White Elephant:开发者必备的Hadoop利器
LinkedIn是全球最大的职业社交网站,从2002年12月创立到2013年初,LinkedIn注册用户已到2亿,平均每秒增加一个新用户,86%的“财富100强企业”正在使用LinkedIn的付费解决方案,270万个公司主页在此安家落户,用户每年发起超过几十亿次搜索。为了应对这些超大数据,LinkedIn使用Hadoop进行产品开发,并且为了更好地理解LinkedIn在所有用例中的Hadoop集群使用情况,他们创建了White Elephant。
以下为文章全文:
随着Hadoop的发展,调度、容量规划和计费已成为其关键问题,这些都是公开的问题。今天,我们高兴地宣布我们开源LinkedIn的解决方案:White Elephant。
在LinkedIn,我们使用Hadoop进行产品开发(如People You May Know和Endorsements那样的预测分析应用),为了更好地理解我们在所有用例中的Hadoop集群使用情况,我们创建了White Elephant。
虽然Ganglia这样的工具提供了系统级指标,但我们还是希望能够了解每个用户在任何时间所使用的资源。White Elephant解析Hadoop日志为Hadoop集群提供了逐层向下监视以及任务统计汇总,包括总任务时间、使用的时段、CPU时间和失败的工作项。
White Elephant满足了以下几个需求:
- 调度:White Elephant具有在利用率较低的时段安排工作的能力,最大限度地提高集群效率。
- 容量规划:可计划未来的硬件需求,了解作业资源使用量的增长。
- 计费:Hadoop集群的容量有限,所以在多租户环境中White Elephant可针对作业商业价值的大小来分配使用的资源。
在这篇文章中,我们将分享White Elephant的架构,并展示了一些它提供的可视化效果。我们已在GitHub上公布代码,你可以自己尝试一下!
架构
White Elephant架构图
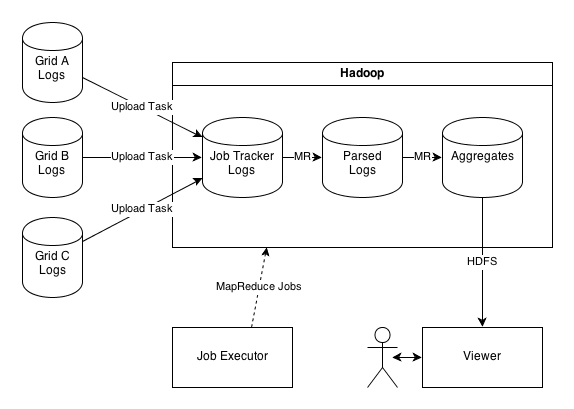
这张图里分别有A、B、C这三个Hadoop网格,White Elephant将计算统计如下:
- 上传任务:任务定期运行在Job Tracker上,并逐步拷贝新的日志文件到一个Hadoop网格进行分析。
- 计算: MapReduce作业的顺序通过Job Executor进行协调,解析上传的日志并计算汇总统计。
- 查看:一个查看器应用逐步加载汇总统计数据,缓存到本地,并公开一个Web界面,该做法可以细分Hadoop集群的统计数据。
例子
以下是我们实际使用的情况:我们在过去几个月里注意到集群使用情况的增加,但没人对此负责。我们可以使用White Elephant来调查这个问题。
下图显示了过去几个月里一个示例数据集每周被使用的总时数,你会注意到,自1月中旬以来,每周的集群使用量基线从6000小时大约增加到了10000小时。
在上图中,整个数据集都被挑选出来检查,因此所有用户的数据都被组合在一起,让我们看看前20名用户的堆叠图。
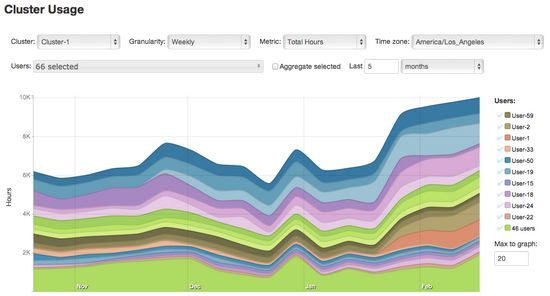
现在我们可以看到前20名用户的个人每周使用情况。剩下的46个用户已经被组合成一个单一的指标。几个用户在可疑的集群使用组中脱颖而出,所以我们将进行更深的挖掘。
我们可以将鼠标悬停在图例上来突出显示这些用户。
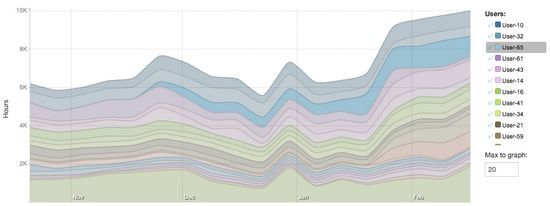
使用拖放操作,我们可以重新安排列表以便这些用户出现在底部。
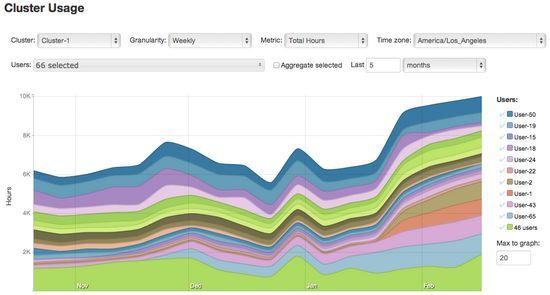
看起来像4个用户已展示出显著的使用率增加:用户1和用户2的使用量在1月中旬开始增加,而用户43和用户65的使用量在12月左右开始稳步攀升。
如果我们不希望看到这些用户的集群使用情况,我们可以在图例中取消对他们的选中。
一旦我们排除了这些用户,我们可以看到集群的使用情况在这段时间内没有明显地改变,因此我们已经确定了我们的罪魁祸首。
让我们追溯这四个用户,用户可以选择一个多选控制,一个过滤器使它很容易通过名字来搜索特定的用户。
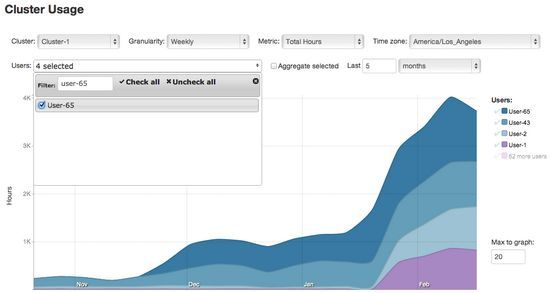
如何将这四个用户与其他人相比呢?为方便起见,其余用户被聚合在一起,包括:只选择总指标,并将其移动到顶部。
通过White Elephant,我们已经找到了问题所在,这要归功于Hadoop使用情况中前所未有的可视性。我们甚至可以得到一个表,从CSV中列出被查询的数据。

开源
White Elephant是开源的,并且可在Apache 2许可下自由使用。像往常一样,我们欢迎贡献!(王旭东/编译 仲浩/审校)
www.haida360.com