Hibernate征途(五)之继承映射和组件映射
继承映射
如上面所说,以下面类图为例:
它的映射方式有三种,它们的类和属性相同,只是映射文件不同,当然也导致映射的数据结构也不同,先一下以上三个类,再根据映射文件的不同说明每种映射方式。
Animal
public class Animal {
private int id;
private String name;
private boolean sex;
//省略getter和setter……
}
Bird
public class Bird extends Animal {
private int height;
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
}
Pig
public class Pig extends Animal {
private int weight;
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
冗余
先来看一下表结构。

很明显,这种方式是将Pig和Bird冗余到一张表,以类型字段区分开来,来看一下它的映射文件:
<hibernate-mapping > <class name="com.tgb.hibernate.Animal" table="t_animal" > <id name="id"> <generator class="native" /> </id> <discriminator column="type" type="string" /> <property name="name" /> <property name="sex" /> <subclass name="com.tgb.hibernate.Pig" discriminator-value="P" > <property name="weight" /> </subclass> <subclass name="com.tgb.hibernate.Bird" discriminator-value="B"> <property name="height" /> </subclass> </class> </hibernate-mapping>
不出所料,这种方式是将两个类以子类的方式嵌入到Animal中,形成一个大“类”,从而映射出一张表,从而将将父、子类的实例全部保存在同一张表内。需要注意的是,Discriminator必须要在subclass之前声明,这个容易理解:先制定规则,再分子类。
联合
同样,先来看一下库表结构。
再来看一下映射文件:
<hibernate-mapping package="com.tgb.hibernate"> <class name="com.tgb.hibernate.Animal" table="t_animal" abstract ="true" > <id name="id"> <generator class="assigned" /> </id> <property name="name" /> <property name="sex" /> <union-subclass name="Pig" table="t_pig"> <property name="weight"/> </union-subclass> <union-subclass name="Bird" table="t_bird"> <property name="height"/> </union-subclass> </class> </hibernate-mapping>
如配置文件所示,这种方式是子类联合:子类实例的数据仅保存在子类表中,没有在父类表中有记录。当class标签中没有abstract="true"这个属性时,它也是三张表,当添加此属性后,会生成上述的表结构。
需要注意的是,主键生成策略不能是identity,也不能是native,因为native会根据数据库选择identity或sequence方式,这是因为两个子类表中的主键不能相同,而identity则会导致这个结果。
连接
同样,来看一下表结构。
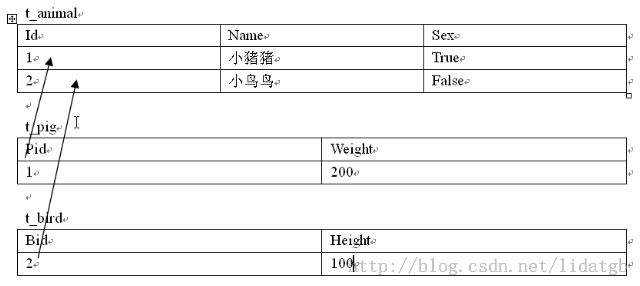
再来看一下映射文件:
<hibernate-mapping package="com.tgb.hibernate"> <class name="com.tgb.hibernate.Animal" table="t_animal" > <id name="id"> <generator class="native" /> </id> <property name="name" /> <property name="sex" /> <joined-subclass name="Pig" table="t_pig"> <key column="pid" /> <property name="weight"/> </joined-subclass> <joined-subclass name="Bird" table="t_bird"> <key column="bid"/> <property name="height"/> </joined-subclass> </class> </hibernate-mapping>可以看到,这种方式是连接的形式,与上一种方式不同的是将子类的属性和父类的属性分开存储,和上面一种方式类似的是,因为都有父类表的外键,子表中的主键也不能重复。
这种存储方式容易出现的问题是,如果继承树的深度很深,那么查询一个子类实例时,因为子类的数据依次保存在其多个父类中,需要跨越多个表,大大影响效率。
这三种存储方式各有优劣,要根据实际情况具体分析使用。
组件映射
以以下类图为例:

Contact类在此的作用就是组件类,需要时引用即可。来看一下简写的类:
Contact
public class Contact {
private String email;
private String address;
private String zipcode;
private String contactTel;
//省略getter和setter……
} Employee
public class Employee {
private int id;
private String name;
private Contact employeeContact;
//省略getter和setter
} User
public class User {
private int id;
private String name;
private Contact userContact;
//省略getter和setter……
}
再来看一下组件映射的表结构:
但从表结构上来看,和上面的“联合子类”的继承映射类似。再来看一下User的映射文件(Employee类似):
<hibernate-mapping> <class name="com.tgb.hibernate.User" table="t_User"> <id name="id"> <generator class="native"/> </id> <property name="name"/> <component name="userContact"> <property name="email"/> <property name="address"/> <property name="zipcode"/> <property name="contactTel"/> </component> </class> </hibernate-mapping>
可以看到Contact此处仅仅是作为组件使用,它仅仅是一个值,而非实体,所以不用Contact的映射文件。它与继承类似,都是为了复用;相比继承映射而言,不同点在于它将功能抽象出来,它的粒度更细,提供了更广的复用范围,与接口类似。
总结
到此为止大致给大家介绍了一下继承映射和组件映射,希望通过对比的方式,将二者的区别和类似展现出来,下篇博客会介绍一下数量和方向型的映射《 Hibernate征途(六)之数量和关系映射》。