Trie树进阶:Double-Array Trie原理及状态转移过程详解
前言:
Trie树本身就是一个很迷人的数据结构,何况是其改进的方案。
在本博客中我会从DAT(Double-Array Tire)的原理开始,并结合其源代码对DAT的状态转移过程进行解析。如果因此你能从我的博客中有所收获或启发,It's my pleasure.
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/49281865 -- 编程小笙
--转载请注明出处
特别说明:
0.关于Trie树的构建及使用,请移步:http://blog.csdn.net/lemon_tree12138/article/details/49177509
1.本文参考:
(0)双数组Trie树(DoubleArrayTrie)Java实现-码农场
(1)基于双数组Trie树算法的字典改进和实现 - 期刊论文 - 道客巴巴
图形展示及说明:
0.朴素Trie树示意图:

从上图中可以看到,这样的树结构是非常稀疏的。造成了资源的巨大浪费。
1.DAT节点示意图:
这里"NULL"代表结束。
DAT原理说明:
0.简介:
在学习DAT(Double-Array Trie)之前,如果你对Tire树的了解还是处在一个模糊的状态,那么我想你现在可以移步到本人的另一篇博客《数据结构:字典树的基本使用》,在对Trie树有一个基本的了解之后,再来学习本文的内容应该会更加轻松自如(如果你对Trie树已经有了或浅或深的了解,那么可以直接看下面的内容了)。
DAT的本质是一个有限自动机(因为博主在学习DAT之前对自动机的相关内容也是一知半解,在学习DAT的过程,难免有一些痛苦。博主也紧追一下这方面的知识,也会在后面的博客中写一些相关的博文).我们要构建一些状态,用于状态的自动转移。顾名思义,在DAT中用的就是双数组:base数组和check数组。双数组的分工是:base负责记录状态,用于状态转移;check负责检查各个字符串是否是从同一个状态转移而来,当check[i]为负值时,表示此状态为字符串的结束。
你可能问一个这样的问题:那么base数组和check数组是怎么来进行状态转移呢?
请看下面关于DAT双数组的计算过程。
1.DAT中双数组的计算过程:
假定有字符串状态s,当前字符串状态为t,假定t加了一个字符c就等于状态tc,加了一个字符x等于状态tx,那么有:
base[t] + c.code = base[tc]
base[t] + x.code = base[tx]
check[tc] = check[tx]
上面的几个等式就是状态base和它的转移方程。
Double-Array Trie源码解析:
0.特别说明:
DAT中的节点信息如下:
private static class Node {
int code;
int depth;
int left;
int right;
} code: 代表节点字符的编码。如:'a'.code = 97
depth: 代表节点所在树的深度。root.depth = 0
left: 代表节点的子节点在字典中范围的左边界
rigth: 代表节点的子节点在字典中范围的右边界
1.DAT的创建
和Trie树一样,DAT的创建只是创建Root的过程。如下:
public int build(List<String> _key) {
key = _key;
...
resize(65536 * 32);
...
Node root_node = new Node();
root_node.left = 0;
root_node.right = keySize;
root_node.depth = 0;
...
return error_;
}
2.为节点parent生成子节点
在生成子节点的过程中,如果碰到parent='B',而'B'又是某一个key的结尾。该如何办呢?
比如:比如若以"一举"中的'举'字符为parent,那么parent.depth = 2,"一举".length = 2.
遇到这种情况,我们就需要对其进行过滤操作,过程如下:
String tmp = key.get(i);
int currCode = 0;
if (tmp.length() != parent.depth) {
currCode = (int) tmp.charAt(parent.depth) + 1;
}完整过程:
private int fetch(Node parent, List<Node> siblings) {
...
int prevCode = 0;
for (int i = parent.left; i < parent.right; i++) {
if (key.get(i).length() < parent.depth) {
continue;
}
String tmp = key.get(i);
int currCode = 0;
if (tmp.length() != parent.depth) {
currCode = (int) tmp.charAt(parent.depth) + 1;
}
...
if (currCode != prevCode || siblings.size() == 0) {
Node tmp_node = new Node();
tmp_node.depth = parent.depth + 1;
tmp_node.code = currCode;
tmp_node.left = i;
if (siblings.size() != 0) {
siblings.get(siblings.size() - 1).right = i;
}
siblings.add(tmp_node);
}
prevCode = currCode;
}
if (siblings.size() != 0) {
siblings.get(siblings.size() - 1).right = parent.right;
}
return siblings.size();
}
3.向Trie树中插入子节点
在DAT的创建过程中,insert是关键部分。
在insert操作里,我们使用了递归的思路来解决问题。为什么要利用递归呢?因为在我们状态转移的过程中,父节点的base值需要依赖子返回的begin值,因为在DAT中,code[null] = 0,所以也可以认为是依赖于子节点的check值,如此反复,层层嵌套。关于这一点在下面的结构图展示中更容易体现。
(0)check的合法性检查
之前我们说check数组是为了检查各个字符串是否是从同一个状态转移而来,但是,要如何检查呢?看下面这段代码:
outer: while (true) {
position++;
if (check[position] != 0) {
continue;
} else if (first == 0) {
...
}
begin = position - siblings.get(0).code; // 当前位置离第一个兄弟节点的距离
...
for (int i = 1; i < siblings.size(); i++) {
if (check[begin + siblings.get(i).code] != 0) {
continue outer;
}
}
break;
} 这里的position即在数组中的下标。可以看到这是一个循环遍历的过程,我们在一个合适的位置开始,逐步地尝试check值是否合法,找到第一个合法的begin值即可。
而check[i]合法的条件就是check[i]是否为0。如果check[i]不为0,则说明此位置已经被别的状态占领了,需要更换到下一个位置。
(1)计算所有子节点的check值
for (int i = 0; i < siblings.size(); i++) {
check[begin + siblings.get(i).code] = begin;
}
(2)计算所有子节点的base值
private int insert(List<Node> siblings) {
...
for (int i = 0; i < siblings.size(); i++) {
List<Node> new_siblings = new ArrayList<Node>();
if (fetch(siblings.get(i), new_siblings) == 0) {
base[begin + siblings.get(i).code] = (value != null) ? (-value[siblings.get(i).left] - 1) : (-siblings.get(i).left - 1);
...
} else {
int h = insert(new_siblings);
base[begin + siblings.get(i).code] = h;
}
}
return begin;
}在这一步中,大家可以很明显地看到,这是一个递归的过程。我们需要获得子节点的begin值。

采用递归之后,我们的DAT节点的状态转移过程
(3)整体的insert过程:
private int insert(List<Node> siblings) {
...
// check的合法性检查
...
// 计算所有子节点的check值
// 计算所有子节点的base值
...
}

DAT中双数组的状态转移过程
4.前缀查询
现在假设待查找字符串T="走廊里的壁画",我们需要在之前的字典中查找所有是T前缀的字符串。我们要怎么做呢?
其实在上面的双数组状态转移过程图中,我们可以很清楚地找到一条满足条件的路径.如下:
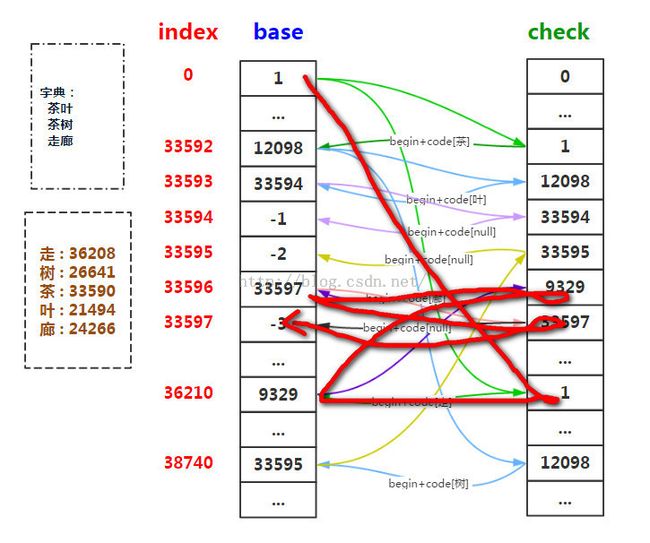
关键代码如下:
public List<Integer> commonPrefixSearch(String key, int pos, int len, int nodePos) {
...
int b = base[nodePos];
...
for (int i = pos; i < len; i++) {
p = b;
n = base[p];
if (b == check[p] && n < 0) {
result.add(-n - 1);
}
p = b + (int) (keyChars[i]) + 1;
if (b == check[p]) {
b = base[p];
} else {
return result;
}
}
p = b;
n = base[p];
if (b == check[p] && n < 0) {
result.add(-n - 1);
}
return result;
}
5.关键词智能提示:
在上面“前缀查询”的例子中,我们的匹配字符串中比较长,在还没到字符串的最后一位就遇到状态停止标志。而如果匹配字符串比较短,我就还可以做一些其他的事情了,比如常见的搜索引擎中关键词智能提示。
过程就是在上一步的基础上,把终止循环的条件修改为直到遇到一个状态停步标志.这样我们就可以在遍历整条路径。
这个功能,在源码中没有涉及。而本文的目的是在于解释DAT的原理和其状态转移的过程。所以,这里就暂不贴代码了。不过,在后期的《搜索引擎:对用户输入有误的关键词进行纠错处理》博客中应该会有所涉及。感兴趣的朋友,可以关注下。
实现源码下载:
http://download.csdn.net/detail/u013761665/9201933