springside3里面的hibernate
springside3 里面的 hibernate
以 springside3 里面的 mini-web 为例子来分析。
src/main/java 目录结构
src/test/java 目录结构
如果需要更换数据库的话,就要改 2 个文件即可。
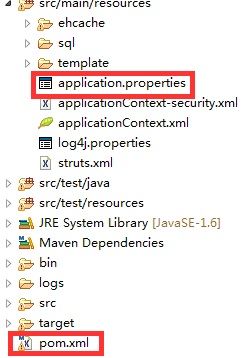
application.properties 改数据库驱动,数据库源,数据库帐号密码,是否显示 SQL 语句等。
pom.xml 是添加数据库驱动包的。
Mini-web 项目用的是 h2 数据库,所以如果不需要更换数据库的话,把 mini-web 项目导入到 myeclipse 后再添加右击项目选中
![]()
就可以马上启动了。
Authority.java 权限实体类
Role.java 角色实体类
User.java 用户实体类
他们都继承了 IdEntity 的 id 生成策略,里面有他们各自的一些属性,并且用 annotation 来创建各自的表。
以 User.java 为例
//声明当前pojo为实体Bean @Entity //表名与类名不相同时重新定义表名. @Table(name = "ACCT_USER") //默认的缓存策略. @Cache(usage = CacheConcurrencyStrategy.READ_WRITE) //字段非空且唯一, 用于提醒Entity使用者及生成DDL. @Column(nullable = false, unique = true) public String getLoginName() { return loginName; }
事实上,你既可以保持字段的持久性(注释写在成员变量之上),也可以保持属性(注释写在 getter 方法之上)的持久性。
3. 常用的hibernate annotation 标签如下:
@Entity -- 注释声明该类为持久类。将一个 Javabean 类声明为一 个实体的数据库表映射类 , 最好实现序列化 . 此时 , 默认情况下 , 所有的类属性都为映射到数据表的持久性字段 . 若在类中 , 添加另外属性 , 而非映射来数据库的 , 要用下面的 Transient 来注解 .
@Table (name= "promotion_info" ) -- 持久性映射的表 ( 表名 ="promotion_info).@Table 是类一级的注解 , 定义在 @Entity 下 , 为实体 bean 映射表 , 目录和 schema 的名字 , 默认为实体 bean 的类名 , 不带包名 .
@Id -- 注释可以表明哪种属性是该类中的独特标识符 ( 即相当于数据表的主键 ) 。
@GeneratedValue -- 定义自动增长的主键的生成策略 .
@Transient -- 将忽略这些字段和属性 , 不用持久化到数据库 . 适用于 , 在当前的持久类中 , 某些属性不是用于映射到数据表 , 而是用于其它的业务逻辑需要 , 这时 , 须将这些属性进行 transient 的注解 . 否则系统会因映射不到数据表相应字段而出错 .
@Temporal (TemporalType.TIMESTAMP)-- 声明时间格式
@Enumerated -- 声明枚举
@Version -- 声明添加对乐观锁定的支持
@OneToOne -- 可以建立实体 bean 之间的一对一的关联
@OneToMany -- 可以建立实体 bean 之间的一对多的关联
@ManyToOne -- 可以建立实体 bean 之间的多对一的关联
@ManyToMany -- 可以建立实体 bean 之间的多对多的关联
@Formula -- 一个 SQL 表达式,这种属性是只读的 , 不在数据库生成属性 ( 可以使用 sum 、 average 、 max 等 )
@OrderBy --Many 端某个字段排序 (List)
一对多注解:
1.
在一对多注解中, 会用到:
" 一" 方:
@OneToMany --> mappedBy:" 多" 方的关联属性( 被控方)
" 多" 方:
@ManyToOne --> @JoinColumn ," 多" 方定义的外键字段.
如数据表定义外键如下:
FOREIGN KEY (classid) REFERENCES classes(id)
则:
@JoinColumn(name="classid" )
2.
在双向关联中,有且仅有一端作为主体(owner )端存在:主体端负责维护联接列(即更新),对于不需要维护这种关系的从表则通过mappedNy 属性进行声明。mappedBy 的值指向另一主体的关联属性。
附加说明:
mappedBy 相当于过去的inverse="true".
inverse=false 的side (side 其实是指inverse =false 所位于的class 元素)端有责任维护关系,而inverse =true 端无须维护这些关系。
多对多注解:
在多对多注解中, 双方都采用@ManyToMany.
其中被控方, 像一对多注解中设置一样, 也要设置mappedBy.
其中主控方, 不像一对多注解那样, 采用@joinColumn, 而是采用@joinTable. 如下:
@JoinTable(name="j_student_course" ,joinColumns={@JoinColumn(name="sid")},inverseJoinColumns={@JoinColumn(name="cid")})
其中,
如上所说,mappedBy, 相当于inverse="true". 所以, 在@joinTable 中的inverseJoinColumns 中定义的字段为mappedBy 所在类的主键.
joinColumns 定义的字段, 就是当前类的主键.
cascade 与fetch 使用说明:
Cascade
CascadeType.PERSIST (级联新建)
CascadeType.REMOVE (级联删除)
CascadeType.REFRESH (级联刷新)
CascadeType.MERGE (级联更新)中选择一个或多个。
CascadeType.ALL
fetch 属性:
关联关系获取方式, 即是否采用延时加载。
LAZY (默认值)采用延时加载,查询数据时,不一起查询关联对象的数据。而是当访问关联对象时才触发相应的查询操作,获取关联对象数据。
EAGER :是在查询数据时,也直接一起获取关联对象的数据。
每个实体类的 DAO 都继承了 HibernateDAO ,而 HibernateDAO 也继承了 SimpleHibernateDAO ,在 SimpleHibernateDAO 里面 springside 给我们提供了很多简单的增删查改的方法
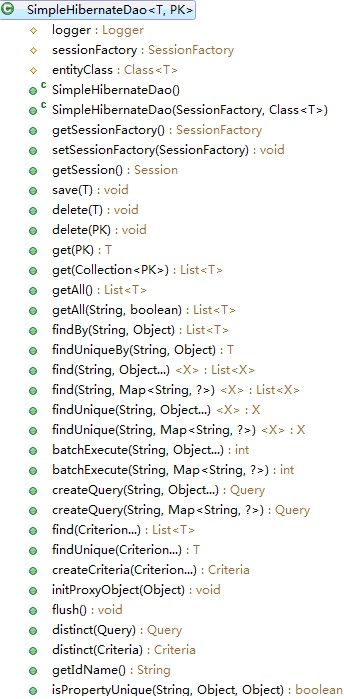
T 为实体类, PK 为实体类的主键,参数里若有 final String hql 则说明用 hql 语句做为参数。
例如
查询唯一用户:
// 获取用户
user = entityDao.findUniqueBy("id", user.getId());
HQL 多条件查询:
// 获取用户列表
List<User> u = entityDao.find("from User user where user.id=? and user.name=? ", user1.getId(), user1.getName());