解决的问题
目前已经面临或者未来可能面临的问题有以下这些:
1.数据量越来越大,超出了单表或者单库的最大限制。
2.数据访问压力越来越大,超出了数据库系统能力。访问压力可能出现读压力过大或者写压力过大。
3.数据访问层运维问题。
4.数据访问层高可用方案。
5.数据访问层访问控制和管理。
暂时不解决的问题包括:
对非关系型数据存储的统一访问。
自主开发还是扩展?
为了解决上述问题,有很多可选的方案。自主开发和使用现有开源方案扩展的讨论是经常会面临的,详细讨论过程就不再赘述,直接列出讨论的结果。
结论:基于目前开源方案进行扩展和定制实现。具体原因有以下这些:
a.我们的使用场景很简单,大多数开源解决方案都可以很好地实现,而且目前有很多可选的开源方案,直接使用开源方案可行。
b.完全自主开发的周期更长、技术风险都非常大,这都是咱们无法承担的。
c.选择一个源代码开放、需求最符合、代码能够扩展和定制的开源产品可行。基于该开源产品,通过
不断深入学习使用方法,学习实现原理和源代码实现,达到可以自由扩展和定制,以改造成完全符合
自身需求的产品。
技术方案选型
可选方案分类概述
对于ddal来说,最核心的一个需求莫过于分库分表,而对于分库分表,已经有很多的开源产品出现了,比如cobar-client、hibernate shards、guzz、halo-dal、ibatis-sharding、cobar、mysql proxy、tddl等。每一个产品都有针对于不同层面进行封装而达到屏蔽上层对底层分库分表的具体细节的依赖,都是加载数据库访问客户端和服务端之间的一些中间层。
总结一下上述列出的各种解决方案可以归纳为一下几大类。
1.DAO层。该方案即通过在实现DAO层代码时候,通过硬编码的方式加入分库分表的逻辑,该层实现一般由项目组自行根据需求实现。
2.ORM 框架层。该方案的实现是通过实现一个ORM框架,该框架自带分库分表功能,如:guzz;另外一种方式是基于开源成熟的ORM框架(比如MyBaits、HIbernate)进行扩展分库分表特性,主要的开源产品有:cobar-client、hibernate shard、shalo-dal、ibatis-sharding。
3.JDBC API层。该方案通过封装JDBC API,实现分库分表逻辑,这个方法比较直接,而且有比较强的可控制性,目前有淘宝开源的tddl,但是目前不支持分库分表,只支持读写分离、主备自动切换,故障转移等特性。
4.数据访问代理层。该方案通过位于客户端和服务端中间的代理服务器实现分库分表逻辑,主要产品有mysql proxy、Cobar和amoeba等。
5.数据库分区。该方案是数据库自行实行的分库分表特性。目前主流的关系型数据库,商业数据库Oralce、SQL server和DB2早就有非常成熟的数据库分区解决方案,而主流的开源数据库MySQL和PostGre也在5.0和8.0版本也增加了数据库表分区的特性。
如上图所示,展示的是各种方案之间的关系,还包括了各种方案所处的层次,图中带颜色的各区块表示的是各种实现方案。
上图中的关系是越处于下方的层次越低,上层的总是依赖下层,下层不依赖上层。各种层次的实现方案都有自己的优缺点,有自己适合的场景。
可选方案对比分析
各种可选方案都能够从不能程度上实现分库分表的核心需求,每种方案都有自己的优势和适合的应用场景,同时也有它的缺点和使用上的限制,通过对各种方案的详细各种因素的综合对比分析才能选择一个最适合一种或者多种方案的组合。
| DAO层 | 无开源产品,需参考 开放方案自行实现,在DAO 层代码中实现分库分表的逻辑。 |
实现简单 依赖少 自由度大 |
成本高 周期长 |
分库分表等 可自行实现任何特性 |
自身技术能力约束 | 无 | |||
| ORM框架层 | cobar-client | 简单易用,无需引入代理服务层 与ibatis框架良好集成 与数据库无关,支持各种数据库 |
对于使用的mybatis框架及版本号都 有较强的约束,而且对于使用的Spring框架也有版本约束,对于应用的侵入性较大,需要修改应用才能使用。 |
|
对于mybatis和Spring等框架的版本号有约束 | 成熟 | java | http://code.alibabatech.com/docs/cobarclient/zh/ | |
| JDBC API层 | tddl | 支持的特性较丰富。 遵守JDBC规范,对于应用过的侵入性较小,能够很方便的应用在现有的应用中。 支持的数据丰富,支持MySQL和Oracle,可以方便的扩展支持其它数据库。 |
开源版本目前不支持分库分表, 强依赖diamond配置中心项目, |
1.数据库主备和动态切换 2.带权重的读写分离 3.单线程读重试 4.集中式数据源信息管理和动态变更 5.剥离的稳定jboss数据源 6.支持mysql和oracle数据库 7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源 8.无server,client-jar形式存在,应用直连数据库 9.读写次数,并发度流控,动态变更 10.可分析的日志打印,日志流控,动态变更 |
开源版本暂不支持分库分表 |
成熟 | java | https://github.com/alibaba/tb_tddl | |
| 数据访问代理层 | corbar | 可以支持垂直和水平数据切分数据库集群的访问; 支持双机热备的HA解决方案 |
不支持跨库情况下的join、分页、排序、子查询操作。 SET语句执行会被忽略,事务和字符集设置除外。 分库情况下,insert语句必须包含拆分字段列名。 分库情况下,update语句不能更新拆分字段的值。 不支持SAVEPOINT操作。 暂时只支持MySQL数据节点。 使用JDBC时,不支持rewriteBatchedStatements=true参数设置(默认为false)。 使用JDBC时,不支持useServerPrepStmts=true参数设置(默认为false)。 使用JDBC时,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()方法设置参数。 暂时只支持MySQL数据库。 |
成熟 | java | http://code.alibabatech.com/wiki/display/cobar/Home |
最终方案
最终结论:
通过对比分析后最终的结论如下:
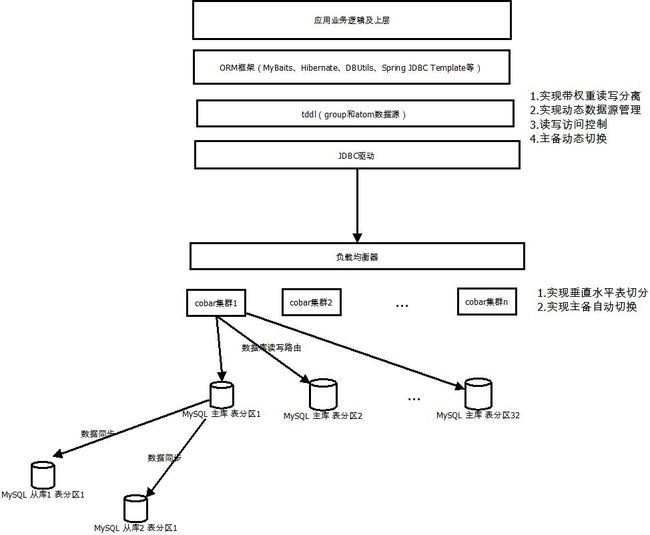
基于开源的tddl+cobar集成,再通过适当的扩展和定制最终实现符合自身需求的分布式数据访问层服务。
原因如下:
1.tddl和cobar都是遵循标准协议的实现方式。使用这些方案后应用的改动都比较小,通用性较强,基本上所有的项目都能够很方便的应用这种方案。
2.tddl实现了主备切换、读写分离、动态数据源、数据访问层运维支持、访问控制等特性,而cobar垂直和水平切分、高可用等特性。两种方案的集成使用能够解决目前数据访问层的大部分问题,功能强大。
3.都是使用Java语言编写的开源项目。能够通过不断深入学习其源代码,将其改造成完全符合自身需求的ddal。
4.都是非常成熟的产品。这两个产品都是阿里集团下的公司开源出来的产品,经过了大量的生产环境验证,质量和稳定性有保障。
Tddl(Taobao Distribute Data Layer)是整个淘宝数据库体系里面具有非常重要的一个中间件产品,在公司内部具有广泛的使用。
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。
- 产品在阿里巴巴B2B公司已经稳定运行了3年以上。
- 目前已经接管了3000+个MySQL数据库的schema,为应用提供数据服务。
- 据最近统计cobar集群目前平均每天处理近50亿次的SQL执行请求。
产品的约束如何解决?
对于任何DDAL产品都有自身的一些约束和局限性,无法完全与直接访问数据库那样自由和特性强大,对于DDAL产品无法支持的特性,那么该如何解决呢?
1.适当放弃某些特性。例如分布式事务,在某些数据上可以放弃该需求。
2.增加替代方案或者补偿机制。通过增加一些替代的解决方案来解决特性的缺失,如应用自行实现某些特性等,或者通过一些补偿机制来弥补某些特性的缺失。
实施计划
最终该方案想最终应用到项目中,需要经过一个过程,具体的实施计划如下。
1.测试cobar和tddl的功能特性和性能指标。
测试这两个开源产品的功能特性是否满足要求,质量是否可靠;
引入这些产品后必然对性能产生一定影响,通过性能测试掌握其性能损耗量是否可接受。
2.在项目中小范围应用。在某些数据量大的项目中尝试使用该方案。
3.项目试运行。观察使用本方案的项目的运行效果,对于发现的问题及时解决。
4.持续研究增加新特性。通过持续研究这两个开源产品的原理及实现代码,扩展或者调整为完全符合自身需求的ddal产品。