linux内核系统调用和标准C库函数的关系分析
今天研究了一下系统调用和标准库函数的区别和联系,从网上搜集的资料如下:
资料引用分割线(红字为自己批注的重点和总结)
《=================================================================================================================================》
1.系统调用是为了方便应用使用操作系统的接口,而库函数是为了方便人们编写应用程序而引出的,比如你自己编写一个函数其实也可以说就是一个库函数。
2.系统调用可以理解为内核提供给我们在用户态用的接口函数,可以认为是某种内核的库函数。
3.read就是系统调用,而fread就是C标准库函数.
4.很多c函数库中的函数名与系统调用的名称一样是因为该函数本身其实就是调用的系统调用,放到c函数库就是为了用户态的使用
5.写程序直接使用的是库函数,而库函数内部可能就是调用的同名系统调用
6.首先,现在的OS内核主要采用两种模式,整体的单内核模式(linux)和分层的微内核模式(Windows)。单内核
模式的特点就是代码紧凑,执行速度快,各个模块之间是直接的调用关系,可以说最后一点既是优点,也是缺
点...有点就是执行速度快,缺点是内核看起来很乱,维护起来困难。
无论是单内核,还是微内核,立体的体系结构从下到上大概都是分成这样几层:物理硬件,OS内核,OS服务,
应用程序。这四层结构中,OS内核起到一个“承上启下”的作用,向下管理物理硬件;向上为OS服务和应用程序
提供接口。主意,这里的接口实际上是指系统调用(System Call)。
通常OS内核为了考虑实现起来的难度和易于管理,只提供少部分必要的系统调用,这些系统调用通常都是C和
汇编混编来实现的。接口用C定义,实现体用汇编来写。这样做的好处是,执行效率高,并且极大的方便了上层的
调用。
再说库函数(即API)。库函数可以概括的分为两类,一类是随OS提供的,另一类是第三方的。随系统提供的库
函数进一步封装或组合系统调用,实现更多的功能,就像用C语言的许多功能单一的小函数来实现很多很多个功能
复杂的大函数一样。这样的API能够执行一些相对内核来说很复杂的操作,比如,read()函数根据参数,直接就
能读文件,而背后隐藏的比如文件在硬盘的哪个磁道,哪个扇区,加载到内存的哪个位置等等这些操作,程序员
是不必关心的,这些操作里面自然也包含了系统调用。而对于第三方的库,它其实和系统库一样,只是它直接利
用系统调用的可能性要小一些,而是利用系统提供的API接口来实现功能。(API的接口是开放的)
7.高级语言库函数的确是调用系统调用来实现的,所以说系统调用才是真正对硬件操作的。
但是大家可能注意到了为什么库函数为什么是通用的(同名),这是正是高级语言不依赖与特定的硬件。
其实,都是编译器来负责库函数到系统调用之间的转换的。比如说VC可能通过把fopen()对应到windows的打印系统调用XXX(不知道具体是哪个)上去了,而linux的编译器gcc通过把fopen()对应到linux的系统调用open上去了。
8.系统调用没有库函数的效率高是因为与设置的缓冲池大小有关吧,缓冲池(不知是用户的还是内核的)小的话,系统调用的操作就频繁,缓冲池(不知是用户的还是内核)大的的话,库函数就调用系统调用的次数就少。
9.应用程序可以直接调用库函数来操作。那么linux的源代码C里是不应该使用库函数的吧,你想。编译连接成内核镜像后,安装在裸机上,连个运行环境都没怎么系统调用啊。有的人会说,系统调用在编译连接的时候已经把系统调用弄进去了,那么不是说现在流行的动态连接吗,直到运行需要时才去连接吗。
论坛的人基本就是以上的观点.
有些混乱,这里参考了下<>的第五章,关于系统调用的一些内容,如下:
第5章 系统调用
大部分介绍Linux内核的书籍都没有仔细说明系统调用,这应该算是一个失误。内核发展到现在,我们实际需要的系统调用现在已经十分完美,从这个意义上来说,再耗费宝贵的时间去研究系统调用的实现是毫无意义的事情。
然而,对于希望能够对内核有更深理解的我们来说,仔细研究少量系统调用仍是十分值得的。这样就有机会初步了解一些概念,并可以趁机详细了解一下内核编程的特点,就像系统调用本身在应用程序和内核间的桥梁作用一样,学习并理解它也是我们走向内核的一个很好的过渡。
5.1 系统调用概述
一个稳定运行的Linux操作系统需要内核和用户应用程序之间的完美配合,内核提供各种各样的服务,然后用户应用程序通过某种途径使用这些服务,进而契合用户的不同需求。
用户应用程序访问并使用内核所提供的各种服务的途径即是系统调用。在内核和用户应用程序相交界的地方,内核提供了一组系统调用接口,通过这组接口,应用程序可以访问系统硬件和各种操作系统资源。比如用户可以通过文件系统相关的系统调用,请求系统打开文件、关闭文件或读写文件;可以通过时钟相关的系统调用,获得系统时间或设置定时器等。
内核提供的这组系统调用通常也被称之为系统调用接口层。系统调用接口层作为内核和用户应用程序之间的中间层,扮演了一个桥梁,或者说中间人的角色。系统调用把应用程序的请求传达给内核,待内核处理完请求后再将处理结果返回给应用程序。
5.1.1 系统调用、POSIX、C库、系统命令和内核函数
(1)系统调用和POSIX。
系统调用虽然是内核和用户应用程序之间的沟通桥梁,是用户应用程序访问内核的入口点,但通常情况下,应用程序是通过操作系统提供的应用编程接口(API)而不是直接通过系统调用来编程。
操作系统API的主要作用是把操作系统的功能完全展示出来,提供给应用程序,基于该操作系统,与文件、内存、时钟、网络、图形、各种外设等互操作的能力。此外,操作系统API通常还提供许多工具类的功能,比如操纵字符串、各种数据类型、时间日期等。
在UNIX世界里,最通用的操作系统API基于POSIX(Portable Operating System Interface of UNIX,可移植操作系统接口)标准。POSIX的诞生和UNIX的发展密不可分,UNIX于20世纪70年代诞生于Bell lab,并于20世纪80年代向美各大高校分发V7版的源码以做研究。UC Berkeley在V7的基础上开发了BSD UNIX。
后来很多商业厂家意识到UNIX的价值也纷纷以Bell Lab的System V或BSD为基础来开发自己的UNIX,较著名的有Sun OS、AIX、VMS等。虽然这带来了UNIX的繁荣,但由于各厂家对UNIX的开发各自为政,UNIX的版本相当混乱,给软件的可移植性带来很大困难,对UNIX的发展极为不利。
为结束这种局面,IEEE制订了POSIX标准,目标是提供一套大体上基于UNIX的可移植操作系统标准,提高UNIX环境下应用程序的可移植性。然而,POSIX并不局限于UNIX。许多其他的操作系统,例如DEC OpenVMS和Microsoft Windows NT,都支持POSIX标准
POSIX标准定义了"POSIX兼容"的操作系统所必须提供的服务。Linux兼容于POSIX标准,提供了根据POSIX而定义的API函数。这些API函数和系统调用之间有着直接的关系,一个API函数可以由一个系统调用实现,也可以通过调用多个系统调用来实现,还可以完全不使用任何系统调用。
(2)系统调用和C库。
操作系统API通常都以C库的方式提供,Linux也是如此。C库提供了POSIX的绝大部分API,同时,内核提供的每个系统调用在C库中都具有相应的封装函数。系统调用与其C库封装函数的名称常常相同,比如,read系统调用在C库中的封装函数即为read函数。
C库中的系统调用封装函数在最终调用到相应系统调用之前,往往不做多少额外的工作。不过,某些情况下会有些例外,比如对于两个相关的系统调用truncate和truncate64,C库中的封装函数truncate函数即需要决定它们中的哪个应该最终被调用。
当然,如图5.1所示,系统调用和C库函数之间并不是一一对应的关系。可能几个不同的函数会调用到同一个系统调用,比如malloc函数和free函数都是通过brk系统调用来扩大或缩小进程的堆栈,execl、execlp、execle、execv、execvp和execve函数都是通过execve系统调用来执行一个可执行文件。
也有可能一个函数调用多个系统调用。更有些函数并不依赖于任何系统调用,比如strcpy函数(复制字符串)和atoi函数(转换ASCII为整数),因为它们并不需要向内核请求任何服务。
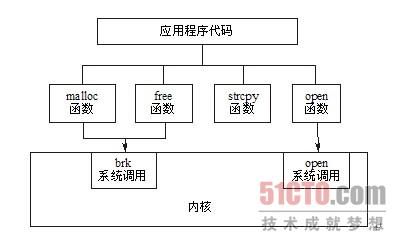
图5.1 C库函数与系统调用
实际上,从用户的角度看,系统调用和C库之间的区别并不重要,他们只需通过C库函数完成所需功能。相反,从内核的角度看,需要考虑的则是提供哪些针对确定目的的系统调用,并不需要关注它们如何被使用。
(3)系统调用与系统命令。
系统命令位于C库的更上层,是利用C库实现的可执行程序,比如最为常用的ls、cd等命令。
strace工具可以跟踪命令的执行,使用希望跟踪的命令为参数,并显示出该命令执行过程中所使用到的所有系统调用。比如,如果希望了解在执行pwd命令时都调用了哪些系统调用,可以使用下面的命令:
- $strace pwd
结果会产生大量的信息,显示出pwd命令执行过程中所调用到的各个系统调用:
- ……
- write(1, "/usr/src/linux-2.6.23/n", 22/usr/src/linux-2.6.23) = 22
- close(1) = 0
- munmap(0xb7f5a000, 4096) = 0
- exit_group(0)
(4)系统调用和内核函数。
内核函数与C库函数的区别仅仅是内核函数在内核实现,因此必须遵守内核编程的规则。
系统调用最终必须具有明确的操作。用户应用程序通过系统调用进入内核后,会执行各个系统调用对应的内核函数,即系统调用服务例程,比如系统调用getpid的服务例程是内核函数sys_getpid。
系统调用服务例程之外,内核中存在着大量的内核函数。有些局限于某个内核文件自己使用,有些则是export出来供内核其他部分共同使用。对于export出来的内核函数,可以使用ksyms命令或通过/proc/ksyms文件查看。
说白了,系统调用是内核提供的接口,而不管是系统命令还是标准库函数,都是基于系统调用编写的应用程序,只不过是一些大牛写的啦,程序健壮,够标准,哈哈,我们自己也可以写用户程序做为自己的库函数,自己在内核代码中添加系统调用,这些都是可以做到的
5.1.2 系统调用表
系统调用表sys_call_table存储了所有系统调用对应的服务例程的函数地址,在arch/i386/kernel/syscall_table.S文件中被定义:
001 ENTRY(sys_call_table) 002 .long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting */ 003 .long sys_exit 004 .long sys_fork 005 .long sys_read 006 .long sys_write 007 .long sys_open /* 5 */ ¡¡ 320 .long sys_getcpu 321 .long sys_epoll_pwait 322 .long sys_utimensat /* 320 */ 323 .long sys_signalfd 324 .long sys_timerfd 325 .long sys_eventfd 326 .long sys_fallocate
从中可发现两个特别之处。首先,所有系统调用服务例程的命名均遵守一定的规则,即在系统调用名称之前增加"sys_"前缀,比如open系统调用对应sys_open函数。
其次,内核提供的系统调用数目非常有限,到2.6.23版本的内核也不过才达到仅仅325个,使用"man 2 syscalls"命令即可以浏览到所有系统调用的添加历史。这也是系统调用与C库函数的区别之一:系统调用通常只提供最小的接口,C库函数则在此基础之上提供更多复杂的功能。
5.1.3 系统调用号
既然系统调用表集中存放了所有系统调用服务例程的地址,那么系统调用在内核中的执行就可以转化为从该表获取对应的服务例程并执行的过程。
这个过程中一个很重要的环节就是系统调用号。每个系统调用都拥有一个独一无二的系统调用号,用户应用通过它,而不是系统调用的名称,来指明要执行哪个系统调用。
系统调用号的定义在include/asm-i386/unistd.h文件。
#define __NR_restart_syscall 0 #define __NR_exit 1 #define __NR_fork 2 #define __NR_read 3 #define __NR_write 4 #define __NR_open 5 ...... #define __NR_getcpu 318 #define __NR_epoll_pwait 319 #define __NR_utimensat 320 #define __NR_signalfd 321 #define __NR_timerfd 322 #define __NR_eventfd 323 #define __NR_fallocate 324
将其与sys_call_table的定义相比较可以发现,每个系统调用号都依次对应了sys_call_table中的某一项。内核正是将系统调用号作为下标去获取sys_call_table中的服务例程函数地址。
系统调用号与系统调用为相依相生的关系,一旦分配就不能再有任何变更,即使该系统调用被删除,它所拥有的系统调用号也不能被回收利用。
5.1.4 系统调用服务例程
系统调用最终由系统调用服务例程完成明确的操作。所有的系统调用服务例程集中声明在include/linux/syscalls.h文件,但分散定义在很多不同的文件。比如getpid系统调用用于获取当前进程的PID,它的服务例程sys_getpid在kernel/timer.c文件中定义为:
asmlinkage long sys_getpid(void) { return current->tgid; }
除了都具有"sys_"前缀之外,所有的系统调用服务例程命名与定义还必须遵守其他的一些规则。首先,函数定义中必须添加asmlinkage标记,通知编译器仅从堆栈中获取该函数的参数。
其次,必须返回一个long类型的返回值表示成功或错误,通常返回0表示成功,返回负值表示错误。当然,getpid系统调用非常简单,不可能会失败,通过命令"man 2 getpid"可以查看它的手册,里面也明确指出了这一点。
每个系统调用的系统调用号、命名以及操作目的都是固定的,但内核如何去实现并没有明确规定,不同版本、不同架构的内核实现都有可能会有所变化。
5.1.5 如何使用系统调用
如图5.2所示,用户应用可以通过两种方式使用系统调用。第一种方式是通过C库函数,包括系统调用在C库中的封装函数和其他普通函数。
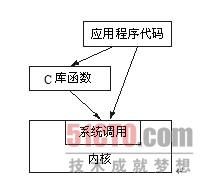
图5.2 使用系统调用的两种方式
第二种方式是使用_syscall宏。2.6.18版本之前的内核,在include/asm-i386/unistd.h文件中定义有7个_syscall宏,分别是:
_syscall0(type,name); _syscall1(type,name,type1,arg1); _syscall2(type,name,type1,arg1,type2,arg2); _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3); _syscall4(type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4); syscall5type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5); syscall6type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5,type6,arg6);
其中,type表示所生成系统调用的返回值类型,name表示该系统调用的名称,typeN、argN分别表示第N个参数的类型和名称,它们的数目和_syscall后面的数字一样大。这些宏的作用是创建名为name的函数,_syscall后面跟的数字指明了该函数的参数的个数。
比如sysinfo系统调用用于获取系统总体统计信息,使用_syscall宏定义为:
_syscall1(int, sysinfo, struct sysinfo *, info);
展开后的形式为:
int sysinfo(struct sysinfo * info) { long __res; __asm__ volatile("int $0x80" : "=a" (__res) : ""(116),"b" ((long)(info))); do { if((unsigned long)(__res) >= (unsigned long)(-(128 + 1))) { errno = -(__res); __res = -1; } return (int) (__res); } while (0); }
可以看出,_syscall1(int, sysinfo, struct sysinfo *, info)展开成一个名为sysinfo的函数,原参数int就是函数的返回类型,原参数struct sysinfo *和info分别构成新函数的参数。
在程序文件里使用_syscall宏定义需要的系统调用,就可以在接下来的代码中通过系统调用名称直接调用该系统调用。下面是一个使用sysinfo系统调用的实例。
代码清单5.1 sysinfo系统调用使用实例
#include #include #include #include #include /* for struct sysinfo */ _syscall1(int, sysinfo,struct sysinfo *, info); int main(void) { struct sysinfo s_info; int error; error = sysinfo(&s_info); printf("code error = %d/n", error); printf("Uptime = %lds/nLoad: 1 min %lu / 5 min %lu / 15 min %lu/n" "RAM: total %lu / free %lu / shared %lu/n" "Memory in buffers = %lu/nSwap: total %lu / free %lu/n" "Number of processes = %d/n", s_info.uptime, s_info.loads[0], s_info.loads[1], s_info.loads[2], s_info.totalram, s_info.freeram, s_info.sharedram, s_info.bufferram, s_info.totalswap, s_info.freeswap, s_info.procs); exit(EXIT_SUCCESS); }
但是自2.6.19版本开始,_syscall宏被废除,我们需要使用syscall函数,通过指定系统调用号和一组参数来调用系统调用。
syscall函数原型为:
int syscall(int number, ...);
其中number是系统调用号,number后面应顺序接上该系统调用的所有参数。下面是gettid系统调用的调用实例。
代码清单5.2 gettid系统调用使用实例
#include #include #include #define __NR_gettid 224 int main(int argc, char *argv[]) { pid_t tid;tid = syscall(__NR_gettid); }
大部分系统调用都包括了一个SYS_符号常量来指定自己到系统调用号的映射,因此上面紫色的部分可重写为:
tid = syscall(SYS_gettid);
5.1.6 为什么需要系统调用
为什么需要系统调用?主要有以下两方面原因。
(1)系统调用可以为用户空间提供访问硬件资源的统一接口,以至于应用程序不必去关注具体的硬件访问操作。比如,读写文件时,应用程序不用去管磁盘类型,甚至于不用关心是哪种文件系统。
(2)系统调用可以对系统进行保护,保证系统的稳定和安全。系统调用的存在规定了用户进程进入内核的具体方式,换句话说,用户访问内核的路径是事先规定好的,只能从规定位置进入内核,而不准许肆意跳入内核。有了这样的进入内核的统一访问路径限制才能保证内核的安全。
我们可以形象地描述这种机制:作为一个游客,你可以买票要求进入野生动物园,但你必须老老实实地坐在观光车上,按照规定的路线观光游览。当然,不准下车,因为那样太危险,不是让你丢掉小命,就是让你吓坏了野生动物。
5.2 系统调用执行过程
系统调用的执行过程主要包括如图5.3与图5.4所示的两个阶段:用户空间到内核空间的转换阶段,以及系统调用处理程序system_call函数到系统调用服务例程的阶段。
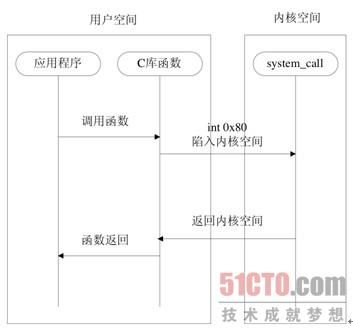
图5.3 用户空间到内核空间

图5.4 system_call函数到系统调用服务例程
(1)用户空间到内核空间。
如图5.3所示,系统调用的执行需要一个用户空间到内核空间的状态转换,不同的平台具有不同的指令可以完成这种转换,这种指令也被称作操作系统陷入(operating system trap)指令。
Linux通过软中断来实现这种陷入,具体对于X86架构来说,是软中断0x80,也即int $0x80汇编指令。软中断和我们常说的中断(硬件中断)不同之处在于-它由软件指令触发而并非由硬件外设引发。
int 0x80指令被封装在C库中,对于用户应用来说,基于可移植性的考虑,不应该直接调用int $0x80指令。陷入指令的平台依赖性,也正是系统调用需要在C库进行封装的原因之一。
通过软中断0x80,系统会跳转到一个预设的内核空间地址,它指向了系统调用处理程序(不要和系统调用服务例程相混淆),即在arch/i386/kernel/entry.S文件中使用汇编语言编写的system_call函数。
(2)system_call函数到系统调用服务例程。
很显然,所有的系统调用都会统一跳转到这个地址进而执行system_call函数,但正如前面所述,到2.6.23版为止,内核提供的系统调用已经达到了325个,那么system_call函数又该如何派发它们到各自的服务例程呢?
软中断指令int 0x80执行时,系统调用号会被放入eax寄存器,同时,sys_call_table每一项占用4个字节。这样,如图5.5所示,system_call函数可以读取eax寄存器获得当前系统调用的系统调用号,将其乘以4生成偏移地址,然后以sys_call_table为基址,基址加上偏移地址所指向的内容即是应该执行的系统调用服务例程的地址。
另外,除了传递系统调用号到eax寄存器,如果需要,还会传递一些参数到内核,比如write系统调用的服务例程原型为:
sys_write(unsigned int fd, const char * buf, size_t count);
调用write系统调用时就需要传递文件描述符fd、要写入的内容buf以及写入字节数count等几个内容到内核。ebx、ecx、edx、esi以及edi寄存器可以用于传递这些额外的参数。
正如之前所述,系统调用服务例程定义中的asmlinkage标记表示,编译器仅从堆栈中获取该函数的参数,而不需要从寄存器中获得任何参数。进入system_call函数前,用户应用将参数存放到对应寄存器中,system_call函数执行时会首先将这些寄存器压入堆栈。
对于系统调用服务例程,可以直接从system_call函数压入的堆栈中获得参数,对参数的修改也可以一直在堆栈中进行。在system_call函数退出后,用户应用可以直接从寄存器中获得被修改过的参数。
并不是所有的系统调用服务例程都有实际的内容,有一个服务例程sys_ni_syscall除了返回-ENOSYS外不做任何其他工作,在kernel/sys_ni.c文件中定义。
asmlinkage long sys_ni_syscall(void) { return -ENOSYS; }
sys_ni_syscall的确是最简单的系统调用服务例程,表面上看,它可能并没有什么用处,但是,它在sys_call_table中占据了很多位置。多数位置上的sys_ni_syscal都代表了那些已经被内核中淘汰的系统调用,比如:
.long sys_ni_syscall /* old stty syscall holder */ .long sys_ni_syscall /* old gtty syscall holder */
就分别代替了已经废弃的stty和gtty系统调用。如果一个系统调用被淘汰,它所对应的服务例程就要被指定为sys_ni_syscall。
我们并不能将它们的位置分配给其他的系统调用,因为一些老的代码可能还会使用到它们。否则,如果某个用户应用试图调用这些已经被淘汰的系统调用,所得到的结果,比如打开了一个文件,就会与预期完全不同,这将令人感到非常奇怪。
其实,sys_ni_syscall中的"ni"即表示"not implemented(没有实现)"。
系统调用通过软中断0x80陷入内核,跳转到系统调用处理程序system_call函数,并执行相应的服务例程,但由于是代表用户进程,所以这个执行过程并不属于中断上下文,而是处于进程上下文。
因此,系统调用执行过程中,可以访问用户进程的许多信息,可以被其他进程抢占(因为新的进程可能使用相同的系统调用,所以必须保证系统调用可重入),可以休眠(比如在系统调用阻塞时或显式调用schedule函数时)。
这些特点涉及进程调度的问题,在此不做深究,读者只需要理解当系统调用完成后,把控制权交回到发起调用的用户进程前,内核会有一次调度。如果发现有优先级更高的进程或当前进程的时间片用完,那么就会选择高优先级的进程或重新选择进程运行。
5.3 系统调用示例
本节通过对几个系统调用的剖析来讲解它们的工作方式。
5.3.1 sys_dup
dup系统调用的服务例程为sys_dup函数,在fs/fcntl.c文件中定义如下。
代码清单5.3 dup系统调用的服务例程
asmlinkage long sys_dup(unsigned int fildes) 193 { int ret = -EBADF; struct file * file = fget(fildes); if (file) ret = dupfd(file, 0); return ret; }
除了sys_ni_call()以外,sys_dup()称得上是最简单的服务例程之一,但是它却是Linux输入/输出重定向的基础。
在Linux中,执行一个shell命令时通常会自动打开3个标准文件:标准输入文件(stdin),通常对应终端的键盘;标准输出文件(stdout)和 标准错误输出文件(stderr),通常对应终端的屏幕。shell命令从标准输入文件中得到输入数据,将输出数据输出到标准输出文件,而将错误信息输出到标准错误文件中。
比如下面的命令:
- $cat /proc/cpuinfo
将把cpuinfo文件的内容显示到屏幕上,但是如果cat命令不带参数,则会从stdin中读取数据,并将其输出到stdout,比如:
- $cat
- Hello!
- Hello!
用户输入的每一行都将立刻被输出到屏幕上。
输入重定向是指把命令的标准输入重定向到指定的文件中,即输入可以不来自键盘,而来自一个指定的文件。所以说,输入重定向主要用于改变一个命令的输入源。
输出重定向是指把命令的标准输出或标准错误输出重新定向到指定文件中。这样,该命令的输出就不显示在屏幕上,而是写入到指定文件中。我们经常会利用输出重定向将程序或命令的log保存到指定的文件中。
那么sys_dup()又是如何完成输入/输出的重定向呢?下面通过一个例子进行说明。
当我们在shell终端下输入"echo hello"命令时,将会要求shell进程执行一个可执行文件echo,参数为"hello"。当shell进程接收到命令之后,先在/bin目录下找到echo文件(我们可以使用which命令获得命令所在的位置),然后创建一个子进程去执行/bin/echo,并将参数传递给它,而这个子进程从shell进程继承了3个标准输入/输出文件,即stdin、stdout和stderr,文件号分别为0、1、2。它的工作很简单,就是将参数"hello"写到stdout文件中,通常都是我们的屏幕上。
但是如果我们将命令改成"echo hello > txt",则在执行时输出将会被重定向到磁盘文件txt中。假定之前该shell进程只有上述3个标准文件打开,则该命令将按如下序列执行。
(1)打开或创建文件txt,如果txt中原来有内容,则清除原来的内容,其文件号为3。
(2)通过dup系统调用复制文件stdout的相关数据结构到文件号4。
(3)关闭stdout,但是由于4号文件也同时引用stdout,所以stdout文件并未真正关闭,只是腾出1号文件号位置。
(4)通过dup系统调用,复制3号文件(即文件txt),由于1号文件关闭,其位置空缺,故3号文件被复制到1号,即进程中原来指向stdout的指针指向了txt。
(5)通过系统调用fork和exec创建子进程并执行echo,子进程在执行cat前关闭3号和4号文件,只留下0、1、2三个文件,请注意,这时的1号文件已经不是stdout而是文件txt了。当cat想向stdout文件写入"hello"时自然就写入到了txt中。
(6)回到shell进程后,关闭指向txt的1号与3号文件文件,再用dup和close系统调用将2号恢复至stdout,这样shell就恢复了0、1、2三个标准输入/输出文件。
5.3.2 sys_reboot
Linux下有关关机与重启的命令主要有shutdown、reboot、halt、poweroff、telinit和init。它们都可以达到关机或重启的目的,但是每个命令的工作流程并不一样。
这些命令并不都是互相独立的,比如,poweroff、reboot即是halt的符号链接,但是它们最终都是通过reboot系统调用来完成关机或重启操作。
reboot系统调用的服务例程为sys_reboot函数,在kernel/sys.c文件中定义如下。
代码清单5.4 reboot系统调用的服务例程
asmlinkage long sys_reboot(int magic1, int magic2, unsigned int cmd, void __user * arg) { charbuffer[256]; /* We only trust the superuser with rebooting the system. */ if(!capable(CAP_SYS_BOOT)) return -EPERM; /* For safety, we require "magic" arguments. */ if (magic1 != LINUX_REBOOT_MAGIC1 ||(magic2 != LINUX_REBOOT_MAGIC2 && magic2 != LINUX_REBOOT_MAGIC2A && magic2 != LINUX_REBOOT_MAGIC2B && magic2 != LINUX_REBOOT_MAGIC2C)) return -EINVAL; /* Instead of trying to make the power_off code look like * halt when pm_power_off is not set do it the easy way.*/ if((cmd == LINUX_REBOOT_CMD_POWER_OFF) && !pm_power_off) cmd = LINUX_REBOOT_CMD_HALT; lock_kernel();switch (cmd) { case LINUX_REBOOT_CMD_RESTART: kernel_restart(NULL); break; caseLINUX_REBOOT_CMD_CAD_ON: C_A_D = 1; break; case LINUX_REBOOT_CMD_CAD_OFF: C_A_D = 0; break; caseLINUX_REBOOT_CMD_HALT: kernel_halt(); unlock_kernel(); do_exit(0); break; caseLINUX_REBOOT_CMD_POWER_OFF: kernel_power_off(); unlock_kernel(); do_exit(0); break; caseLINUX_REBOOT_CMD_RESTART2: if (strncpy_from_user(&buffer[0], arg,sizeof(buffer) - 1) < 0) { unlock_kernel(); return -EFAULT; } buffer[sizeof(buffer) - 1] = '/0'; kernel_restart(buffer);break; case LINUX_REBOOT_CMD_KEXEC: kernel_kexec(); unlock_kernel(); return -EINVAL; #ifdef CONFIG_HIBERNATION case LINUX_REBOOT_CMD_SW_SUSPEND: { int ret = hibernate(); unlock_kernel();return ret; } #endif default: unlock_kernel(); return -EINVAL; } unlock_kernel(); return 0; }
顾名思义,reboot系统调用可以用于重新启动系统,但根据所提供的参数不同,它还能够完成关机、挂起系统、允许或禁止使用Ctrl+Alt+Del组合键重启等不同的操作。我们还要特别注意内核里对sys_reboot()的注释,在使用它之前首先要使用sync命令同步磁盘,否则磁盘上的文件系统可能会有所损坏。
第901行检查调用者是否有合法权限。capable函数用于检查是否有操作指定资源的权限,如果它返回非零值,则调用者有权进行操作,否则无权操作。比如,这一行的capable(CAP_SYS_BOOT)即检查调用者是否有权限使用reboot系统调用。
第905行~第910行通过对两个参数magic1和magic2的检测,判断reboot系统调用是不是被偶然调用到的。如果reboot系统调用是被偶然调用的,那么参数magic1和magic2几乎不可能同时满足预定义的这几个数字的集合。
从第919行开始,sys_reboot()对调用者的各种使用情况进行区分。为LINUX_REBOOT_CMD_RESTART时,kernel_restart()将打印出"Restarting system."消息,然后调用machine_restart函数重新启动系统。
为LINUX_REBOOT_CMD_CAD_ON或LINUX_REBOOT_CMD_CAD_OFF时,分别允许或禁止Ctrl+Alt+Del组合键。我们还可以在/etc/inittab文件指定是否可以使用Ctrl+Alt+Del组合键来关闭并重启系统。如果希望完全禁止这个功能,需要将/etc/inittab文件中的下面一行注释掉。
- ca:12345:ctrlaltdel:/sbin/shutdown -t1 -a -r now
为LINUX_REBOOT_CMD_HALT时,打印出"System halted."消息,和LINUX_REBOOT_CMD_RESTART情况下类似,但只是暂停系统而不是将其重新启动。
为LINUX_REBOOT_CMD_POWER_OFF时,打印出"Power down."消息,然后关闭机器电源。
为LINUX_REBOOT_CMD_RESTART2时,接收命令字符串,该字符串说明了系统应该如何关闭。
最后,LINUX_REBOOT_CMD_SW_SUSPEND用于使系统休眠。
5.4 系统调用的实现
一个系统调用的实现并不需要去关心如何从用户空间转换到内核空间,以及系统调用处理程序如何去执行,你需要做的只是遵循几个固定的步骤。
5.4.1 如何实现一个新的系统调用
为Linux添加新的系统调用是件相对容易的事情,主要包括有4个步骤:编写系统调用服务例程;添加系统调用号;修改系统调用表;重新编译内核并测试新添加的系统调用。
下面以一个并无实际用处的hello系统调用为例,来演示上述几个步骤。
(1)编写系统调用服务例程。
遵循前面所述的几个原则,hello系统调用的服务例程实现为:
asmlinkage long sys_hello(void) { printk("Hello!/n"); return 0; }
通常,应该为新的系统调用服务例程创建一个新的文件进行存放,但也可以将其定义在其他文件之中并加上注释做必要说明。同时,还要在include/linux/syscalls.h文件中添加原型声明:
- asmlinkage long sys_hello(void);
sys_hello函数非常简单,仅仅打印一条语句,并没有使用任何参数。如果我们希望hello系统调用不仅能打印"hello!"欢迎信息,还能够打印出我们传递过去的名称,或者其他的一些描述信息,则sys_hello函数可以实现为:
asmlinkage long sys_hello(const char __user *_name) 02 { char *name; long ret; name = strndup_user(_name, PAGE_SIZE); 07 if (IS_ERR(name)) { ret = PTR_ERR(name); goto error; } printk("Hello, %s!/n", name); return 0; error: return ret; }
第二个sys_hello函数使用了一个参数,在这种有参数传递发生的情况下,编写系统调用服务例程时必须仔细检查所有的参数是否合法有效。因为系统调用在内核空间执行,如果不加限制任由用户应用传递输入进入内核,则系统的安全与稳定将受到影响。
参数检查中最重要的一项就是检查用户应用提供的用户空间指针是否有效。比如上述sys_hello函数参数为char类型指针,并且使用了__user标记进行修饰。__user标记表示所修饰的指针为用户空间指针,不能在内核空间直接引用,原因主要如下。
用户空间指针在内核空间可能是无效的。
用户空间的内存是分页的,可能引起页错误。
如果直接引用能够成功,就相当于用户空间可以直接访问内核空间,产生安全问题。
因此,为了能够完成必须的检查,以及在用户空间和内核空间之间安全地传送数据,就需要使用内核提供的函数。比如在sys_hello函数的第6行,就使用了内核提供的strndup_user函数(在mm/util.c文件中定义)从用户空间复制字符串name的内容。
(2)添加系统调用号。
每个系统调用都会拥有一个独一无二的系统调用号,所以接下来需要更新include/asm-i386/unistd.h文件,为hello系统调用添加一个系统调用号。
#define __NR_utimensat 320 329 #define __NR_signalfd 321 330 #define __NR_timerfd 322 331 #define __NR_eventfd 323 332 #define __NR_fallocate 324 333 #define __NR_hello 325 /*分配hello系统调用号为325*/ #ifdef __KERNEL__ #define NR_syscalls 326 /*将系统调用数目加1修改为326*/
(3)修改系统调用表。
为了让系统调用处理程序system_call函数能够找到hello系统调用,我们还需要修改系统调用表sys_call_table,放入服务例程sys_hello函数的地址。
.long sys_utimensat /* 320 */ .long sys_signalfd 324 . .long sys_timerfd 325 .long sys_eventfd 326 .long sys_fallocate 327 .long sys_hello /*hello系统调用服务例程*/
新的系统调用hello的服务例程被添加到了sys_call_table的末尾。我们可以注意到,sys_call_table每隔5个表项就会有一个注释,表明该项的系统调用号,这个好习惯可以在查找系统调用对应的系统调用号时提供方便。
(4)重新编译内核并测试。
为了能够使用新添加的系统调用,需要重新编译内核,并使用新内核重新引导系统。然后,我们还需要编写测试程序对新的系统调用进行测试。针对hello系统调用的测试程序如下:
#include #include #include #define __NR_hello 325 int main(int argc, char *argv[]) { syscall(__NR_hello); return 0; }
然后使用gcc编译并执行:
- $gcc -o hello hello.c
- $./hello
- Hello!
由执行结果可见,系统调用添加成功。
5.4.2 什么时候需要添加新的系统调用
虽说添加一个新的系统调用非常简单,但这并不意味着用户有必要这么做。添加系统调用需要修改内核源代码、重新编译内核,如果更进一步希望自己添加的系统调用能够得到广泛的应用,就需要得到官方的认可并分配一个固定的系统调用号,还需要将该系统调用在每个需要支持的体系结构上实现。因此我们最好使用其他替代方法和内核交换信息,如下所示。
使用设备驱动程序。创建一个设备节点,通过read和write函数进行读写访问,使用ioctl函数进行设置操作和获取特定信息。这种方法最大的好处在于可以模块式加载卸载,避免了编译内核等过程,而且调用接口固定,容易操作。
使用proc虚拟文件系统。利用proc接口获取系统运行信息和修订系统状态是一种很常见的手段,比如读取/proc/cpuinfo可以获得当前系统的CPU信息,通过设备驱动提供的proc接口还可以设置硬件寄存器。
sysfs文件系统。sysfs文件系统在2.6内核被引入,是一个类似于proc文件系统的特殊文件系统,用于对系统的设备进行管理,它把实际连接到系统上的设备和总线组织成层次结构,并向用户提供详细的内核数据结构信息,用户可以利用这些信息以实现和内核的交互。
上面说道的用户空间跟内核空间交互的方法加上系统调用有4种,这些都非常重要。
《UNIX 环境高级编程》一书中如此说:
所有操作系统都提供多种服务的入口点,由此程序向系统内核请求服务。各种版本的Unix都提供经良好定义的有限数目的入口点,经过这些入口点进入系统内核,这些入口点被称之为系统调用(system call),系统调用是我们不能更改的一种Unix特征。Unix版本7提供了约50个系统调用,4 3+BSD提供了约110个,而SVR4则提供了约120个。
系统调用界面总是在Unix程序员手册的第二部分中说明。其定义也包括在C语言中。这与很多较早期的操作系统是不同的,这些系统按传统都在机器的汇编语言中定义系统核入口点。
Unix所使用的技术是为每条系统调用在标准C库中设置一个具有同样名字的函数。用户进程用标准C调用序列来调用这些函数,然后,函数用系统所要求的技术调用相应的系统核服务。例如函数可将一个或几个C参数送入通用寄存器,然后执行某个产生软中断进入系统核的机器指令。从应用角度考虑,我们可将系统调用视作为C函数。
Unix程序员手册的第三部分定义了程序员可以使用的通用函数。虽然这些函数可能会调用一个或几个系统核的系统调用,但是它们并不是系统核的入口点。例如,printf函数会调用write系统调用以进行输出操作,但函数strcpy(复制一字符串)和atoi(变换ASCII为整数)并不使用任何系统调用。
从实施者的角度,系统调用和库函数之间有重大区别,但从用户角度其区别并不非常重要。从本书的目的出发,系统调用和库函数在本书中都以正常的C函数的形式出现。两者都对应用程序提供服务,但是,我们应当理解,如果希望的话,我们可以代换库函数,但是通常我们却不能代换系统服务。
以存储器分配函数malloc为例。有多种方法可以进行存储器分配及与其相关的无用区收集操作(最佳适应,首次适应等),并不存在对所有程序都最佳的一种技术。Unix系统调用中处理存储器分配的是sbrk(2),它不是一个通用的存储器管理器。它增加或减少指定字节数的进程地址空间。如何管理该地址空间却取决于进程。存储器分配函数malloc(3)实现一种特定类型的分配。如果我们不喜欢其操作方式,则我们可以定义自己的malloc函数,极其可能,它还是要调用sbrk系统调用。事实上,有很多软件包,它们实现自己的存储器分配算法,但仍使用sbrk系统调用。图1.1显示了应用程序、malloc函数以及sbrk系统调用之间的关系。
图1.2〓malloc函数和sbrk系统调用
从中可见,两者职责不同,相互分开,要核中的系统调用分配另外一块空间给进程,而库函数malloc则管理这种空间。
另一个可说明系统调用和库函数之间的差别的例子是,Unix提供决定当前时间和日期的界面。某些操作系统提供一个系统调用以返回时间,而另一个则返回日期。任何特殊的处理,例如正常时制和日光节约时制之间的转换,由系统核处理或要求人的干予。Unix则不同,它只提供一条系统调用,该系统调用返回国际标准时公元一九七年一月一日午夜来所以经过的秒数。对该值的任何解释,例如将其变换成人们可读的,使用本地时区的时间和日期,都留给用户进程运行。在标准C库中,提供了若干例程以处理大多数情况。这些库函数处理各种细节,例如各种日光节约时算法。
应用程序可以或者调用系统调用,或者库函数,而很多库函数则会调用系统调用。这在图1.3中显示。
图1.3〓C库函数和系统调用之间的差别
另一个系统调用和库函数之间的差别是:系统调用通常提供一种最小接口,而库函数通常提供比较复杂的功能。我们从sbrk系统调用和malloc库函数之间的差别中看到了这一点,在以后当比较不带缓存的I/O库数(第3章)以及标准I/O标准(在第5章)时,我们还将看到这种差别。
进程控制系统调用(fork,exec和wait)通常由用户的应用程序直接调用。(请回忆程序1.5中的基本shell)但是为了简化某些常见的情况,UNIX系统也提供了一些库函数;例如system和popen。在8.12节中,我们将说明system函数的一种实现,它使用基本的进程控制系统调用。在10.18中,我们还将强化这一实例以正确地处理信号。
为使读者了解大多数程序员应用的Unix系统界面,我们不得不既说明系统调用,又介绍某些库函数。例如若我们只说明sbrk系统调用,那么就会忽略很多应用程序使用的malloc库函数。
在本书中,除了一定要将两者相区分时,我们都将使用术语"函数"来涉及系统调用和库函数两者。
《The Linux Kernel Module Programming Guide》书中如此描述:
库函数是高层的,完全运行在用户空间, 为程序员提供调用真正的在幕后完成实际事务的系统调用的更方便的接口。系统调用在内核态运行并且由内核自己提供。标准C库函数printf()可以被看做是一个通用的输出语句,但它实际做的是将数据转化为符合格式的字符串并且调用系统调用 write()输出这些字符串。
《=================================================================================================================================》