.Linux环境配置
1)Ubuntu环境配置
安装好Ubuntu后,默认是不开启root用户的,下面开启root用户:
ctrl+alt+T开启控制台
$ sudo -s #进入root用户权限模式 #在文件中开启root登录模式,在文件中添加greeter-show-manual-login=true $ sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf

#修改root用户密码 $ sudo passwd root

重启系统,即可以root身份登录系统。

2)安装JDK
#解压jar包到/usr/lib文件夹中 tar -zvxf jdk-8u66-linux-i586.tar.gz /usr/lib
解压后,目录为/usr/lib/jdk1.8.0_66
编辑Ubuntu环境变量文件~/.bashrc,在其中添加JAVA环境变量

2.Hadoop安装
我们在此安装的是hadoop1.2.1版本,根据其官方文档http://hadoop.apache.org/docs/r1.2.1/cluster_setup.html 我们完成如下操作。
1)安装必备软件ssh、rsync$ sudo apt-get install ssh
$ sudo apt-get install rsync
2)解压hadoop1.2.1tar包
$ tar -zvxf hadoop-1.2.1.tar.gz $ mv hadoop-1.2.1 /usr/lib/hadoop
3)修改主机名
#查看主机名 $ hostname #或 $ uname -n #临时修改主机名 $ hostname 新主机名 #永久修改主机名,编辑文件添加入主机名 $ gedit /etc/hostname

4)修改hosts文件
hosts文件中添加主机名对应的IP,如下图:

/etc/hostname与/etc/hosts的区别 /etc/hostname中存放的是主机名,hostname文件的一个例子:
namenode/etc/hosts存放的是域名与ip的对应关系,域名与主机名没有任何关系,你可以为任何一个IP指定任意一个名字,hostname文件的一个例子:
127.0.0.1 localhost
127.0.1.1 namenode
5)修改主机IP地址为静态地址

注:上述的步骤在datanode中的节点也是一样的,就不在此在祥写了,如下图datanode的hostname、ip地址、hosts的设置。

datanode2的配置仅是IP地址不一样。
6)设置SSH免密码登录
SSH免密码登录主要是为了方便集群间互相访问。
#生成免密码登录秘钥 $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa

#将生成的公共秘钥拷贝到 ~/.ssh/authorized_keys目录下 $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

从图中我们可以看到,ssh localhost登录就是免密码的了,但是我们假设的是伪分布模式的集群,因此需要将此公钥拷贝到datanode节点下面。
#将namenode下生成的公共秘钥id_dsa.pub放到datanode1的/root/tool目录下 $ scp ~/.ssh/id_dsa.pub >> root@ datanode1:/root/tool
namenode控制端:
![]()
datanode1控制端:

#在datanode1 /root/tool目录下的id_dsa.pub文件内容加入到~/.ssh/authorized_keys文件中 $ cat /root/tool/id_dsa.pub >> ~/.ssh/authorized_keys
我们再在root@namenode中登录datanode1,此时则不用在输入密码

7)hadoop文件配置
修改conf/hadoop-env.sh文件,定义JAVA_HOME变量

修改conf/core-site.xml文件,配置namenode信息,修改HDFS的工作目录
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 设置namenode访问路径 -->
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<!-- 设置HDFS工作目录,默认的工作目录会在Linux的tmp工作目录,由于Linux的tmp目录在Linux重启时会自动清空,因此需要对其进行设置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2.1</value>
</property>
</configuration>
修改conf/hdfs-site.xml文件,修改hadoop的文件存储副本数
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
修改slaves文件,添加datanode节点ip

修改masters文件,添加seconderynode节点

8)启动Hadoop
格式化,在/usr/lib/hadoop-1.2.1/bin目录下运行下面命令
#namenode format操作是使用hadoop分布式文件系统前的步骤。如果不执行这个步骤,无法正确启动分布式文件系统。 $ ./hadoop namenode -format
启动hadoop
$ ./start-dfs.sh
下图为启动后的截图:
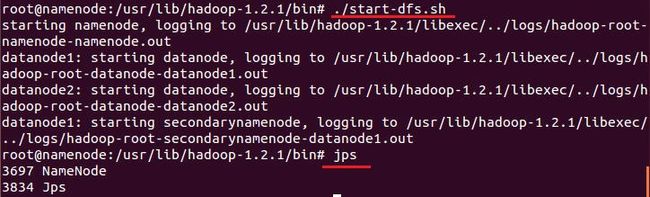
在datanode1虚拟机上也可看到启动的进程

hadoop启动后,我们可以通过浏览器去访问,默认hadoop的http的端口是50070,而端口9000是其ipc协议端口

停止hadoop服务
$ ./stop-dfs.sh
3.碰到的问题或知识普及
1)在以root方式登录时,出现“error found when loading/root/.profile”错误


2)ssh登录不成功

登录不成功的原因是因为SSH默认是只允许证书登陆的方式,所以我们需要修改/etc/ssh/sshd_config文件,开启root用户登录权限,解决方法是:
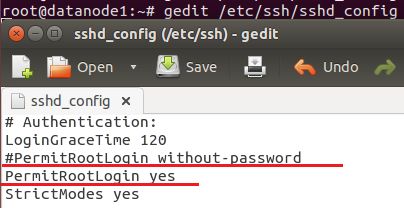
#重启SSH服务 $ sudo service ssh restart

3)ssh远程登录不成功,原因是防火墙开着,关闭防火墙即可
#查询防火墙版本 $ sudo ufw version #查询防火墙状态 $ sudo ufw status #开启/关闭防火墙 $ sudo ufw enable/disable #打开或关闭某个端口 $sudo ufw allow smtp #允许所有的外部IP访问本机的25/tcp (smtp)端口 $sudo ufw allow 22/tcp #允许所有的外部IP访问本机的22/tcp (ssh)端口 $sudo ufw allow from 192.168.1.100 #允许此IP访问所有的本机端口 $sudo ufw allow proto udp 192.168.0.1 port 53 to 192.168.0.2 port 53 $sudo ufw deny smtp #禁止外部访问smtp服务

4)jps命令介绍
jps(Java Virtual Machine Process Status Tool)是JDK 1.5版本及以后提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上简单察看当前java进程的一些简单情况。
unix系统里的ps命令,这个命令主要是用来显示当前系统的进程情况,有哪些进程,及其 id。jps 也是一样,它的作用是显示当前系统的java进程情况,及其id号。一般可以通过它来查看我们到底启动了几个java进程(因为每一个java程序都会独占一个java虚拟机实例),和他们的进程号(为下面几个程序做准备),并可通过opt来查看这些进程的详细启动参数。