图的深度(DFS)/广度优先搜索算法(BFS)/Dijkstra
类比二叉树先序遍历与图深度优先搜索
在引入图的深度优先搜索之前,为了更加容易理解.先考究一种特殊的图---二叉树的深度优先搜索算法---即二叉树的递归遍历方法.
二叉树的前序遍历算法:
void TreeWalk(node* root)
{
if(root)
{
visit(root);
TreeWalk(root->left);
TreeWalk(root->right);
}
}
对于二叉树来说,步骤如下:
1.如果root不为空,先访问root,
2再递归下降地访问root->left和root->right.
在二叉树中,与root邻接的结点只有left and right.所以,每次只需要递归下降访问这两个节点即可.
对于图来说,可以类比二叉树(特殊情况),总结出一般规律:
1先选定任意一个点vex做为生成树的根结点.访问该根点,
2再递归下降地访问与vex邻接的而且未被访问过的所有结点.
在图中,与vex邻接的结点是不像二叉树一样只有left 和 right,因为是不确定的,因此需要循环地查找判断哪些点邻接并且尚未被访问过.
伪代码:
void DFS(Graph& g,int vex)
{
Visit vex and Mark vex is visited;
for w=FirstAdjacencyVertex to LastAdjacencyVertex(which is not visited before)
DFS(g,w)
}
对应的C++代码:
//深度优先算法,可以形成一棵树
void DFS(Graph& g,int vex)
{
cout<<vex<<' ';
visited[vex]=true;//is visited
int w=FirstAdjVertex(g,vex);
while(w>0)
{
DFS(g,w);
w=NextAdjVertex(g,vex,w);
}
}其中,FirstAdjVertex(g,vex)可以返回vex的第一个未被访问的邻接结点w.NextAdjVertex(g,vex,w)可以返回vex的下一个未被访问的邻接结点,在编号上在w之后.(小编号结点优先原则).
//找第一个未被访问过的邻接结点,找不到返回0
int FirstAdjVertex(Graph& g,int vex)
{
for(int i=1;i<=g.vnum;++i)//从点1开始找与vex邻接的第一个结点
{
if(g.edge[vex][i]==1 && !visited[i])
return i;
}
return 0;
}
//找下一个未被访问过的邻接结点
int NextAdjVertex(Graph& g,int vex,int w)
{
for(int i=w;i<=g.vnum;++i)//从w开始,找下一个未被访问过的邻接结点
{
if(g.edge[vex][i]==1 && !visited[i])//若i与vex邻接且i未访问过,下一次遍历,就从这个点往下.
return i;
}
return 0;//点都从1开始,返回0则所以点已访问过
}对于无向连通图或者强有向强连通图,可以调用DFS形成一棵深度优先搜索树.但是,对于非连通图或者非强连通图.需要在生成一棵树之后,继续寻找是否还存在未被访问到的点,在这些点上继续调用DFS,最终形成森林.
void DFS_traver(Graph& g)
{
for(int i=1;i<=g.vnum;++i)
{
if(!visited[i])//如果i结点未被访问过,形成森林
DFS(g,i);
}
}
深度优先搜索完整代码:
#include<iostream>
using namespace std;
const int MAX=20;//最大点数
bool visited[MAX]={false};//点标记域:标志是否被访问过.
struct Graph
{
int vertex[MAX];//点
int edge[MAX][MAX];//边
int vnum;//点数
};
//创建图
void CreateGraph(Graph& g)
{
cin>>g.vnum;
for(int i=1;i<=g.vnum;++i)
g.vertex[i]=i;
for(int i=1;i<=g.vnum;++i)
{
for(int j=1;j<=g.vnum;++j)
cin>>g.edge[i][j];
}
}
//打印图
void PrintGraph(Graph& g)
{
for(int i=1;i<=g.vnum;++i)
cout<<g.vertex[i]<<' ';
cout<<endl;
for(int i=1;i<=g.vnum;++i)
{
for(int j=1;j<=g.vnum;++j)
cout<<g.edge[i][j]<<' ';
cout<<endl;
}
}
//找第一个未被访问过的邻接结点,找不到返回0
int FirstAdjVertex(Graph& g,int vex)
{
for(int i=1;i<=g.vnum;++i)//从点1开始找与vex邻接的第一个结点
{
if(g.edge[vex][i]==1 && !visited[i])
return i;
}
return 0;
}
//找下一个未被访问过的邻接结点
int NextAdjVertex(Graph& g,int vex,int w)
{
for(int i=w;i<=g.vnum;++i)//从w开始,找下一个未被访问过的邻接结点
{
if(g.edge[vex][i]==1 && !visited[i])//若i与vex邻接且i未访问过,下一次遍历,就从这个点往下.
return i;
}
return 0;//点都从1开始,返回0则所以点已访问过
}
//深度优先算法,可以形成一棵树
void DFS(Graph& g,int vex)
{
cout<<vex<<' ';
visited[vex]=true;//is visited
int w=FirstAdjVertex(g,vex);
while(w>0)
{
DFS(g,w);
w=NextAdjVertex(g,vex,w);
}
}
void DFS_traver(Graph& g)
{
for(int i=1;i<=g.vnum;++i)
{
if(!visited[i])//如果i结点未被访问过,形成森林
DFS(g,i);
}
}
void main()
{
Graph g;
CreateGraph(g);
PrintGraph(g);
DFS_traver(g);
}
深度优先链式表示法
#include<iostream>
using namespace std;
const int MAX=6;
struct node
{
int value;
node* next;
bool visited;
node(int v):value(v),visited(false),next(NULL){}
};
struct Graph
{
node* A[MAX];//定义一个指针数组,数组的每一个元素都是指针
Graph()
{
for(int i=0;i<MAX;++i)
{
A[i]=NULL;
}
}
};
node* insertList(node* head,node* x)
{
if(!head)//if(!head)=if(head==NULL)
{
head=x;
return head;
}
head->next=insertList(head->next,x);
return head;
}
void CreateGraph(Graph& g)
{
int inter;
for(int i=1;i<MAX;++i)
{
while(cin>>inter && inter !=0)//以0为结束
g.A[i]=insertList(g.A[i],new node(inter));//g.A[i]是表头
}
}
void printGraph(Graph& g)
{
node* p=NULL;
for(int i=1;i<MAX;++i)
{
p=g.A[i];
while(p)
{
cout<<p->value<<' ';
p=p->next;
}
cout<<endl;
}
}
node* FindAdjVertex(Graph& g,node* vex)
{
while(vex)//从点1开始找与vex邻接的第一个结点
{
if(!g.A[vex->value]->visited)//查看vex是否被访问过,访问标志保存在表头g.A[i]
return vex;
vex=vex->next;
}
return NULL;
}
/*
//找下一个未被访问过的邻接结点
node* FindAdjVertex(Graph& g,node* w)
{
while(w)//从w开始,找下一个未被访问过的邻接结点
{
if(!g.A[w->value]->visited)//若i与vex邻接且i未访问过,下一次遍历,就从这个点往下.
return w;
w=w->next;
}
return NULL;//点都从1开始,返回0则所有点已访问过
}
*/
void DFS(Graph& g,node* vex)
{
cout<<vex->value<<' ';
//vex->visited=true;//is visited
g.A[vex->value]->visited=true;//设置标志
node* w=FindAdjVertex(g,g.A[vex->value]);
while(w)
{
DFS(g,w);
w=FindAdjVertex(g,g.A[w->value]);
}
}
void DFS_traver(Graph& g)
{
for(int i=1;i<MAX;++i)
{
if(!g.A[i]->visited)//如果i结点未被访问过,形成森林
DFS(g,g.A[i]);
}
}
void main()
{
Graph g;
CreateGraph(g);
printGraph(g);
//DFS(g,g.A[1]);
DFS_traver(g);
}
非递归版DFS
/*从顶点i开始对图进行深度优先搜索遍历,图由其邻接表adjlist表示*/
void DFS2(Graph& g,node* vex)
{
node* p=vex;
stack<node*> st;
while (p || !st.empty())
{
while (p) {
if(!g.A[p->value]->visited)//如果未被访问过
{
cout<<p->value<<' ';//visit
g.A[p->value]->visited=true;//设为已访问,纵深探索
st.push(p);//同时压栈
p=g.A[p->value];//找下一个点
}
else
p = p->next;//接着找未被访问过的节点
}
if(!st.empty())
{
p=st.top();
st.pop();
p = p->next;
}
}
}
图片来自算法导论第二版:
广度优先搜索算法:来源:点击打开链接
图的广度优先遍历
图的广度优先遍历BFS算法是一个分层搜索的过程,和树的层序遍历算法类同,它也需要一个队列以保持遍历过的顶点顺序,以便按出队的顺序再去访问这些顶点的邻接顶点。
1.连通图的广度优先遍历算法思想。
(1)顶点v入队列。
(2)当队列非空时则继续执行,否则算法结束。
(3)出队列取得队头顶点v;访问顶点v并标记顶点v已被访问。
(4)查找顶点v的第一个邻接顶点col。
(5)若v的邻接顶点col未被访问过的,则col入队列。
(6)继续查找顶点v的另一个新的邻接顶点col,转到步骤(5)。直到顶点v的所有未被访问过的邻接点处理完。转到步骤(2)。
【例】下面以图( a )为例说明广度优先搜索的过程。首先从起点 v1 出发访问 v1。v1 有两个未曾访问的邻接点 v2 和 v3 。先访问 v2 ,再访问 v3 。然后再先访问 v2 的未曾访问过的邻接点 v4、v5 及 v3 的未曾访问过的邻接 v6 和 v7 ,最后访问 v4 的未曾访问过的邻接点 v8 。至此图中所有顶点均已被访问过。得到的顶点访问序列为:


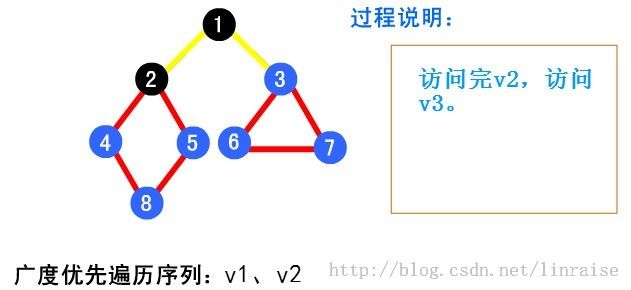

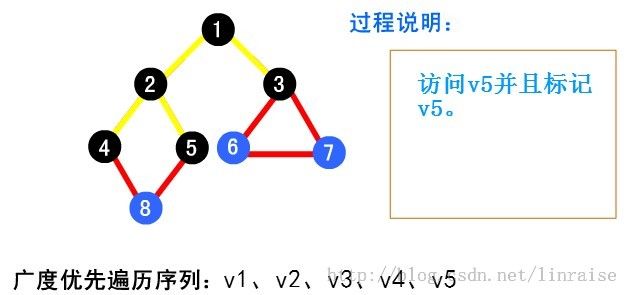


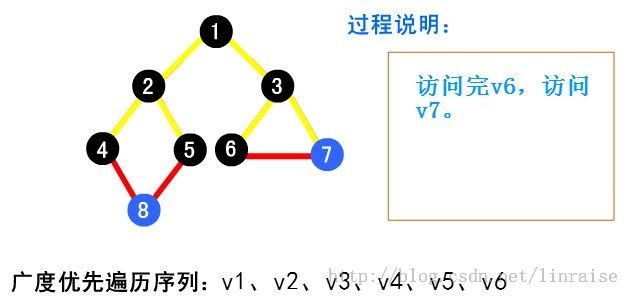
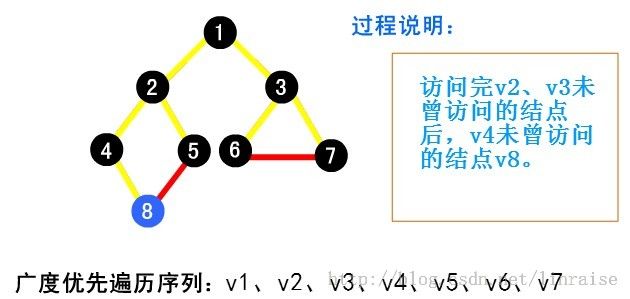
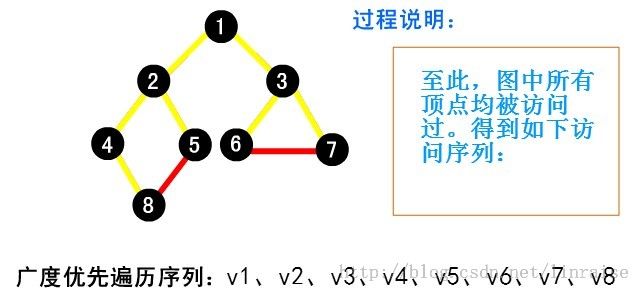
代码:特别鸣谢@tommyhu111
void BFS(Graph& g,int vex)
{
queue<int> q;
visited[vex] = true; //标记已被访问过
q.push(vex); //初始化队列
while(!q.empty())
{
vex=q.front();
q.pop(); //取出队头数据
cout<<vex<<' ';
for ( int j=1; j<=g.vnum; ++j )
{
if( g.edge[vex][j] == 1 && !visited[j] ) //邻接未被访问过的结点入队
{
visited[vex] = true; //标记已被访问过
q.push(j);
}
}
}
}
void BFS_traver(Graph& g)
{
for(int i=1;i<=g.vnum;++i)
{
if(!visited[i]) //如果i结点未被访问过,形成森林
BFS(g,i);
}
}
Dijkstra算法
广度优先搜索的经典应用:Dijkstra算法。Dijkstra算法的思想是BFS+贪心策略。即从源结点向外辐射状地扩展结点,并且每一次都选择最优的结点进行扩展。如果有n个结点,则循环n次就可以将所有结点的最短路径求出来,缺点是无法对权重为负数的图进行并且搜索的结点多效率相对较低。
先直接贴出代码,后面再解释算法运行的原理。
#include<stdio.h>
#define MAX_VERTEX_NUM 100 //最大顶点数
#define MAX_INT 10000 //无穷大
typedef int AdjType;
typedef char VType; //设顶点为字符类型
struct PathType
{
int route[MAX_VERTEX_NUM];//存放v到vi的一条最短路径
int End;
};
//邻接矩阵表示的图
struct Graph
{
VType V[MAX_VERTEX_NUM]; //顶点存储空间
AdjType A[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; //邻接矩阵
};
//Dijkstra算法
//求G(用邻接矩阵表示)中源点v到其他各顶点最短路径,n为G中顶点数
void Dijkstra(Graph * G,PathType path[],int dist[],int v,int n)
{
int i,j,count,min,minIndex;
//visited[n]用来标志源点到某顶点的最短路径是否求出
int *visited=new int[n];
for(i=0;i<n;i++)
{ //1.初始化
visited[i]=0;
dist[i]=G->A[v][i];//v到它的邻接顶点的权为当前最短路径,用这个权值初始化dist[],优先队列(每次找小)
path[i].route[0]=v; //开始结点都是v
path[i].End=0; //路径末尾索引
}
dist[v]=0;
visited[v]=1;//源点到源点本身的最短路径已经求出
count=1;
while(count<=n-1)
{ //求n-1条最短路径
min=MAX_INT;// MAX_INT为无穷大值,需要实际情况设置
//这一部分实现的是优先队列的功能,找最小值
for(j=0;j<n;j++)
{ //找当前最短路径长度
//如果j未被访问过且当前j的距离更短,更新min和minIndex
if( !visited[j] && dist[j]<min )
{
minIndex=j;
min=dist[j];
}
}
//当visited[]数组全是1,即合被访问过时,可以退出了。
if(min==MAX_INT)
break;//最短路径求完(不足n-1)条,跳出while循环,考虑非连通图
//贪心选择,选择当前最min的路径
int pEnd = ++path[minIndex].End;
path[minIndex].route[pEnd]=minIndex ;
visited[minIndex]=1;//表示V到minIndex最短路径求出,标记为已被访问过
for(j=0;j<n;j++)
{ //minIndex求出后,修改dist和path向量,只更新那些未处理过的点
if(!visited[j] && dist[minIndex]+G->A[minIndex][j] < dist[j] )
{
dist[j]=dist[minIndex]+G->A[minIndex][j];//更新最短路径长度
path[j]=path[minIndex];//更新为更短的路径
}
}
count++;
}
delete []visited;
}
int main()
{
int i,j,v=0,n=6;//v为起点,n为顶点个数
Graph G;
//v到各顶点的最短路径向量
PathType* path = new PathType[n];
//v到各顶点最短路径长度向量
int* dist =new int[n];
AdjType a[MAX_VERTEX_NUM][MAX_VERTEX_NUM]=
{
{MAX_INT,7,9,MAX_INT,MAX_INT,14},
{7,MAX_INT,10,15,MAX_INT,MAX_INT},
{9,10,MAX_INT,11,MAX_INT,2},
{MAX_INT,15,11,MAX_INT,6,MAX_INT},
{MAX_INT,MAX_INT,MAX_INT,6,MAX_INT,9},
{14,MAX_INT,2,MAX_INT,9,MAX_INT}
};
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
G.A[i][j]=a[i][j];
}
}
Dijkstra(&G,path,dist,v,n);
for(i=0;i<n;i++)
{
printf("%d到%d的最短路径:",v+1,i+1);
for(j=0;j<=path[i].End;j++)
{
printf("%d ",path[i].route[j]+1);
}
printf("\n");
printf("最短路径长度:%d",dist[i]);//输出为MAX_INT则表示两点间无路径
printf("\n");
}
delete []path;
delete []dist;
return 0;
}
用一个具体的图作为例子:
图的领接矩阵(带权短阵):
{MAX_INT,7,9,MAX_INT,MAX_INT,14},
{7,MAX_INT,10,15,MAX_INT,MAX_INT},
{9,10,MAX_INT,11,MAX_INT,2},
{MAX_INT,15,11,MAX_INT,6,MAX_INT},
{MAX_INT,MAX_INT,MAX_INT,6,MAX_INT,9},
{14,MAX_INT,2,MAX_INT,9,MAX_INT}
图如下:
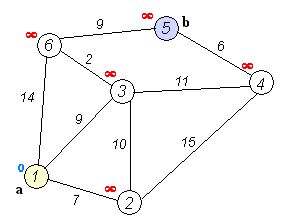
Dijkstra算法的第一步:初始化
将所有的结点visited[i]设为0,即各个结点还没有计算出最短路径。
dist[i]表示结点i的权值,也可以看作是从源点v到结点i的最短路径长度。v到它的邻接顶点的权为当前最短路径.初始化比如,dist[0]=0,dist[1]=7,dist[2]=9,dist[5]=14,dist[4]=MAX,dist[3]=MAX(结点从0数起)
path[i]的开头结点都设为源结点v,路径末尾索引都设为0,因为当前只有一个元素。
并且dist[v] =0 ,visited[v]=1,源点到源点的最短路径已经求出。
初始化后是:
第二步:贪心选择当前未被计算出最短路径的dist[i]的最小值,如上图,现在dist[]数组是{0,7,9,14,MAX,MAX},0已被访问过,则从其余结点中贪心选择最短的一个结点1,(这一部分实现的是一个优先队列的功能,可以用STL的优先队列实现)
第三步:第二步贪心选择好一个结点后,需要更新dist[]数组和path[]数组,因为基于启发式搜索,有可能新发现的路径比原来的路径更短。
(如图:在7,9,14,MAX,MAX中贪心选择最短路径7,即结点1.标记为已计算出最短路径visited[i]=1,然后更新未visited过的结点的路径.对于结点3,有7+15<MAX,则用22更新结点3的权,同时更新最短路径paht[]。对于结点2,7+10>9,新发现的路径比原来的更小,无须更新。对4,5这些和1并不邻接的结点有MAX+7 > MAX,无须更新,同时MAX不能设为INT_MAX)
第四步:重复上第二步和第三步的步骤n-1次,就可以求出源点到所有结点的最短路径。
最短路练手:HDU1874
#include<iostream>
#include<string.h>
#include<limits.h>
using namespace std;
#define MAX_INT 2139062143
int map[205][205];
int n,s,v;
int visited[205],dist[205];
void Dijkstra()
{
//第一步:初始化
int i,min,v;
memset(visited,false,sizeof(visited));
memset(dist,127,sizeof(dist));//强大的近似初始化最大值
dist[s] = 0;
while(1)
{
//第二步:找最小
min = MAX_INT,v = s;
for(i=0; i<n; ++i)
{
if(!visited[i] && dist[i] < min)
min = dist[i],v = i;
}
if(min == MAX_INT)
break;
visited[v] = true;
//第三步:更新路径长度
for(i=0; i<n; ++i)
{
if(!visited[i] && map[v][i]<MAX_INT && dist[v] + map[v][i] < dist[i])
dist[i] = dist[v] + map[v][i];
}
}
}
int main()
{
int m,i,x,y,res;
while(cin>>n>>m)
{
memset(map,127,sizeof(map));
for(i=0; i<m; ++i)
{
cin >> x >> y >> res;
if(map[x][y]>res)//注意重边,选最小的边
map[x][y] = map[y][x] = res;
}
cin >> s >> v;
Dijkstra();
if( dist[v] == MAX_INT )
cout << "-1" << endl;
else
cout << dist[v] << endl;
}
return 0;
}