Instagram 5位传奇工程师背后的"极简"技术(PPT全译)
http://www.csdn.net/article/2013-03-28/2814698-The-technologie-%20behind-Instagram
Instagram是一家基于iOS和Android的社交图片照片分享应用开发商。凭借着独特的运营理念,自2010年3月成立以来,短短一年的时间就吸引了1400万用户。而后随着手机相机改动、图像处理升级、与Facebook等社交灵活交互、支持Android等服务不断升级,用户量迅速冲击3000万,于2012年9月被Facebook以7.15亿美元收购。而截止到今年2月底,其活跃用户成功突破1亿。

Instagram两位创始人
与高速增长相背离的是,从成立之初仅有凯文·希斯特罗姆(Kevin Systrom)和迈克·克里格(Mike Krieger)两位创始人,到2011年获得A轮风投700万美元的4位员工,再到被收购时的13人团队,Instagram人员组织一直极为精简。
如此小规模的团队居然可以如此自如地应对飞速增长的用户数并提供创新服务,这不能不说是硅谷的又一个财富传奇。以至于Instagram技术团队撰写的《Instagram:数百的实例 大量的技术》一经发布,就获得了创业企业CTO们的热烈回应。彼时,Instagram的团队还在寻找一个“可以驯服EC2 实例群的DevOps”。
没有想到,收购如此来势汹汹。2012年4月10日,Facebook宣布收购Instagram。两天之后,Instagram的联合创始人Mike Krieger公开发表《如何成为十亿美元公司》演讲,第一次向外界全面地展现了Instagram创业历程以及其中不得不说的技术“秘密.”。本文为演讲PPT全文翻译,有助于创新技术团队更好认识和了解Instagram13人团队创造奇迹所依赖的技术:
Instagram技术团队:
2010年: 2位工程师
2011年: 3位工程师
2012年: 5位工程师
Instagram核心原则:
1 simplicity(极简主义)
2 optimize for minimal operational burden(为了最小的运营负担而优化程序;)
3 instrument everything(利用一切能用到的工具)
一、初创阶段:
两名没有任何后端的实战经验的创始人;
通过托管在洛杉矶某处的一台机器(甚至性能都没有MacBook Pro强);
存储采用CouchDB(Apache CouchDB 是一个面向文档的数据库管理系统);
产品上线第一天有25000注册用户。
二、上线阶段:
因为忘记favicon.ico图标文件,在Django上引起大量404错误。
这是第一个经验教训。后面还有:
ulimit -n ,设置Linux内核可以同时打开的文件描述符的最大值,例如size为4092。
memcached -t 4,设置用于处理请求的线程数。
prefork/postfork 线程的预加载还是后加载。
显然,绝大多数系统扩展问题繁琐而困难。而在不断出现问题并解决问题的过程中,Instagram决定迁往AWS的EC2。
三、迁移阶段:
“let’s move to EC2”就像是“对100码速度行驶的汽车更换所有部件”。

Nginx&Redis&Postgres&Django
Nginx&HAProxy&Redis&Memcached&Postgres&Gearman&Django.
具体分析:
1. 数据库扩展
早期:django ORM+postgresql(PostGIS)
因为PostGIS而选择了postgresql,PostGIS在对象关系型数据库PostgreSQL上增加了存储管理空间数据的能力,相当于Oracle的spatial部分,数据库可部署在独立服务器上。
随着照片数量的爆发式增长,最大内存为68G的EC2显然无法支持。
改变:进行vertical partitioning(垂直分区),并通过django db routers使垂直分区更加容易。
如:照片则映射到photodb
几个月以后,photodb>60G的时候,采用horizontal partitioning(水平分区,用“分片”sharding实现)
但sharding也带来诸多问题:
1). 数据检索(多数情况下,很难知道用户的主访问模式)
2). 当有分片变得太大的时候怎么办?
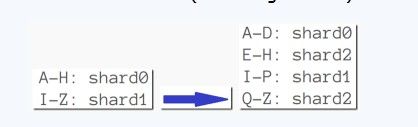
可以采用,基于范围的分片策略(如MongoDB一样)

3). 性能下降,特别是由EC2实例磁盘IO导致,解决方法是:预先切分(pre-split),即预先切分上千个逻辑切片,将它们映射到较少的物理分区节点中去。

2. 选择合适工具
进行缓存/反规范化数据设计
用户上传图片时:
1). 用户上传带有标题信息和地理位置信息(可选)的照片;
2). 同步写到这个用户对应的数据库(分片)中;
3). 进行队列化处理
a 如果带有地理位置信息,通过异步的POST请求,将这个图片的信息送到Solr(Instagram 用于geo-search API的全文检索服务器)。
b 跟随者的信息分发(follower delivery),即告诉我的follower ,我发布了新的照片。如何来实现的呢?每个用户都有一个follower 列表,新照片上传时会把照片ID发送给列表中的每一个用户,用Redis 来处理这一业务简直太棒了,快速插入,快速子集化。
c 当需要生成feed的时候,我们通过ID+#的格式,直接在memcached中查找信息
Redis适合什么样的场景?
1).数据结构相对有限;
2).对频繁GET的地方,对复杂对象进行缓存;
不要将自己绑定在非得以内存数据库为主要存储策略的方案上。
关于Follow图谱
第一版:简单的数据库表格(source_ id, target_id, status)
需要来回答如下查询:我关注谁?谁关注我?我是否关注某人?某人是否关注我?
当数据库的压力变大时,Instagram开始在Redis中并发存储关注图谱,但这也带来了内容一致性(consistency)的问题。而不一致性一度会带来缓存失效问题。
PostGIS结合轻量的memcached缓存,可以支撑上万的请求量。
需要注意点:
1). 核心数据存储部分有一个万能的组件支撑,就像:Redis;
2).千万不要试想用两种工具去做同一个工作;
3. 保持敏捷
1). 广泛的单元测试和功能测试
2). 坚持DRY(Don’t Repeat Yourself)原则
3). 使用通知/信号机制实现解耦
4). 我们大部分工作使用Python来完成,只有逼不得已的时候,才会用C
5). 频繁的代码复查,尽量保持“智慧共享”。
6). 广泛的系统监控
4. 往Android平台扩展
12小时增加100万新用户的关键:
1). 伟大的工具可以使读取更具扩展性,例如:redis: slaveof <host> <port>(SLAVEOF 命令用于在 Redis 运行时动态地修改复制(replication)功能的行为);
2). 更短的迭代周期;
3). 不要重复发明轮子,例如想开发一个系统监控的守护进程,完全没有必要,HAProxy完全能胜任这一工作;
4). 找强大的技术顾问;
5). 技术团队保持开放的氛围并积极回馈开源世界;
6). 关注优化,想办法让系统速度快上一倍。
7). 保持敏捷;
8).使用最少部件,最干净的解决方案;
9). 不要过度的优化,除非你提前知道自己的系统将如何扩展
PPT很好的保持了Instagram“simplicity”的哲学,即使提到技术,也精简到了极致。为了让更多朋友明了,特别从其工程师博客上选择更多细节来补足,而这里,是这五位工程师实践经验的 总结,其中不乏那些极为实用的开源工具。
5. 其他细节技术:( Instagram Engineering Blog上还发布了其他一些技术细节)
操作系统/主机
在Amazon EC2上跑Ubuntu Linux 11.04 (“Natty Narwhal”),这个版本经过验证在 EC2 上够稳定。但之前的版本在EC2上高流量的时候都会出现各种不可预测的问题。
负载均衡
每一个对Instagram 服务器的访问都会通过负载均衡服务器;我们使用2台Nginx机器做DNS轮询。这种方案的缺点是当其中一台退役时,需要花时间更新DNS。最近,转而使用Amazon的ELB(Elastic Load Balancer)负载均衡器,使用3个Nginx 实例可以实现调入调出(而当某个Nginx实例通不过故障检测,系统会自动将其从循环中抽离);同时在 ELB 层停掉了 SSL , 以缓解nginx的 CPU 压力。使用Amazon的Route53服务作为DNS服务,这是AWS控制台上增加的一套很好的GUI工具。
应用服务器
在Amazon的High-CPU Extra-Large机器上运行了Django ,随着用户的增长,已经在上面跑了25个Django实例了(幸运地,因为是无状态的,所以非常便于横向扩展)。但发现个别工作负载是属于计算密集型而非IO密集型,因此High-CPU Extra-Large类型的实例刚好提供了合适的比重(CPU和内存)。
为此,使用 Gunicorn 作为 WSGI 服务器。过去曾用过 Apache 下的 mod_wsgi 模块,不过发现 Gunicorn 更容易配置并且节省 CPU 资源。使用 Fabric 加速部署。Fabric最近增加了并行模式,因此部署只需要花费几秒钟。
数据存储
大部分数据(用户信息,照片的元数据、标签等)存储在PostgreSQL中;并基于不同的Postgres 实例进行切分的。主要分片集群包含12个四倍超大内存云主机(且12个副本在不同的区域);
而亚马逊的网络磁盘系统(EBS)每秒的寻道能力不够,因此,将所有工作放到内存中就变得尤为重要。为了获得合理的性能,创建了软 RAID 以提升 IO 能力,使用的 Mdadm 工具进行 RAID 管理;
这里,vmtouch用来管理内存数据是个极好的工具,尤其是在故障转移时,从一台机器到另一台机器,甚至没有活动的内存概要文件的情况。这里是脚本,用来解析运行于一台机器上的vmtouch 输出并打印出相应vmtouch命令,在另一台机器上执行,用于匹配他当前的内存状态;
所有的PostgreSQL实例都是运行于主-备模式(Master-Replica),基于流复制,并且使用EBS快照经常备份我们的系统。为了保证快照的一致性(原始灵感来源于ec2-consistent-snapshot)使用XFS作为我们的文件系统,通过XFS,当进行快照时,可以冻结&解冻RAID阵列。为了进行流复制,我们最爱的工具是repmgr 。
对于从应用服务器连接到数据,我们很早就使用了Pgbouncer做连接池,此举对性能有巨大的影响。我们发现Christophe Pettus的博客 有大量的关于Django、PostgreSQL 和Pgbouncer 秘诀的资源。
照片直接存储在亚马逊的S3,当前已经存储了几T的照片数据。使用亚马逊的CloudFront作为我们的CDN,这加快了全世界用户的照片加载时间。
为了geo-search API,我们一直使用PostgreSQL了很多个月,不过后来迁移到了Apache Solr.他有一套简单的JSON接口,这样我们的应用程序相关的,只是另一套API而已。
最后,和任何现代Web服务一样,使用了Memcached 做缓存,并且当前已经使用了6个Memcached 实例,我们使用pylibmc & libmemcached进行连接。Amzon最近启用了一个灵活的缓存服务(Elastic Cache service),但是它并不比运行我们自己的实例便宜,因此我们并没有切换上去;
任务队列&推送通知
当一个用户决定分享一张Instagram 的照片到Twitter 或Facebook,或者是当我们需要通知一个 实时订阅者有一张新的照片贴出,我们将这个任务推到 Gearman,一个任务队列系统能够写于Danga。这样做的任务队列异步通过意味着媒体上传可以尽快完成,而“重担”可以在后台运行。我们大概有200个工作实例(都用Python写的)在给定的时间内对队列中的任务进行消费,并分发给不同的服务。我们的feed feed fan-out也使用了Gearman,这样posting就会响应新用户,因为他有很多followers。
对于消息推送,找到的最划算的方案是,一个开源的Twisted 服务,已经为我们处理了超过10亿条通知,并且绝对可靠。
监控
基于 Python-Munin,写了很多Munin 插件,使用Munin进行图形化度量。用于图形化度量非系统级的东西(例如,每秒的签入人数,每条照片发布数等),使用Pingdom作为外部监控服务,PagerDuty 用于事件通知。
Python错误报告,是使用的Sentry,一个Disqus的工程师写的令人敬畏的开源的Django app。在任何时间,都可以实时的查看系统发生了什么错误。
文章到这里,并没有结束。对今天已经跨越“亿”线的Instagram而言,“为了最小的运营负担而优化程序,利用一切能用到的(开源)工具与云平台,极简的技术主张”未变,不信,看看最近的新闻,《Instagram的负载均衡武器:Eureka填补了Amazon Web Services的大缺口》还在续写属于他自己的技术传奇。(@红心李的分析对本文也有贡献,审校/仲浩)