车牌识别
.车牌预处理
车牌预处理过程的好坏直接影响到车牌图像进行后期处理过程,比如车牌字符分割等。车牌预处理也是尽可能的消除噪声,减少后期处理带来的不必要的麻烦。
输入的车牌是24Bit的BMP真彩色图像,车牌照有黄底黑字,蓝底白字等颜色,为了将这些车牌图像一并处理,就要先将车牌进行灰度化处理,然后进行二值化(黑白)处理。
![]()
图4-1 原始图像
将采集的车牌图像进行预处理,为了方便起见,这里采用的是BMP格式的图片,我将采集的车牌图像进行了裁剪处理,裁剪后的图片如下:
由于中国大部分的车牌是第一个是汉字,第二个到第七个是字母或数字,这就可以将车牌图像识别过程分成两部分处理,第一部分是识别汉字的过程,第二部分是识别字母和数字的过程,由于汉字笔画较多,同字母或数字的处理过程有所不同。所以我这里就先处理字母或数字的过程。
除汉字外,在第一个字母和第二个数字的中间有个一点,所以在字符分割的时候要考虑去掉中间的点。车牌图像总体来说比较清晰,大型民用车,牌照为黄底黑字,小型民用车,牌照为蓝底白字 ,由于字符与背景颜色对比比较明显,所以将车牌分割开来比较容易。由于有些车牌的上面和下面也有螺丝之类的东西将车牌固定,所以在将车牌分割的时候,通过水平扫描跳跃点的方法,可以去除掉,以便最后将车牌进行分割,去除这些干扰。
在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。一般有四种方法对彩色图像进行灰度化。
1. 分量法。就是将每个分量上的颜色值即RGB3种颜色提取出来。即:将彩色图像中的三分量的亮度作为三个灰度图像的灰度值,可根据应用需要选取一种灰度图像。f1(i,j)=R(i,j) f2(i,j)=G(i,j) f3(i,j)=B(i,j)其中fk(i,j)(k=1,2,3)为转换后的灰度图像在(i,j)处的灰度值。
2.最大值法。选取彩色图像中的三分量中(RGB)的颜色的最大值作为灰度图的灰度值。即:f(i,j)=max(R(i,j),G(i,j),B(i,j))。
3.平均值法。 将彩色图像中的三分量亮度求平均得到一个灰度图f(i,j)=(R(i,j)+G(i,j)+B(i,j))/3。
4.加权平均法。根据重要性及其它指标,将三个分量以不同的权值进行加权平均。由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。f(i,j)=0.30R(i,j)+0.59G(i,j)+0.11B(i,j))。
以上四种处理过程,在车牌预处理的过程中,我选择加权平均值法。效果如下:


图4-2 原始图像 图4-3灰度图像
如上图,是将图中的原始图像进行加权平均值处理后的灰度图像。
关键代码如下:
for(i = 0;i < Height; i++)
{
for(j= 0;j < Width*3; j+=3)
{
ired = (unsigned char*)lpDibBits + LineBytes* i + j + 2;
igreen= (unsigned char*)lpDibBits + LineBytes * i + j + 1;
iblue = (unsigned char*)lpDibBits + LineBytes* i + j ;
lpdest[i*Width+ j/3]= (unsigned char)((*ired)*0.299 + (*igreen)*0.588 + (*iblue)*0.114);//加权平均值计算处理
}
}
二值化处理。二值化处理即将BMP图像进行黑白处理,使背景与字符区分开。由于灰度化后的图像是0-255之间的颜色值。而进行二值化处理的过程就是将此图像的颜色分成黑色值0和白色值255两种颜色。为了将背景与车牌字符分开,要设定一个阈值。设定阈值是关键。如果选取的二值化的阈值不当则就有可能不能将车牌图像中的背景与文字进行明显分开,所以这时二值化的阈值选取就显得非常重要。根据试验,我设定的阈值为
125。二值化后的效果如下:

图4-7 二值化后图像
如上图是测试蓝底白字和黄底黑字的车牌图像的二值化后的效果。通过将图像进行二值化后,可以明显将背景与车牌字符进行分开。
二值化处理的关键代码如下:
for(i = 0; i < Height; i++)// 每行
{
for(j = 0; j < Width; j++)// 每列
{
// 指向DIB第i行,第j个象素的指针
lpSrc = (unsigned char*)lpDibBits+LineBytes *(lHeight - 1 - i) + j;
// 判断是否小于阈值
if ((*lpSrc) < bThre)
{
*lpSrc = 0; // 直接赋值为0,即黑色
}
else
{
*lpSrc = 255; // 直接赋值为255,即白色
}
}
}
2.字符分割
由于车牌图像做了细化处理后,可以进行水平扫描和垂直扫描将字符分开,水平扫描确定图片的上下限,垂直扫描可以确定图片中字符的左右坐标。根据车牌的特征,先将车牌图像进行水平扫描跳跃点,即水平相邻的两个像素,如果不相同则认为有一个跳跃点,记录次数加1,由于车牌上面有时候会有两个白点,所以通过判断跳跃点的个数,可以将上面的两个白点去掉[9]。如图,扫描处理的跳跃点统计如下:
![]()
图4-10 原始图像,上面有两个白点
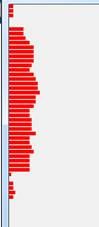
图4-11水平扫描跳跃点的个数统计
统计结果:4 4 4 0 0 14 14 16 20 24 24 24 24 22 20 24 26 28 28 30 2626 24 20 20 22 22 22 26 20 20 22 24 20 20 20 20 2 0 4 4 6 4像素。扫描结果数量个数为的车牌高度的个数。
从上往下查找,根据实验结果,设置当水平跳跃点超过10个的时候,作为车牌字符截取的上限。当从下往上查找,当跳跃点超过8个的时候可以作为车牌字符截取的下限。通过上面的过程,基本可以确定车牌的上部和下部。同样,分割车牌字符左右边界时,通过垂直扫描过程,由于数字和字母具有连通性,所以分割数字和字母比较容易。通过垂直扫描过程,统计黑色像素点的个数,由于两个字符之间没有黑像素,所以可以作为字符分割的界限。垂直扫描过程如下图:

陕 A . 5 P 0 7 2
图4-12 垂直扫描车牌字符黑像素个数统计
通过上面的统计可以很容易的把字符作用边界进行分割开来。通过水平扫描跳跃点和垂直扫描像素点,可以分开字符。但是其中还有些问题。比如有些汉字不是联通性,如“陕”字,左耳旁和右边的“夹”字,有时候扫描的时候会有空隙,所以我这里在扫描第一个汉字的时候,要多加一些处理,当“陕”的左耳旁的宽度不为总宽度的1/12时候,我继续向下扫描,直到找到为零的像素。还有就是A与5之间会有一个“.”号,这个可以通过扫描的宽度不为宽度的3/8时,我可以认为是中间的“.”号。所以通过以上的处理,基本能把大部分的车牌图像字符进行分割。字符分割后的效果如下图所示:
![]()
图4-13字符分割图像
字符分割关键代码如下:
//如果距离少于宽度的1/12,则计为无效
intwid = lWidth/13;
intxx=0,pos=0;
intflag = 0;
intsuccess = 0;
for(i=0;i<lWidth;)
{
while(VCount[i]==0)i++;
if((i-1)<0)
posi[k++]=i;
else
posi[k++]=i-1;
xx=0;
while(VCount[i]!=0&& i<lWidth) i++;
if(flag==0)
{
pos= i;
while(VCount[i]==0){i++;xx++;}
if(xx < (wid/4))
{
str.Format("xx=%d wid/4=%d i=%dposi[k-1]=%d",xx,wid/4,i,posi[k-1]);
MessageBox("汉字有分割"+str);
xx=0;
while(VCount[i]!=0){i++;xx++;}
if(xx<=8)
{
xx= 0;
while(VCount[i]==0){i++;xx++;}
if(xx<(lWidth/16))
while(VCount[i]!=0 && i<(lWidth/8)) i++;
}
}
else
{
i= pos;
}
}
flag=1;
if(i>= lWidth)
{
posi[k++]=i-1;
}
else
{
posi[k++]=i+1;
}
//如果是字符第二个和第三个字符中间的点,去除。如果是1,宽度增加
if(posi[k-1]-posi[k-2]<=wid)
{
if(i<=(lWidth/8*3))
{
intx = posi[k-1]-posi[k-2]; k=k-2;
str.Format("%d%d %d %d",x,wid,i,BottomLine-TopLine);
}
else
{
posi[k-1]= posi[k-1]+wid/3;
posi[k-2]= posi[k-2]-wid/3;
}
}
if(k>=14)
{
success= 1;
break;
}
}
if(success== 0)
{
MessageBox("字符分隔出错,程序结束识别过程!");
}
3.归一化处理
字符分割的好坏关系到后面归一化处理关键。如果字符分割不成立,归一化处理过程也就不能成功。刚开始实验的时候,我先进行的细化处理,然后再进行归一化处理,但是归一化处理后有,字符基本失去了原来的骨架结构,所以我这里先进行归一化处理。
所谓归一化处理,就是为了在分割字符时,字符大小不相同,所以要将字符归一化为25×50像素大小的图像。图像x轴缩放比率为 ,y轴缩放比率为 ,原图像宽度和高度为lWidth,lHeight[12]。缩放比率由公式:
在放大或缩小图像过程中,产生的像素可能在原图中不能找到相应的像素点。这样就必须采用插值处理的方法。一般插值处理的方法有两种,一种是直接赋值为与它最相邻的像素值,另一种则通过插值算法来计算相应像素值。第一种方法计算过程较简单效率高,但是效果不是很好,比如有时候会出现马赛克现象;所以,这里采用第二种方法,虽然预算量有点复杂,但是最后归一化后的字符不会失真。对后面做细化处理过程做好了铺垫。通过实验得出,采用双线性插值法比最近邻插值法效果好,所以本文中归一化采用双线性插值法。

图4-14 上面为原图像二值化后的结果,下面图像为归一化后的结果
归一化关键代码如下:
//针对图像每行进行操作
for(i= 0; i < NewHeight; i++)
{
//针对图像每列进行操作
for(j= 0; j < NewWidth; j++)
{
//指向新DIB第i行,第j个象素的指针
//注意此处宽度和高度是新DIB的宽度和高度
lpDst = (char*)lpNewDIBBits + NewLineBytes * (NewHeight - 1 - i) + j;
x= j / fXZoomRatio;
y= i / fYZoomRatio;
if(tag)
{ //tag=1,则执行以下的最近邻插值代码
i0= (LONG) (y + 0.5);
j0= (LONG) (x + 0.5);
//判断是否在源图范围内
if((j0 >= 0) && (j0 < Width) && (i0 >= 0) && (i0< Height))
{
//指向源DIB第i0行,第j0个象素的指针
lpSrc = (char*)lpTempDIBBits + LineBytes * (Height - 1 - i0) + j0;
*lpDst= *lpSrc;
}
else
{
//对于源图中没有的象素,直接赋值为255
*((unsigned char*)lpDst) = 255;
}
}
else
{//否则,执行下面的双线性插值代码
doublem = x - LONG(x);//X方向的小数部分
doublen = y - LONG(y);//Y方向的小数部分
unsignedchar rd, ld, lu, ru;//r:右;l:左;d:下;u:上
unsignedchar pix;
ld= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y)) + LONG(x));//左下角点的像素值
rd= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y)) + LONG(x) +1);// 右下角点的像素值
lu= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y) - 1) +LONG(x));// 左上角点的像素值
ru= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y) - 1) + LONG(x) +1);// 右上角点的像素值
pix= (1 - m) * (1 - n) * ld + (1 - m) * n * lu + m * n * ru + m * (1 - n) * rd;//双线性插值,得到变换后的像素
*((unsigned char*)lpDst) = pix;//将像素值赋给目的图片
}
}
}
4.细化处理
对图像的喜欢过程实际是求图像骨架的过程。骨架是二维二值目标的重要描述,它指图像中央的骨骼部分,是描述图像几何及拓扑性质的重要特征之一。细化算法有很多。按照迭代方法,分为两类,一类是非迭代过程,一类是迭代过程。非迭代算法有基于距离变换的方法等。迭代方法是通过重复删除像素边缘,直到得到单独像素宽度的图像为止。现在用的比较多的细化算法有Hilditch、Pavlidis、Rosenfeld细化算法和索引表细化算法等[13]。下面主要介绍这四种算法。
Hilditch、Pavlidis、Rosenfeld细化算法:这类算法则是在程序中直接运算,根据运算结果来判定是否可以删除点的算法,差别在于不同算法的判定条件不同。
其中Hilditch算法比较适用于二值图像,是用的比较普遍的细化算法,在本文中我用了该算法后发现会有马赛克效果,所以本文中没有引用该算法; Pavlidis算法用位运算进行特定模式的匹配,所得的骨架是8连接的,使用于0-1二值图像 ;Rosenfeld算法是一种并行细化方法,所得的骨架形态是8-连接的,使用于0-1二值图像 。 后两种算法的效果要更好一些,但是处理某些图像时效果一般,第一种算法适用性强一些[13]。
索引表细化算法:经过预处理后得到待细化的图像是0、1二值图像。像素值为1的是需要细化的部分,像素值为0的是背景区域。基于索引表的算法就是依据一定的判断依据,产生一个表,然后根据要细化的点的八个邻域的情况进行匹配,若表中元素是1,若表中元素是1,则删除该点(改为背景),若是0则保留。因为一个像素的8个邻域共有256种可能情况,因此,索引表的大小一般为256种。
车牌图像进行预处理后,细化处理是关系到后面能否正确提取字符特征值的关键,所以本文中在比较了几种细化方法后,使用Rosenfeld骨架细化的方法,细化处理后可以得到图像中字符的基本骨架,不会破坏原来的连通性。
Rosenfeld细化过程主要是保持原来图像的连通性
通过归一化 后,再将图像进行细化,基本保存了字符特征的骨架特征。所以后面就是要进行的字符特征提取操作。Rosenfeld效果如下所示:
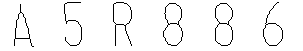
4-19大小归一化后再细化的图像
5.字符特征提取
字符特征提取的好坏,直接影响字符识别的结果。字符特征提取是一个字符识别过程必不可少的过程。目前,字符特征提取的方法很多,比如:基于网格像素统计方法[5],基于笔画,轮廓,骨架特征等。我之前做了基于网格像素统计的方法,通过实验,发现识别能力比较差,不能达到预想的结果。
针对上面的结果,我参考何兆成等人的方法,在字符细化后的基础上,通过统计字符笔画斜率特征,字符侧面深度等特征作为字符提取的特征,得到22个特征值。具体统计方法如下:
(1)基于笔画斜率的累计特征提取
字符最具代表性的特征是笔画,不同的字符有不同的笔画数量,形态,长度等,所以可将笔画的斜率累计值作为特征进行特征值提取。笔画斜率有正斜率,负斜率,零斜率三部分,分别统计字符零斜率,正斜率,负斜率的累加和。斜率的统计过程,例如从字符左边扫描,当前的扫描点为 ,下一个扫描点为为 。斜率K值计算如下:
通过上面的过程,从字符左侧开始计算斜率特征,可以得到3个特征。我这里从字符左右上下四个方向统计斜率特征可以得到12个特征值。
(2)拐点幅度累计特征提取
在字符中字符的拐点含有丰富的特征。所以统计拐点幅度特征累计和,可以得到4个特征值。拐点幅度特征 计算如下:
(3)字符轮廓深度特征提取
不同的字符在轮廓上有着明显差异。比如“S”和“C”。如下图中的“S”字符,从右侧扫描深度的时候有着有很多的凹凸信息。而字符“C”从右侧扫描的过程中,字符的中间凹陷比较明显。所以通过扫描字符四个方向的轮廓深度,也能得到4个轮廓特征值。
(4)字符跳跃点统计
由于字符“1”和“B”从左侧扫描过程中基本上没有区别。所以,为了更准确些。我这里通过统计字符水平扫描跳跃点和垂直扫描字符跳跃点来区分。很明显,字符“1”和字符“B”水平和垂直方向的跳跃点有明显的差别。以上过程可以得到2个字符特征。
通过以上分析总共可以得到22个字符特征值。将这些特征进行训练,即可得到所需的结果。关键代码如下(计算左边的特征值为例):
if(left[i]==-1)
{
while(left[i] == -1) i++;
}
begin=i;i=Height-1;
if(left[i] == -1)
{
while(left[i] == -1) i--;
}
end = i;
for(i=begin;i<=end;i++)
{
if(left[i] == -1)
left[i] = left[i+1];
}
//扫描深度
for(i=begin;i<=end;i++)
{
feature[4] += left[i];
}
feature[4]=feature[4]/10;
double *leftradio = new double[end-begin];
for(i=0;i<end-begin;i++)
leftradio[i]=0;
int n=0;
for(i=begin;i<=(end-4);i++)
{
//如果斜率为零
if(left[i] == left[i+4])
{
feature[0]++;
leftradio[n]=0;
}
else
{
leftradio[n] =(left[i]-left[i+4])/4.0;
if(leftradio[n] <0) //如果斜率小于0
feature[1]++;
else //斜率大于0
feature[2]++;
}
n++;
}
for(i=1;i<n;i++)
{
feature[3] +=fabs(leftradio[i]-leftradio[i-1]);
}
5.神经网络训练
通过提取的特征值,识别的算法有很多,包括分类器算法,模板匹配算法,基于概率统计的Bayes分类器算法,聚类分析算法等。我这里采用的是BP神经网络分类器算法。
将提取的特征值,输入层为22个特征,隐含层为80个特征,输出层为34个特征。这里去除字母“I”和“O”。字符0-9,24个字母一共34个输出。说明:由于有34个输出,所以这里理想情况下输出结果为33个0和一个1.只是1在第i个输出。i对应的数字编号如0则对应0,1对应1,9对应9,字符“A”对应10,字符“B”对应11,依次类推,字符“Z”对应33。
Matlab创建网络及训练的代码实现如下:
%创建BP网络
net_1=newff(minmax(p),[80,34],{'tansig','purelin'},'traingdm')
% 当前输入层权值和阈值
inputWeights=net_1.IW{1,1};
inputbias=net_1.b{1};
% 当前网络层权值和阈值
layerWeights=net_1.LW{2,1};
layerbias=net_1.b{2};
% 设置训练参数
net_1.trainParam.show = 50;
net_1.trainParam.lr = 0.01; %学习率
net_1.trainParam.mc = 0.9;
net_1.trainParam.epochs = 10000;%训练次数
net_1.trainParam.goal = 1e0; %目标误差
% 调用 TRAINGDM 算法训练 BP 网络
[net_1,tr]=train(net_1,p,q);
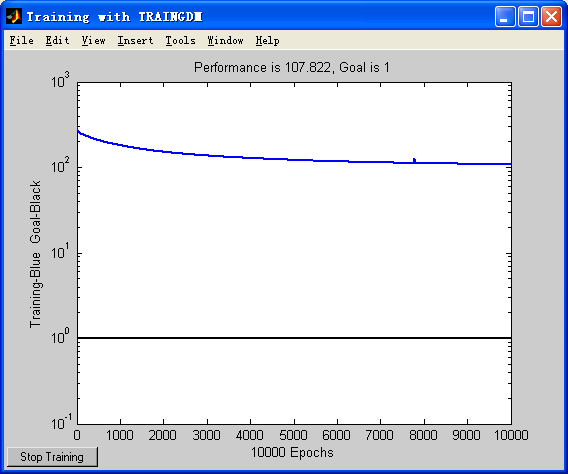
6.车牌图像识别结果测试
因为车牌中的汉字与字母数字的结构以及骨架不同,所以汉字的识别过程需要另外再做处理,所以本文处理的是车牌除汉字外的车牌图像识别过程。通过最终的测试实验结果,数字的识别结果正确率比较高,字符的识别正确率比较低一点(由于训练用的英文字符比较少)。

识别结果