HDFS Append/Hflush/Read design
原文位置https://issues.apache.org/jira/secure/attachment/12445209/appendDesign3.pdf
1. Design challenges
对于hflush,HDFS需要使得未关闭文件的最后一个block对所有readers可见。
当前存在两个挑战:
1. 读一致性问题。在一个给定时间最后一个block的不同replicas可能包含不同的字节数。在这种情况下HDFS如何提供一致性,更坏的情况下如宕机,如何保证一致性。
2. 数据耐久性。当错误发生时,recovery不能简单的抛弃最后一个block。想法Recovery应该至少保持已hflushed的字节,来达到读一致性。
2. Replica/Block States
本文档把文件block在DataNode表示为replica,以区别在NameNode上的block表示
2.1 Need for new states
Pre-append/hflush DataNode上的一个replica,这个replica或者是完成的或者是临时的。当一个replica第一次刚被创建,它是处在临时状态。当client没有数据再写入到这个replica时,会发送一个关闭请求,这时临时replica变成了完成replica。在DataNode重启时,临时的replicas会被删除。这对于pre-append/hflush是可接受的,因为HDFS对于正在构造的数据,提供了很好的数据耐久性。但是支持append/hflush后,这是不可接受的。HDFS需要对正在构造的block,提供更强的数据耐久性。 所以在DataNode启动时一些临时的replica需要被保留。
2.2 Replica states(DataNode)
在DataNode,这个设计引入了replica being written(rbw)状态,以及其他的状态来处理错误。在DataNode's内存中,replica可以是下列状态之一:
Finalized: 一个finalized replica已经完成了所有bytes。不会再有新的字节写入这个replica,除非重新打开进行append操作。它的数据和元数据完全匹配。包含相同block id的replicas和这个replica内容完全一致。但是这个finalized replica的generation stamp(GS)可能不会保持不变,error recovery可能会使它大幅改变
Rbw(Replica Being Written to):一旦replica被创建或者appended,那么它就进入rbw状态,这个replica正在被写入数据。处在rbw状态的必然是未关闭文件的最后一个block的replica。它的数据还没写完,磁盘上的data和metadata可能不匹配,同一个block ID下的其他replicas 包含的数据可能少于或者多余它的。在这个rbw中的字节(可能不是所有的)对所有readers可见。如果发生任何失败,应该尽量保留rbw中的数据。
Rwr(Replica Waiting to be Recovered):如果一个DataNode宕机或者重启,那么它的所有rbw replicas都变成了rwr状态,Rwr replicas不属于任何pileline,因此不再接受写入新数据。Rwr replica或者变得过时,或者如果client也出现了宕机那么这个replica会参与一个recovery。
Rur(relica Under Recovery):当合约到期导致replica recovery开始时,replica进入rur状态。更多细节参考合约recovery一节。
Temporary:temporary replica是正在构造的replica,和rbw replica类似,但是处在这个状态replica的数据对readers是不可见的。如果replica构造失败或者DataNode重新启动,这个临时replica将被删除。
在DataNode的磁盘上,每个数据目录都有三个子目录:current保存已完成(Finalized) replicas,tmp目录保存temporary replicas,rbw保存rbw,rwr和rur replicas。当一个replica为来自DFS client的请求所创建时,它被放在rbw目录;当因为replication或者cluster balancing的请求创建时,它被放到tmp目录。一旦这个replica完成,它就被移到current 目录。当一个DataNode重新启动,临时目录下的replica都会被删除;rbw目录下的replicas都会装载为rwr;current目录下的replicas按照已完成的replicas加载。
在DataNode升级过程中,current和rbw目录下的所有replicas需要被保存到snapshot中。
2.3 Block states(NameNode)
NameNode也为block引入了一些新的状态。block包含如下状态:
UnderConstruction:
一旦block被创建或者appended,那么就进入UnderConstruction状态,这个block正在被写入数据。它必然是未关闭文件的最后一个block。它的长度和GS都还未确定。在block中的数据(不是全部)对所有readers可见。UnderConstruction下的块会保存它的write pipeline的轨迹(比如,有效rbw replicas的位置),以及client宕机情况下rwr replicas的位置。
UnderRecovery:
当一个文件的租约到期,如果最后一个block处于UnderConstruction,那么当block recovery开始后,这个block变为UnderRecovery状态。
Committed:
一个提交的block已经完成了所有写入以及Generation stamp(GS),但是还没有从DataNodes收到至少一个GS/Length匹配。不再有新的数据需要写入这个block,GS也不会增加(除非重新打开进行append操作)。为了能够满足read请求,一个commited的数据块还需要保留rbw replicas的位置。同时还需要跟踪GS和已经完成的replicas的长度。如果client请求增加一个新的block或者关闭文件,要提交未关闭文件的under construction block。当最后一个block还在committed状态时,文件不可以被关闭。AddBlock和close操作需要等待最后一个块的GS和length完成
Complete:
一个complete block是GS和Length已经完成,并且NameNode收到了GS/len匹配。一个完成的block仅仅包含replicas的位置,仅仅当文件的所有blocks都变成complete,文件才可以被关闭。
和replica's状态不同,block's状态并不会保存到磁盘中。因此当NameNode重新启动时,未关闭文件的最后一个block被认为是UnderConstruction,其它的块则认为是complete状态。
本文的后面部分,会详细讨论replica/block状态的更多细节,replica/block 状态转换图在最后一节。
3. Write/hflush
3.1 Block Construciton Pipeline
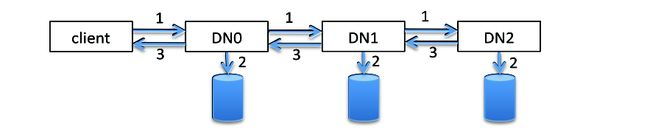
一个HDFS file包含多个blocks。每一个block通过write pipeline来构造。数据以packet为单位压入pipeline,如果没有错误发生,一个block构造分为三个过程。上图演示了三个DataNodes(DN)和包含五个packets的block。图中,粗线表示数据流,虚线代表ack信息,实线代表控制信息(setup/close)。
从T0~T1是pileline的设置阶段;T1~T2是数据传输阶段,T1是第一个数据包的传输时间,T2是最后一个数据包响应接收时间;T2~T3是close阶段
Stage1 Setup a pipeline
Client发送一个write_block请求,沿着pipeline向下传输。最后一个DataNode接收到这个请求后,响应沿着DataNode上行到Client。Setup的结果是,pipeline所需的网络链接都已经建立好,每一个DataNode都为写操作创建或者打开一个replica。
Stage2 Data streaming
User数据首先缓存在client端。当一个packet被填充完后,数据被push进pipeline。可以在收到前一packet ack信息之前,把下一个packet push到pipeline中。Client支持的outstanding packets数目受限于outstanding packets窗口大小。如果user application显示的调用了hflush,那么packet可以不等填充完就push到pipeline中。hdflush是同步操作,在受到flushed packet响应之前,不会再写入任何数据。
Stage3 Close(Finalize a block and shutdown pipeline)
当收到所有packet的ack消息,Client发送一个close请求。这可以确保在data streaming失败时,recovery不需要考虑下面的case:有些replicas已经完成了操作,而有些replicas却没有数据。
3.2 Packet handling at a DataNode
对于每一个packet,pipeline中的DataNode需要做3件事
1. stream data:a. 从前面的DataNode或者client接收数据;b. 如果还有下行DataNode,那么要把数据推送给下行DataNode
2. 写data/crc到本地磁盘文件中
3. Stream ack:a. 从下行DataNode接收响应;b. 如果从下行节点接收到响应或者这个DataNode是pipeline的最后一个DataNode,则发送响应给上行DataNode或者client
注意上面的数字顺序并没有隐含三件事情必须的执行顺序。Streaming ack(3)必须在Streaming data(1)执行完才执行。但是写数据到磁盘(2),理论上则可以在1.a后的任意时间执行。本算法是选择在1.b之后,接收下一个packet之前写磁盘。
每个DataNode为每个pipeline启动了两个线程。数据线程负责data streaming和磁盘写。对于每一个packet,DataNode顺序执行1.a 1.b 和2。一旦一个packet被刷新到磁盘,就可以从内存buffer删除这个packet。ack线程负责ack streaming。对于每一个packet,顺序执行3.a, 3.b。因为数据线程和ack线程是并行运行的,因此无法保证2和3的前后次序。ack packet可能在packet刷新到disk之前就已经发送了。
这个算法在写性能,数据持久性以及简化算法这几方面做了权衡取舍。
1. 改善了数据持久性,收到ack之前就开始写数据到磁盘中;
2. 数据向下传输/ack向上传输和写入磁盘的操作是并行执行的。
3. 简化了buffer管理,因为每个pipeline在内存中最多只有一个packet
3.3 Consistency support
当client从rbw replica读取数据时,DataNode可能不会收到的所有字节展现给client
每一个rbw replica维护着两个指针:
1. BA: 已经被下游DataNodes确认的字节数,DataNode会让这些字节对所有reader可见。在这篇文档的其余部分,我们可能也把它称作raplica的可视长度。
2. BR: 这个DataNodes已经收到的字节数目,包括已经写入磁盘文件和DataNode buffer内的字节
假定最初pipeline内的所有DataNodes的(BA,BR)=(a,a)。那么当client pushes一个packet到pipeline并且不再有packets被push进piipeline,假定packet的大小为b.
1. 在step 1.a后,DataNode的(BA,BR)变成(a, a+b)
2. 在step 3.a后,DataNode的(BA,BR)变成(a+b, a+b)
3. 当ack被成功的发送给client后,pipeline上所有DataNode的(BA, BR)都变成了(a+b, a+b)
在一个有M个DataNode的pipeline: DN0, DN1,... DNM,DN0是 pipeline的第一个节点,也是最靠近client的节点,在任意时间,满足如下:
BA0 <= BA1 <= BAM <= BRM <= BRM <= BR1 <= BR0
4. Read
当从一个未关闭的文件读数据时,最后的block可能正在构造当中,如何处理读这个block 的一致性是一个挑战。算法需要确保从每个DataNode 读到的replicas是一致的。
算法1:
- 当读取一个正在构造的block时,首先通过向DataNode发送请求,获取这个block的一个replica 的BA,
- 如果一个应用试图读取BA之外的字节,那么dfs client抛出一个EOFException异常。
- 仅当读请求读取位置小于last block的可视长度,这个请求才会发送给DataNode。当一个DataNode收到read request,并且读取字节范围小于这个replica的BR,那么DataNode返回需要的字节
- 假定读请求是一个三元组(blk, off, len),blk包含着block id和它的GS,off是在block中的偏移量,len是要读的字节数目。
- 当DataNode的replica的GS等于或者新于请求的GS,DataNode可以服务这个请求
- off和len之和必须小于这个DataNode的BA
- 假定读请求发送给DataNode i,并且它的replica的状态为(BAi, BRi)
- 如果off+len<=BAi,那么DNi可以安全的发送off开始长度为len的字节给dfs client
- 如果off+len>BAi,那么因为off+len<BAj,BAj>=BAI。在pipeline中DNi一定在DNj的上游,也就是说更靠近writer clent。所以有如下BRi >= BRj >= BAj,因此BRi>=off+len,这就是说DNi一定有dfs client想要读取的数据。此时DNi发送数据给client
- off+len永远不能大于BRi。
- 如果DNi在服务的过程中宕机,那么dfs client切换到另外一个包含replica的DataNode
- 这个算法很简单,但是需要重新open文件以便获取新数据,因为最后一块的长度是在读之前获取的,dfs client无法读取这个长度之外的数据
算法2
- 这个算法让dfs client执行一致性控制
- 读请求是一个三元组(blk, off, len),blk包含block id和GS,off是要读的block的偏移地址,len是要读取的字节长度
- 当DataNode的replica的GS新于请求的GS,DataNode可以服务这个请求。
- 假定block有状态(BAi, BRi),那么DNi发送BAi以及[off, MIN(off+len, BRi)]之间的字节给client
- client把数据接收到buffer中。同时查找最大的BA,然后只把BA范围内的数据发送给应用。
- 如果从DNi读取失败,那么dfs client切换到其他的DataNode读取数据
- 这种算法的一致性是如何保证的呢?
- 这个因为最大的BA也是小于最小BR的
- 这个算法需要改变读协议,并且dfs client更加复杂因为dfs需要控制读一致性。但是这个算法不需要重新打开文件来读取新数据
5. Append
5.1. Append API support
1. Client发送一个append请求给NameNode
2. NameNode检查文件确保这个文件已经closed。然后NameNode检查文件的最后block。如果block不满并且没有replica ,那么append失败。否则,这个文件变为under construction。如果最后一块满了,NameNode分配一个新的last block。如果最后一块不满,NameNode把这个block状态改为under construction block,使用已经完成的replicas构造pipeline。NameNode返回block id,GS,length,和它的位置,如果last block不满,也需要返回新的GS
3. 设置pipeline,在Pipeline 设置节查看详情。
4. 如果最后block结束位置不再checksum chunk边界,那么读要按crc chunk对齐,这是为了计算checksums
5. 其他方面和普通写是相同的
5.2 Duration support
- NameNode要确保包含pre-append数据的replicas数目满足文件复制因子
- 正在构造block所包含pre_append数据的持久性在当前设计中没有考虑
6. Error Handling
6.1. Pipeline Recovery
当一个block正在构建中,错误可能发生在以下任一个阶段: Stage1 pipeline正在设置, Stage2 数据正在pipeline中流动,Stage3 pipeline被关闭了。pipeline recovery处理pipeline DataNodes发生这些错误
6.1.1 Recover from pipeline setup failure
如果DataNode在pipeline设置阶段检测到失败,DataNode发送一个失败通知给它上游节点或者client,然后关闭block文件以及所有的TCP/IP连接。一旦client检测到失败,那么根据设置pipeline的目的采取不同的处理方式:
- 如果pipeline是为了创建一个新block构造的,那么client简单的抛弃这个block,然后向NameNode请求一个新block。然后开始为这个新block构造pipeline
- 如果pipeline是为了附加一个block,它用其他的DataNode重新构造一个pipeline,并且增加这个block的GS。更多细节参看section 7
pipeline设置失败的一个特殊例子是access token粗无:一个DataNode在用access token设置pipeline时抱怨access token不正确。如果是由于access token过期引起的pipeline设置失败,那么dfs client应该使用前一个pipeline的所有DataNode重建这个pipeline。当前的版本(0.21)通过获取新的access token来避免这个失败case。本文介绍的就是这种设计。
6.1.2 Recover from data streaming failure
- 在DataNode错误可以发生在1.a, 1.b, 2, 3.a, 3.b的任意阶段,不论什么时候发生,DataNode都会把自己排除在write pipeline之外:关闭所有的TCP/IP连接;如果错误发生在3,把所有buffered数据写入磁盘,并且关闭磁盘文件。
- 当dfs client检测到一个失败,停止发送数据到pipeline
- dfs client用剩余的DataNodes重新构造一个write pipeline。详情参见Section7。重新构建后,这个block所有的replicas都获得一个新的GS
- dfs client使用新的GS重新发送从BAc开始的数据。注意还可以进一步优化这个过程,只发送从 MIN(BRi)开始的字节
- 当一个DataNode接收到一个packet,如果已经有这个packet,那么DataNode仅简单的把这个packet向下推送,但是并不会写磁盘(磁盘中已经有这个packet)
这个recovery算法还有一个优点: 任何对client可见的bytes,甚至是来自于老pipeline的最末端DataNode,在pipeline recovery后仍然对reader可见。这是因为pipeline recovery过程不会减少DataNode的 BA和BR。
6.1.3. Recover from a close failure
一旦client检测到这种失败,client使用剩下的DataNodes重新构造pipeline,每一个DataNode bump block的GS然后完成replica。在收到ack后销毁网络连接。
6.2. DataNode Restart
- 当一个DataNode重新启动,他读取rbw目录下的每一个replica到内存中,然后等待recovery。长度设置为可匹配CRC的最大长度
- 任何等待recovery的replica不参与reader请求,也不参与pipeline recovery
- 等待recovery的replica,由于client仍然存活而变过期被NameNode删除,或者由于租约recovery变为完成。
6.3 NameNode Restart
- block 状态不会磁盘化,所以当NameNode重新启动时,需要恢复每一个block的状态。未关闭文件的最后一个block不论之前处在什么声明周期,都变为UnderConstruction。其他的blocks则变为complete。
- 请求每一个DataNode发现注册报告,报告包括:finalized, rbw, rwr, 和rur replicas
- NameNode不会退出safemode,直到已完成和正在构建的blocks数目达到了预定的阀值,注意这里每个block只要收到一个replica即算
6.4. Lease Recovery
当一个文件的租约到期,NameNode需要为client关闭文件。有两个问题:1)并发控制:what if a lease recovery is performed while the client is still alive either in the process of setting up pipeline, writing, close, or recovery. what if there are multiple concurrent lease recoveries? 2) 一致性保证:如果最后一个block在构造状态,那么所有的replicas需要回滚到一致状态:所有的replicas在磁盘上有相同的长度以及同样的新GS
- NameNode刷新租约,改变文件的租约持有者为dfs并且把变化写入editlog。所以如果client仍然活着,那么任何写相关的请求:比如请求新的GS,或者close文件,都会被拒绝,因为client不再是租约持有者。这可以防止client并发的改变他层加联系的NameNode上的未关闭文件。
- NameNode检查文件的最后两个block的状态,其他的blocks应该都是完成状态。下表给出了可能的状态组合,以及对每个组合的动作。
| 倒数第二块 | 最后一块 | 动作 |
| complete | complete | Close the file |
| Complete | Committed | 尝试下次租约到期前关闭文件;在尝试一定次数后,关闭文件 |
| Committed | Complete | 尝试下次租约到期前关闭文件;在尝试一定次数后,关闭文件 |
| committed | Committed | 尝试下次租约到期前关闭文件;在尝试一定次数后,关闭文件 |
| Complete | UnderConstruction | 启动最后block的recovery |
| Committed | UnderConstruction | 启动最后block的recovery |
| Complete | UnderRecovery | 为last block启动一个block recovery,尝试一定次数后,停止recovery |
| Committed | UnderRecovery | 为last block启动一个block recovery,尝试一定次数后,停止recovery |
6.5. Block Recovery
- NameNode选择一个primary DataNode(PD)作为执行block recovery的代理。PD是包含这个block replica的DataNode,如果这样的DataNode不存在,那么取消block recovery
- NameNode获取一个新的GS,用来在Recovery成功完成后标识block的generation。然后DataNode把last block的状态从UnderConstruction变为underRecovery。