急性子的开源大数据,第 1 部分: Hadoop 教程
转载:http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1209hadoopbigdata/index.html
关于大数据,有很多令人兴奋的事情,但使用它也带来了很多困惑。本文将提供一个可行的大数据定义,然后完成一系列示例,让您可以对在大数据领域领先的开源技术 Hadoop 的一些功能有直接的了解。具体来说,我们集中讨论以下几个问题。
- 什么是大数据、Hadoop、Sqoop、Hive 和 Pig,为什么这个领域有这么多让人兴奋的事情?
- Hadoop 与 IBM DB2 及 Informix 有何关系?这些技术可以配合使用吗?
- 我如何开始使用大数据?有哪些简单的示例可以在单台 PC 上运行?
- 对于超级的急性子,如果您已经可以定义 Hadoop 并希望马上使用代码样例,那么请执行以下操作。
- 启动您的 Informix 或 DB2 实例。
- 从 Cloudera 网站下载 VMWare 映像,并将虚拟机 RAM 设置增加至 1.5 GB。
- 直接跳到包含代码样例的部分。
- VMWare 映像中已内置了一个 MySQL 实例。如果您在没有网络连接的情况下做练习,请使用 MySQL 示例。
对于所有其他人,请继续阅读...
什么是大数据?
大数据的数量庞大、捕获速度极快,且可以是结构化的也可以是非结构化的,或者是上述特点的某种组合。这些因素使得大数据难以使用传统的方法进行捕获、挖掘和管理。在该领域有如此多的炒作,以至于仅仅是大数据的定义就有可能是长期的争论战。
使用大数据技术并不局限于庞大的数量。本文中的示例使用小样本阐述该技术的功能。截至 2012 年,大 集群均在 100 PB 的范围内。
大数据既可以是结构化的,也可以是非结构化的。传统的关系型数据库(如 Informix 和 DB2)为结构化数据提供了行之有效的解决方案。它们还可以通过可扩展性来管理非结构化数据。Hadoop 技术为处理包含结构化和非结构化数据的海量数据存储带来了更方便的新编程技术。
回页首
为什么有这么多令人兴奋的事情?
有很多因素推动了围绕大数据的炒作,具体包括以下因素。
- 在商用硬件上结合计算和存储:其结果是以低成本实现惊人的速度。
- 性价比:Hadoop 大数据技术提供了显著的成本节约(系数大约为 10),以及显著的性能改进(同样,系数为 10)。您的成就可能会有所不同。如果现有的技术输得如此一塌糊涂,那么就值得研究 Hadoop 是否可以补充或取代您当前架构的某些方面。
- 线性可扩展性:每一个并行技术都声称可以垂直扩展。Hadoop 具有真正的可扩展性,因为最新的版本将节点数量的限制扩展至 4,000 个以上。
- 可完全访问非结构化数据:具备良好的并行编程模型 MapReduce 的高度可扩展的数据存储在本行业中成为挑战已经有一段时间了。Hadoop 的编程模型并不能解决所有问题,但它对于许多任务来说都是一个强大的解决方案。
术语突破性技术 经常被严重过度使用,但在这种情况下,它可能是适当的。
回页首
什么是 Hadoop?
以下是 Hadoop 的几种定义,每种定义都针对的是企业内的不同受众:
- 对于高管:Hadoop 是 Apache 的一个开源软件项目,目的是从令人难以置信的数量/速度/多样性等有关组织的数据中获取价值。使用数据,而不是扔掉大部分数据。
- 对于技术管理人员:一个开源软件套件,挖掘有关您的企业的结构化和非结构化大数据。Hadoop 集成您现有的商业智能生态系统。
- 法律:一个由多个供应商打包和支持的开源软件套件。请参阅 参考资料 部分中关于 IP 保障的内容。
- 工程:大规模并行、无共享、基于 Java 的 map-reduce 执行环境。打算使用数百台到数千台计算机处理相同的问题,具有内置的故障恢复能力。Hadoop 生态系统中的项目提供了数据加载、更高层次的语言、自动化的云部署,以及其他功能。
- 安全性:由 Kerberos 保护的软件套件。
Hadoop 的组件有哪些?
Apache Hadoop 项目有两个核心组件,被称为 Hadoop 分布式文件系统 (Hadoop Distributed File System, HDFS) 的文件存储,以及被称为 MapReduce 的编程框架。有一些支持项目充分利用了 HDFS 和 MapReduce。本文将提供一个概要,并鼓励您参阅 OReily 的书 “Hadoop The Definitive Guide”(第 3 版)了解更多详细信息。
下面的定义是为了提供足够的背景,让您可以使用随后的代码示例。本文的真正意义在于让您开始该技术的实践经验。这是一篇 “指南” 性质的文章,而不是一篇 “内容介绍” 或 “讨论” 类型的文章。
- HDFS:如果您希望有 4000 多台电脑处理您的数据,那么最好将您的数据分发给 4000 多台电脑。HDFS 可以帮助您做到这一点。HDFS 有几个可以移动的部件。Datanodes 存储数据,Namenode 跟踪存储的位置。还有其他部件,但这些已经足以使您开始了。
- MapReduce:这是一个面向 Hadoop 的编程模型。有两个阶段,毫不意外,它们分别被称为 Map 和 Reduce。如果希望给您的朋友留下深刻的印象,那么告诉他们,Map 和 Reduce 阶段之间有一个随机排序。JobTracker 管理您的 MapReduce 作业的 4000 多个组件。TaskTracker 从 JobTracker 接受订单。如果您喜欢 Java,那么用 Java 编写代码。如果您喜欢 SQL 或 Java 以外的其他语言,您的运气仍然不错,您可以使用一个名为 Hadoop Streaming 的实用程序。
- Hadoop Streaming:一个实用程序,在任何语言(C、Perl 和 Python、C++、Bash 等)中支持 MapReduce 代码。示例包括一个 Python 映射程序和一个 AWK 缩减程序。
- Hive 和 Hue:如果您喜欢 SQL,您会很高兴听到您可以编写 SQL,并使用 Hive 将其转换为一个 MapReduce 作业。不,您不会得到一个完整的 ANSI-SQL 环境,但您的确得到了 4000 个注释和多 PB 级的可扩展性。Hue 为您提供了一个基于浏览器的图形界面,可以完成您的 Hive 工作。
- Pig: 一个执行 MapReduce 编码的更高层次的编程环境。Pig 语言被称为 Pig Latin。您可能会发现其命名约定有点不合常规,但是您会得到令人难以置信的性价比和高可用性。
- Sqoop:在 Hadoop 和您最喜爱的关系数据库之间提供双向数据传输。
- Oozie:管理 Hadoop 工作流。这并不能取代您的调度程序或 BPM 工具,但它在您的 Hadoop 作业中提供 if-then-else 分支和控制。
- HBase:一个超级可扩展的键值存储。它的工作原理非常像持久的散列映射(对于 Python 爱好者,可以认为是词典)。尽管其名称是 HBase,但它并不是一个关系数据库。
- FlumeNG:一个实时的加载程序,用来将数据流式传输到 Hadoop 中。它将数据存储在 HDFS 和 HBase 中。您会希望从 FlumeNG 开始,因为它对原始的水槽有所改进。
- Whirr:面向 Hadoop 的云配置。您可以在短短几分钟内使用一个很短的配置文件启动一个集群。
- Mahout:面向 Hadoop 的机器学习。用于预测分析和其他高级分析。
- Fuse:让 HDFS 系统看起来就像一个普通的文件系统,所以您可以对 HDFS 数据使用 ls、rm、cd 和其他命令。
- Zookeeper:用于管理集群的同步性。您不需要为 Zookeeper 做很多事情,但它在为您努力工作。如果您认为自己需要编写一个使用 Zookeeper 的程序,您要么非常非常聪明,并且可能是 Apache 项目的一个委员会,要么终将会有过得非常糟糕的一天。
图 1 显示了 Hadoop 的关键部分。
图 1. Hadoop 架构

HDFS(底层)位于商品硬件的集群之上。简单的机架式服务器,每台都配置 2 个十六核 CPU、6 到 12 个磁盘,以及 32G RAM。在一个 map-reduce 作业中,映射程序层以极高的速度从磁盘读取。映射程序向缩减程序发出已进行排序和提供的键值对,然后,缩减程序层汇总键值对。不,您不必汇总,实际上,您的 map-reduce 作业中可以只包含映射程序。当您学习 Python-awk 示例时,这应该会变得更容易理解。
Hadoop 如何与我的 Informix 或 DB2 基础架构集成?
Hadoop 利用 Sqoop 可以与 Informix 和 DB2 数据库很好地集成。Sqoop 是领先的开源实现,用于在 Hadoop 和关系数据库之间移动数据。它使用 JDBC 来读取和写入 Informix、DB2、MySQL、Oracle 和其他数据源。有几个数据库都有优化的适配器,包括 Netezza 和 DB2。请参阅 参考资料 部分,了解如何下载这些适配器。这些示例都是特定于 Sqoop 的示例。
回页首
入门:如何运行简单的 Hadoop、Hive、Pig、Oozie 和 Sqoop 示例
您已经完成了简介和定义,现在是时候来点好东西了。要继续下去,您就需要从 Cloudera 的 Web 站点下载 VMware、虚拟盒或其他映像,并开始执行 MapReduce!虚拟映像假设您有一台 64 位的计算机和流行的虚拟化环境之一。大多数虚拟化环境都提供免费下载。当您尝试启动一个 64 位的虚拟映像时,您可能会看到有关 BIOS 设置的投诉。图 2 显示了在 BIOS 中所要求的更改,在本例中使用的是 Thinkpad™。进行更改时,请务必小心。更改 BIOS 设置后,一些企业安全软件包在系统重新启动之前将需要一个密码。
图 2. 一个 64 位虚拟来宾的 BIOS 设置

这里使用的大数据其实相当小。目的是不要让您的笔记本电脑因为持续使用一个巨大的文件而着火,而只是向您显示感兴趣的数据的来源,以及回答有意义的问题的 map-reduce 作业。
下载 Hadoop 虚拟映像
我们强烈建议您使用 Cloudera 映像运行这些示例。Hadoop 是一个解决问题的技术。Cloudera 映像包使您能够专注于大数据的问题。但是,如果您决定自己组装所有部件,那么 Hadoop 就会成为一个问题,而不是解决方案。
下载一个映像。CDH4 映像是此处可提供的最新产品:CDH4 映像。上一个版本 CDH3 在此处提供:CDH3 映像。
您可以自己选择虚拟化技术。可以从 VMware 和其他网站下载一个免费的虚拟化环境。例如,访问 vmware.com 并下载 vmware-player。您的笔记本电脑可能在运行 Windows,所以您需要下载 vmware-player for windows。本文中的示例将使用 VMWare,并使用 “tar”(而不是 “winzip” 或等效的软件)来运行 Ubuntu Linux。
下载之后,untar/unzip 如下所示:tar -zxvf cloudera-demo-vm-cdh4.0.0-vmware.tar.gz。
或者,如果您使用 CDH3,那么使用以下命令:tar -zxvf cloudera-demo-vm-cdh3u4-vmware.tar.gz。
tar 文件一般可以解压缩。解压缩后,您可以启动映像,如下所示:
vmplayer cloudera-demo-vm.vmx。
现在,您将看到的屏幕类似于图 3 所示。
图 3. Cloudera 虚拟映像
vmplayer 命令一矢中的,并启动虚拟机。如果您使用的是 CDH3,那么您需要关闭机器并更改内存设置。使用屏幕中下方的时钟旁边的电源按钮图标关闭虚拟机电源。然后,您可以编辑虚拟机设置的访问权限。
对于 CDH3,下一个步骤是在虚拟映像中增加更多的 RAM。大多数设置只能在虚拟机的电源关闭时进行更改。图 4 显示了如何访问设置和将所分配的 RAM 增加至超过 2GB。
图 4. 对虚拟机增加 RAM
如图 5 所示,您可以将网络设置更改为桥接。使用此设置,虚拟机将会获得自己的 IP 地址。如果这会在您的网络上引起问题,那么您可以选择使用网络地址转换 (NAT)。您将要使用网络来连接到数据库。
图 5. 将网络设置更改为桥接

您受限于主机系统上的 RAM,所以不要尝试让分配的 RAM 多于您的计算机上现有的 RAM。如果这样做了,计算机运行速度会很慢。
现在,正是您一直期待的时刻,去启动虚拟机吧。用户 cloudera 是在启动时自动登录。如果您需要它,Cloudera 的密码是:cloudera。
安装 Informix 和 DB2
您将需要使用一个数据库。如果您还没有数据库,那么您可以在这里下载 Informix 开发版,或 DB2 Express-C 免费版。
安装 DB2 的另一种方法是下载已经在 SuSE Linux 操作系统上安装了 DB2 的 VMWare 映像。以 root 身份登录,密码是:password。
切换到 db2inst1 userid。以 root 身份工作,就像开车没有系安全带一样。请和您本地友好的 DBA 谈谈有关让数据库运行的问题。本文将不再赘述。不要尝试在 Cloudera 虚拟映像内安装数据库,因为没有足够的可用磁盘空间。
虚拟机将使用 Sqoop 连接到数据库,这需要一个 JDBC 驱动程序。在虚拟映像中,您将需要一个面向您的数据库的 JDBC 驱动程序。您可以安装这里的 Informix 驱动程序。
此处提供了 DB2 驱动程序:http://www.ibm.com/services/forms/preLogin.do?source=swg-idsdjs 或 http://www-01.ibm.com/support/docview.wss?rs=4020&uid=swg21385217。
Informix JDBC 驱动程序(记住,只是虚拟映像中的驱动程序,不是数据库中的驱动程序)安装如清单 1 所示。
清单 1. Informix JDBC 驱动程序安装
tar -xvf ../JDBC.3.70.JC5DE.tar
followed by
java -jar setup.jar
|
注意:选择一个与 /home/cloudera 有关的子目录,那么安装时就不会需要 root 权限。
DB2 JDBC 驱动程序是压缩格式的,只需将它解压缩到目标目录中,如清单 2 所示。
清单 2. DB2 JDBC 驱动程序安装
mkdir db2jdbc
cd db2jdbc
unzip ../ibm_data_server_driver_for_jdbc_sqlj_v10.1.zip
|
快速了解 HDFS 和 MapReduce
在您开始在关系数据库和 Hadoop 之间移动数据之前,需要快速了解一下 HDFS 和 MapReduce。有很多 “Hello World” 风格的 Hadoop 教程,所以这里的示例只是为了提供足够的背景知识,以使数据库练习对您有意义。
HDFS 在集群中跨节点提供存储空间。使用 Hadoop 的第一步是将数据放入 HDFS 中。如清单 3 所示的代码获得 Mark Twain 的一本书和 James Fenimore 的一本书的副本,并将这些文本复制到 HDFS 中。
清单 3. 将 Mark Twain 和 James Fenimore Cooper 加载到 HDFS 中
# install wget utility into the virtual image
sudo yum install wget
# use wget to download the Twain and Cooper's works
$ wget -U firefox http://www.gutenberg.org/cache/epub/76/pg76.txt
$ wget -U firefox http://www.gutenberg.org/cache/epub/3285/pg3285.txt
# load both into the HDFS file system
# first give the files better names
# DS for Deerslayer
# HF for Huckleberry Finn
$ mv pg3285.txt DS.txt
$ mv pg76.txt HF.txt
# this next command will fail if the directory already exists
$ hadoop fs -mkdir /user/cloudera
# now put the text into the directory
$ hadoop fs -put HF.txt /user/cloudera
# way too much typing, create aliases for hadoop commands
$ alias hput="hadoop fs -put"
$ alias hcat="hadoop fs -cat"
$ alias hls="hadoop fs -ls"
# for CDH4
$ alias hrmr="hadoop fs -rm -r"
# for CDH3
$ alias hrmr="hadoop fs -rmr"
# load the other article
# but add some compression because we can
$ gzip DS.txt
# the . in the next command references the cloudera home directory
# in hdfs, /user/cloudera
$ hput DS.txt.gz .
# now take a look at the files we have in place
$ hls
Found 2 items
-rw-r--r-- 1 cloudera supergroup 459386 2012-08-08 19:34 /user/cloudera/DS.txt.gz
-rw-r--r-- 1 cloudera supergroup 597587 2012-08-08 19:35 /user/cloudera/HF.txt
|
现在,在 HDFS 中的目录里面有两个文件。请控制您的兴奋。真的,在单个节点上,只有约 1 兆字节的数据,这就像看着油漆变干那样令人兴奋。但是,如果这是一个具有 400 个节点的集群,而您有 5 PB 数据,那么您真的很难控制自己的兴奋程度。
很多 Hadoop 教程使用示例 jar 文件中所包含的单词计数示例。事实证明,大量分析都涉及计数和汇总。清单 4 中的示例显示如何调用计数器。
清单 4. 对 Twain 和 Cooper 的单词进行计数
# hadoop comes with some examples
# this next line uses the provided java implementation of a
# word count program
# for CDH4:
hadoop jar /usr/lib/hadoop-0.20-mapreduce/hadoop-examples.jar wordcount HF.txt HF.out
# for CDH3:
hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out
# for CDH4:
hadoop jar /usr/lib/hadoop-0.20-mapreduce/hadoop-examples.jar wordcount DS.txt.gz DS.out
# for CDH3:
hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount DS.txt.gz DS.out
|
DS.txt.gz 上的 .gz 后缀告诉 Hadoop 要在 map-reduce 处理过程中处理解压缩。Cooper 的单词有点冗长,所以应该进行压缩。
运行您的单词计数作业会产生相当多的消息流。Hadoop 很乐意为您提供有关以您的名义运行的映射和缩减程序的大量详细信息。您要寻找的关键行如清单 5 所示,包括失败作业的第二列表,以及如何解决您在运行 MapReduce 时会遇到的最常见错误之一。
清单 5. MapReduce 消息 - “快乐之路”
$ hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out
12/08/08 19:23:46 INFO input.FileInputFormat: Total input paths to process : 1
12/08/08 19:23:47 WARN snappy.LoadSnappy: Snappy native library is available
12/08/08 19:23:47 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/08/08 19:23:47 INFO snappy.LoadSnappy: Snappy native library loaded
12/08/08 19:23:47 INFO mapred.JobClient: Running job: job_201208081900_0002
12/08/08 19:23:48 INFO mapred.JobClient: map 0% reduce 0%
12/08/08 19:23:54 INFO mapred.JobClient: map 100% reduce 0%
12/08/08 19:24:01 INFO mapred.JobClient: map 100% reduce 33%
12/08/08 19:24:03 INFO mapred.JobClient: map 100% reduce 100%
12/08/08 19:24:04 INFO mapred.JobClient: Job complete: job_201208081900_0002
12/08/08 19:24:04 INFO mapred.JobClient: Counters: 26
12/08/08 19:24:04 INFO mapred.JobClient: Job Counters
12/08/08 19:24:04 INFO mapred.JobClient: Launched reduce tasks=1
12/08/08 19:24:04 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=5959
12/08/08 19:24:04 INFO mapred.JobClient: Total time spent by all reduces...
12/08/08 19:24:04 INFO mapred.JobClient: Total time spent by all maps waiting...
12/08/08 19:24:04 INFO mapred.JobClient: Launched map tasks=1
12/08/08 19:24:04 INFO mapred.JobClient: Data-local map tasks=1
12/08/08 19:24:04 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9433
12/08/08 19:24:04 INFO mapred.JobClient: FileSystemCounters
12/08/08 19:24:04 INFO mapred.JobClient: FILE_BYTES_READ=192298
12/08/08 19:24:04 INFO mapred.JobClient: HDFS_BYTES_READ=597700
12/08/08 19:24:04 INFO mapred.JobClient: FILE_BYTES_WRITTEN=498740
12/08/08 19:24:04 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=138218
12/08/08 19:24:04 INFO mapred.JobClient: Map-Reduce Framework
12/08/08 19:24:04 INFO mapred.JobClient: Map input records=11733
12/08/08 19:24:04 INFO mapred.JobClient: Reduce shuffle bytes=192298
12/08/08 19:24:04 INFO mapred.JobClient: Spilled Records=27676
12/08/08 19:24:04 INFO mapred.JobClient: Map output bytes=1033012
12/08/08 19:24:04 INFO mapred.JobClient: CPU time spent (ms)=2430
12/08/08 19:24:04 INFO mapred.JobClient: Total committed heap usage (bytes)=183701504
12/08/08 19:24:04 INFO mapred.JobClient: Combine input records=113365
12/08/08 19:24:04 INFO mapred.JobClient: SPLIT_RAW_BYTES=113
12/08/08 19:24:04 INFO mapred.JobClient: Reduce input records=13838
12/08/08 19:24:04 INFO mapred.JobClient: Reduce input groups=13838
12/08/08 19:24:04 INFO mapred.JobClient: Combine output records=13838
12/08/08 19:24:04 INFO mapred.JobClient: Physical memory (bytes) snapshot=256479232
12/08/08 19:24:04 INFO mapred.JobClient: Reduce output records=13838
12/08/08 19:24:04 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1027047424
12/08/08 19:24:04 INFO mapred.JobClient: Map output records=113365
|
所有这些信息有什么意义呢?Hadoop 已经做了很多工作,并且尝试告诉您这些工作,具体包括以下内容。
- 检查输入文件是否存在。
- 检查输出目录是否存在,如果存在,中止作业。没有什么比因为一个简单的键盘错误而要重写数小时的计算更糟糕的了。
- 将 Java jar 文件分发到负责执行工作的所有节点。在本例中,只有一个节点。
- 运行作业的映射程序阶段。通常情况下,这会解析输入文件,并发出一个键值对。注意:键和值可以是对象。
- 运行排序阶段,这会根据键对映射程序输出进行排序。
- 运行归约阶段,这通常会汇总键值流,并将输出写入 HDFS 中。
- 创建多个进度指标。
图 6 显示了运行 Hive 练习后的 Hadoop 作业指标的一个样例 Web 页面。
图 6. Hadoop 的样例 Web 页面
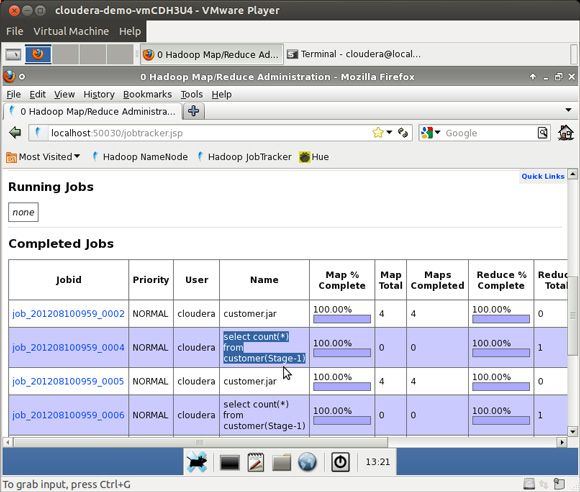
作业执行了什么,其输出在哪里?这两个都是很好的问题,如清单 6 所示。
清单 6. map-reduce 输出
# way too much typing, create aliases for hadoop commands
$ alias hput="hadoop fs -put"
$ alias hcat="hadoop fs -cat"
$ alias hls="hadoop fs -ls"
$ alias hrmr="hadoop fs -rmr"
# first list the output directory
$ hls /user/cloudera/HF.out
Found 3 items
-rw-r--r-- 1 cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out/_SUCCESS
drwxr-xr-x - cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out/_logs
-rw-r--r-- 1 cl... sup... 138218 2012-08-08 19:38 /user/cloudera/HF.out/part-r-00000
# now cat the file and pipe it to the less command
$ hcat /user/cloudera/HF.out/part-r-00000 | less
# here are a few lines from the file, the word elephants only got used twice
elder, 1
eldest 1
elect 1
elected 1
electronic 27
electronically 1
electronically, 1
elegant 1
elegant!--'deed 1
elegant, 1
elephants 2
|
在该事件中,您运行了两次相同的作业,但却忘记了删除输出目录,您将收到如清单 7 所示的错误消息。要修复这个错误很简单,只需要删除该目录即可。
清单 7. MapReduce 消息 - 由于 HDFS 中已经存在输出而引起的失败
# way too much typing, create aliases for hadoop commands
$ alias hput="hadoop fs -put"
$ alias hcat="hadoop fs -cat"
$ alias hls="hadoop fs -ls"
$ alias hrmr="hadoop fs -rmr"
$ hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out
12/08/08 19:26:23 INFO mapred.JobClient:
Cleaning up the staging area hdfs://0.0.0.0/var/l...
12/08/08 19:26:23 ERROR security.UserGroupInformation: PriviledgedActionException
as:cloudera (auth:SIMPLE)
cause:org.apache.hadoop.mapred.FileAlreadyExistsException:
Output directory HF.out already exists
org.apache.hadoop.mapred.FileAlreadyExistsException:
Output directory HF.out already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.
checkOutputSpecs(FileOutputFormat.java:132)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:872)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:833)
.... lines deleted
# the simple fix is to remove the existing output directory
$ hrmr HF.out
# now you can re-run the job successfully
# if you run short of space and the namenode enters safemode
# clean up some file space and then
$ hadoop dfsadmin -safemode leave
|
Hadoop 包括一个检查 HDFS 状态的浏览器界面。图 7 显示了单词计数作业的输出。
图 7. 使用浏览器查看 HDFS
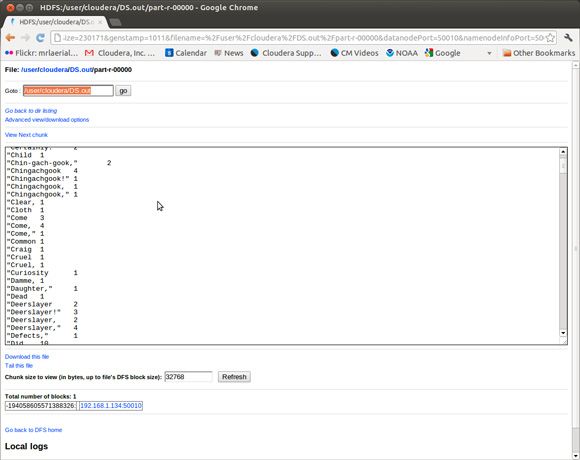
Cloudera 网站免费提供了一个更复杂的控制台。这个控制台提供了大量超出标准 Hadoop Web 界面的功能。请注意,图 8 所示的 HDFS 健康状态为 Bad。
图 8. 由 Cloudera Manager 管理的 Hadoop 服务
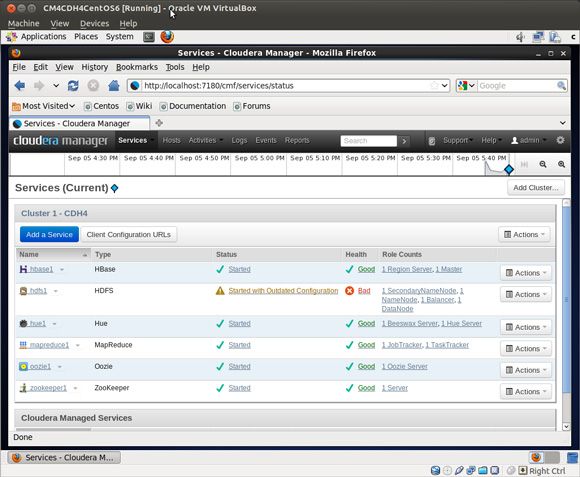
为什么是 Bad(不好)?因为在单个虚拟机中,HDFS 无法制作数据块的三个副本。当块不足以复制时,就会存在数据丢失的风险,因此系统的健康状态是不好的。您没有尝试在单个节点上运行生产 Hadoop 作业,这是好事。
您的 MapReduce 作业并不会受限于 Java。最后这个 MapReduce 示例使用 Hadoop Streaming 支持用 Python 编写的一个映射程序和用 AWK 编写的缩减程序。不,您不必是一个 Java 大师也可以编写 map-reduce!
Mark Twain 并不是 Cooper 的铁杆粉丝。在这个用例中,Hadoop 将提供比较 Twain 和 Cooper 的一些简单的文学评论。Flesch-Kincaid 测试对特定文本的阅读级别进行计算。此分析的因素之一是句子的平均长度。解析句子原来比只是查找句号字符要复杂得多。openNLP 包和 Python NLTK 包有出色的句子分析程序。为了简单起见,清单 8 中的示例将使用字长替代一个单词中的音节数。如果您想将这项工作带到一个新的水平,在 MapReduce 中实施 Flesch-Kincaid 测试,抓取 Web,并计算出您最喜爱的新闻站点的阅读级别。
清单 8. 基于 Python 的映射程序文学评论
# here is the mapper we'll connect to the streaming hadoop interface
# the mapper is reading the text in the file - not really appreciating Twain's humor
#
# modified from
# http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
$ cat mapper.py
#!/usr/bin/env python
import sys
# read stdin
for linein in sys.stdin:
# strip blanks
linein = linein.strip()
# split into words
mywords = linein.split()
# loop on mywords, output the length of each word
for word in mywords:
# the reducer just cares about the first column,
# normally there is a key - value pair
print '%s %s' % (len(word), 0)
|
针对单词 “Twain” 的映射程序输出将是 5 0。字长按数值顺序进行排序,并按排序顺序提交给缩减程序。在清单 9 和清单 10 中的示例中,不需要对数据进行排序,就可以得到正确的输出,但排序是内置在 MapReduce 基础架构中的,无论如何都会发生。
清单 9. 用于文学评论的 AWK 缩减程序
# the awk code is modified from http://www.commandlinefu.com
# awk is calculating
# NR - the number of words in total
# sum/NR - the average word length
# sqrt(mean2/NR) - the standard deviation
$ cat statsreducer.awk
awk '{delta = $1 - avg; avg += delta / NR; \
mean2 += delta * ($1 - avg); sum=$1+sum } \
END { print NR, sum/NR, sqrt(mean2 / NR); }'
|
清单 10. 使用 Hadoop Streaming 运行 Python 映射程序和 AWK 缩减程序
# test locally
# because we're using Hadoop Streaming, we can test the
# mapper and reducer with simple pipes
# the "sort" phase is a reminder the keys are sorted
# before presentation to the reducer
#in this example it doesn't matter what order the
# word length values are presented for calculating the std deviation
$ zcat ../DS.txt.gz | ./mapper.py | sort | ./statsreducer.awk
215107 4.56068 2.50734
# now run in hadoop with streaming
# CDH4
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-input HF.txt -output HFstats -file ./mapper.py -file \
./statsreducer.awk -mapper ./mapper.py -reducer ./statsreducer.awk
# CDH3
$ hadoop jar /usr/lib/hadoop-0.20/contrib/streaming/hadoop-streaming-0.20.2-cdh3u4.jar \
-input HF.txt -output HFstats -file ./mapper.py -file ./statsreducer.awk \
-mapper ./mapper.py -reducer ./statsreducer.awk
$ hls HFstats
Found 3 items
-rw-r--r-- 1 cloudera supergroup 0 2012-08-12 15:38 /user/cloudera/HFstats/_SUCCESS
drwxr-xr-x - cloudera supergroup 0 2012-08-12 15:37 /user/cloudera/HFstats/_logs
-rw-r--r-- 1 cloudera ... 24 2012-08-12 15:37 /user/cloudera/HFstats/part-00000
$ hcat /user/cloudera/HFstats/part-00000
113365 4.11227 2.17086
# now for cooper
$ hadoop jar /usr/lib/hadoop-0.20/contrib/streaming/hadoop-streaming-0.20.2-cdh3u4.jar \
-input DS.txt.gz -output DSstats -file ./mapper.py -file ./statsreducer.awk \
-mapper ./mapper.py -reducer ./statsreducer.awk
$ hcat /user/cloudera/DSstats/part-00000
215107 4.56068 2.50734
|
Mark Twain 的粉丝若知道 Hadoop 发现 Cooper 使用较长的单词,并且其标准偏差令人震惊,那么他们就可以愉快地放松了(幽默意图)。当然,要是假设较短的单词会更好。让我们继续,下一步是将 HDFS 中的数据写入 Informix 和 DB2。
使用 Sqoop 通过 JDBC 将来自 HDFS 的数据写入 Informix、DB2 或 MySQL
Sqoop Apache 项目是一个开源的基于 JDBC 的 Hadoop,用于数据库的数据移动实用程序。Sqoop 最初由在 Cloudera 的黑客马拉松 (hackathon) 创建,后来成为开源的工具。
将数据从 HDFS 移动到关系数据库是一种常见的用例。HDFS 和 map-reduce 在执行繁重工作方面是非常棒的。对于简单的查询或 Web 站点的后端存储,在关系存储区中缓存 map-reduce 输出是一个很好的设计模式。您可以避免重新运行 map-reduce 单词计数,只需将结果 Sqoop 到 Informix 和 DB2 中即可。您已经生成了关于 Twain 和 Cooper 的数据,现在,让我们把这些数据移动到一个数据库,如清单 11 所示。
清单 11. JDBC 驱动程序安装
#Sqoop needs access to the JDBC driver for every
# database that it will access
# please copy the driver for each database you plan to use for these exercises
# the MySQL database and driver are already installed in the virtual image
# but you still need to copy the driver to the sqoop/lib directory
#one time copy of jdbc driver to sqoop lib directory
$ sudo cp Informix_JDBC_Driver/lib/ifxjdbc*.jar /usr/lib/sqoop/lib/
$ sudo cp db2jdbc/db2jcc*.jar /usr/lib/sqoop/lib/
$ sudo cp /usr/lib/hive/lib/mysql-connector-java-5.1.15-bin.jar /usr/lib/sqoop/lib/
|
清单 12 至 15 所示的示例分别对应于每种数据库。请跳到您感兴趣的示例,包括 Informix、DB2 或 MySQL。对于掌握多种数据库语言的人,请享受执行每个示例的乐趣。如果这里没有包括您首选的数据库,让这些示例在其他地方工作也不会是一个巨大的挑战。
清单 12. Informix 用户:Sqoop 将单词计数的结果写入 Informix
# create a target table to put the data
# fire up dbaccess and use this sql
# create table wordcount ( word char(36) primary key, n int);
# now run the sqoop command
# this is best put in a shell script to help avoid typos...
$ sqoop export -D sqoop.export.records.per.statement=1 \
--fields-terminated-by '\t' --driver com.informix.jdbc.IfxDriver \
--connect \
"jdbc:informix-sqli://myhost:54321/stores_demo:informixserver=i7;user=me;password=mypw" \
--table wordcount --export-dir /user/cloudera/HF.out
|
清单 13. Informix 用户:Sqoop 将单词计数的结果写入 Informix
12/08/08 21:39:42 INFO manager.SqlManager: Using default fetchSize of 1000
12/08/08 21:39:42 INFO tool.CodeGenTool: Beginning code generation
12/08/08 21:39:43 INFO manager.SqlManager: Executing SQL statement: SELECT t.*
FROM wordcount AS t WHERE 1=0
12/08/08 21:39:43 INFO manager.SqlManager: Executing SQL statement: SELECT t.*
FROM wordcount AS t WHERE 1=0
12/08/08 21:39:43 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop
12/08/08 21:39:43 INFO orm.CompilationManager: Found hadoop core jar at:
/usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar
12/08/08 21:39:45 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-cloudera/compile/248b77c05740f863a15e0136accf32cf/wordcount.jar
12/08/08 21:39:45 INFO mapreduce.ExportJobBase: Beginning export of wordcount
12/08/08 21:39:45 INFO manager.SqlManager: Executing SQL statement: SELECT t.*
FROM wordcount AS t WHERE 1=0
12/08/08 21:39:46 INFO input.FileInputFormat: Total input paths to process : 1
12/08/08 21:39:46 INFO input.FileInputFormat: Total input paths to process : 1
12/08/08 21:39:46 INFO mapred.JobClient: Running job: job_201208081900_0012
12/08/08 21:39:47 INFO mapred.JobClient: map 0% reduce 0%
12/08/08 21:39:58 INFO mapred.JobClient: map 38% reduce 0%
12/08/08 21:40:00 INFO mapred.JobClient: map 64% reduce 0%
12/08/08 21:40:04 INFO mapred.JobClient: map 82% reduce 0%
12/08/08 21:40:07 INFO mapred.JobClient: map 98% reduce 0%
12/08/08 21:40:09 INFO mapred.JobClient: Task Id :
attempt_201208081900_0012_m_000000_0, Status : FAILED
java.io.IOException: java.sql.SQLException:
Encoding or code set not supported.
at ...SqlRecordWriter.close(AsyncSqlRecordWriter.java:187)
at ...$NewDirectOutputCollector.close(MapTask.java:540)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:649)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323)
at org.apache.hadoop.mapred.Child$4.run(Child.java:270)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at ....doAs(UserGroupInformation.java:1177)
at org.apache.hadoop.mapred.Child.main(Child.java:264)
Caused by: java.sql.SQLException: Encoding or code set not supported.
at com.informix.util.IfxErrMsg.getSQLException(IfxErrMsg.java:413)
at com.informix.jdbc.IfxChar.toIfx(IfxChar.java:135)
at com.informix.jdbc.IfxSqli.a(IfxSqli.java:1304)
at com.informix.jdbc.IfxSqli.d(IfxSqli.java:1605)
at com.informix.jdbc.IfxS
12/08/08 21:40:11 INFO mapred.JobClient: map 0% reduce 0%
12/08/08 21:40:15 INFO mapred.JobClient: Task Id :
attempt_201208081900_0012_m_000000_1, Status : FAILED
java.io.IOException: java.sql.SQLException:
Unique constraint (informix.u169_821) violated.
at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:223)
at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:49)
at .mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:531)
at .mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:82)
at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:40)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at .mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:189)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:647)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323)
at org.apache.hadoop.mapred.Child$4.run(Child.java:270)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.a
12/08/08 21:40:20 INFO mapred.JobClient:
Task Id : attempt_201208081900_0012_m_000000_2, Status : FAILED
java.sql.SQLException: Unique constraint (informix.u169_821) violated.
at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:223)
at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:49)
at .mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:531)
at .mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:82)
at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:40)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at .mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:189)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:647)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323)
at org.apache.hadoop.mapred.Child$4.run(Child.java:270)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.a
12/08/08 21:40:27 INFO mapred.JobClient: Job complete: job_201208081900_0012
12/08/08 21:40:27 INFO mapred.JobClient: Counters: 7
12/08/08 21:40:27 INFO mapred.JobClient: Job Counters
12/08/08 21:40:27 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=38479
12/08/08 21:40:27 INFO mapred.JobClient:
Total time spent by all reduces waiting after reserving slots (ms)=0
12/08/08 21:40:27 INFO mapred.JobClient:
Total time spent by all maps waiting after reserving slots (ms)=0
12/08/08 21:40:27 INFO mapred.JobClient: Launched map tasks=4
12/08/08 21:40:27 INFO mapred.JobClient: Data-local map tasks=4
12/08/08 21:40:27 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
12/08/08 21:40:27 INFO mapred.JobClient: Failed map tasks=1
12/08/08 21:40:27 INFO mapreduce.ExportJobBase:
Transferred 0 bytes in 41.5758 seconds (0 bytes/sec)
12/08/08 21:40:27 INFO mapreduce.ExportJobBase: Exported 0 records.
12/08/08 21:40:27 ERROR tool.ExportTool: Error during export: Export job failed!
# despite the errors above, rows are inserted into the wordcount table
# one row is missing
# the retry and duplicate key exception are most likely related, but
# troubleshooting will be saved for a later article
# check how we did
# nothing like a "here document" shell script
$ dbaccess stores_demo - <<eoj
> select count(*) from wordcount;
> eoj
Database selected.
(count(*))
13837
1 row(s) retrieved.
Database closed.
|
清单 14. DB2 用户:Sqoop 将单词计数的结果写入 DB2
# here is the db2 syntax
# create a destination table for db2
#
#db2 => connect to sample
#
# Database Connection Information
#
# Database server = DB2/LINUXX8664 10.1.0
# SQL authorization ID = DB2INST1
# Local database alias = SAMPLE
#
#db2 => create table wordcount ( word char(36) not null primary key , n int)
#DB20000I The SQL command completed successfully.
#
sqoop export -D sqoop.export.records.per.statement=1 \
--fields-terminated-by '\t' \
--driver com.ibm.db2.jcc.DB2Driver \
--connect "jdbc:db2://192.168.1.131:50001/sample" \
--username db2inst1 --password db2inst1 \
--table wordcount --export-dir /user/cloudera/HF.out
12/08/09 12:32:59 WARN tool.BaseSqoopTool: Setting your password on the
command-line is insecure. Consider using -P instead.
12/08/09 12:32:59 INFO manager.SqlManager: Using default fetchSize of 1000
12/08/09 12:32:59 INFO tool.CodeGenTool: Beginning code generation
12/08/09 12:32:59 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM wordcount AS t WHERE 1=0
12/08/09 12:32:59 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM wordcount AS t WHERE 1=0
12/08/09 12:32:59 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop
12/08/09 12:32:59 INFO orm.CompilationManager: Found hadoop core jar
at: /usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar
12/08/09 12:33:00 INFO orm.CompilationManager: Writing jar
file: /tmp/sqoop-cloudera/compile/5532984df6e28e5a45884a21bab245ba/wordcount.jar
12/08/09 12:33:00 INFO mapreduce.ExportJobBase: Beginning export of wordcount
12/08/09 12:33:01 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM wordcount AS t WHERE 1=0
12/08/09 12:33:02 INFO input.FileInputFormat: Total input paths to process : 1
12/08/09 12:33:02 INFO input.FileInputFormat: Total input paths to process : 1
12/08/09 12:33:02 INFO mapred.JobClient: Running job: job_201208091208_0002
12/08/09 12:33:03 INFO mapred.JobClient: map 0% reduce 0%
12/08/09 12:33:14 INFO mapred.JobClient: map 24% reduce 0%
12/08/09 12:33:17 INFO mapred.JobClient: map 44% reduce 0%
12/08/09 12:33:20 INFO mapred.JobClient: map 67% reduce 0%
12/08/09 12:33:23 INFO mapred.JobClient: map 86% reduce 0%
12/08/09 12:33:24 INFO mapred.JobClient: map 100% reduce 0%
12/08/09 12:33:25 INFO mapred.JobClient: Job complete: job_201208091208_0002
12/08/09 12:33:25 INFO mapred.JobClient: Counters: 16
12/08/09 12:33:25 INFO mapred.JobClient: Job Counters
12/08/09 12:33:25 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=21648
12/08/09 12:33:25 INFO mapred.JobClient: Total time spent by all
reduces waiting after reserving slots (ms)=0
12/08/09 12:33:25 INFO mapred.JobClient: Total time spent by all
maps waiting after reserving slots (ms)=0
12/08/09 12:33:25 INFO mapred.JobClient: Launched map tasks=1
12/08/09 12:33:25 INFO mapred.JobClient: Data-local map tasks=1
12/08/09 12:33:25 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
12/08/09 12:33:25 INFO mapred.JobClient: FileSystemCounters
12/08/09 12:33:25 INFO mapred.JobClient: HDFS_BYTES_READ=138350
12/08/09 12:33:25 INFO mapred.JobClient: FILE_BYTES_WRITTEN=69425
12/08/09 12:33:25 INFO mapred.JobClient: Map-Reduce Framework
12/08/09 12:33:25 INFO mapred.JobClient: Map input records=13838
12/08/09 12:33:25 INFO mapred.JobClient: Physical memory (bytes) snapshot=105148416
12/08/09 12:33:25 INFO mapred.JobClient: Spilled Records=0
12/08/09 12:33:25 INFO mapred.JobClient: CPU time spent (ms)=9250
12/08/09 12:33:25 INFO mapred.JobClient: Total committed heap usage (bytes)=42008576
12/08/09 12:33:25 INFO mapred.JobClient: Virtual memory (bytes) snapshot=596447232
12/08/09 12:33:25 INFO mapred.JobClient: Map output records=13838
12/08/09 12:33:25 INFO mapred.JobClient: SPLIT_RAW_BYTES=126
12/08/09 12:33:25 INFO mapreduce.ExportJobBase: Transferred 135.1074 KB
in 24.4977 seconds (5.5151 KB/sec)
12/08/09 12:33:25 INFO mapreduce.ExportJobBase: Exported 13838 records.
# check on the results...
#
#db2 => select count(*) from wordcount
#
#1
#-----------
# 13838
#
# 1 record(s) selected.
#
#
|
清单 15. MySQL 用户:Sqoop 将单词计数的结果写入 MySQL
# if you don't have Informix or DB2 you can still do this example
# mysql - it is already installed in the VM, here is how to access
# one time copy of the JDBC driver
sudo cp /usr/lib/hive/lib/mysql-connector-java-5.1.15-bin.jar /usr/lib/sqoop/lib/
# now create the database and table
$ mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 45
Server version: 5.0.95 Source distribution
Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create database mydemo;
Query OK, 1 row affected (0.00 sec)
mysql> use mydemo
Database changed
mysql> create table wordcount ( word char(36) not null primary key, n int);
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
# now export
$ sqoop export --connect jdbc:mysql://localhost/mydemo \
--table wordcount --export-dir /user/cloudera/HF.out \
--fields-terminated-by '\t' --username root
|
使用 Sqoop 将数据从 Informix 和 DB2 导入到 HDFS
使用 Sqoop 也可以实现将数据插入 Hadoop HDFS。通过导入参数可以控制此双向功能。
这两种产品自带的样本数据库有一些您可以为此目的使用的简单数据集。清单 16 显示了 Sqoop 每台服务器的语法和结果。
对于 MySQL 用户,请调整以下 Informix 或 DB2 示例中的语法。
清单 16. Sqoop 从 Informix 样本数据库导入到 HDFS
$ sqoop import --driver com.informix.jdbc.IfxDriver \
--connect \
"jdbc:informix-sqli://192.168.1.143:54321/stores_demo:informixserver=ifx117" \
--table orders \
--username informix --password useyours
12/08/09 14:39:18 WARN tool.BaseSqoopTool: Setting your password on the command-line
is insecure. Consider using -P instead.
12/08/09 14:39:18 INFO manager.SqlManager: Using default fetchSize of 1000
12/08/09 14:39:18 INFO tool.CodeGenTool: Beginning code generation
12/08/09 14:39:19 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM orders AS t WHERE 1=0
12/08/09 14:39:19 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM orders AS t WHERE 1=0
12/08/09 14:39:19 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop
12/08/09 14:39:19 INFO orm.CompilationManager: Found hadoop core jar
at: /usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar
12/08/09 14:39:21 INFO orm.CompilationManager: Writing jar
file: /tmp/sqoop-cloudera/compile/0b59eec7007d3cff1fc0ae446ced3637/orders.jar
12/08/09 14:39:21 INFO mapreduce.ImportJobBase: Beginning import of orders
12/08/09 14:39:21 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM orders AS t WHERE 1=0
12/08/09 14:39:22 INFO db.DataDrivenDBInputFormat: BoundingValsQuery:
SELECT MIN(order_num), MAX(order_num) FROM orders
12/08/09 14:39:22 INFO mapred.JobClient: Running job: job_201208091208_0003
12/08/09 14:39:23 INFO mapred.JobClient: map 0% reduce 0%
12/08/09 14:39:31 INFO mapred.JobClient: map 25% reduce 0%
12/08/09 14:39:32 INFO mapred.JobClient: map 50% reduce 0%
12/08/09 14:39:36 INFO mapred.JobClient: map 100% reduce 0%
12/08/09 14:39:37 INFO mapred.JobClient: Job complete: job_201208091208_0003
12/08/09 14:39:37 INFO mapred.JobClient: Counters: 16
12/08/09 14:39:37 INFO mapred.JobClient: Job Counters
12/08/09 14:39:37 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=22529
12/08/09 14:39:37 INFO mapred.JobClient: Total time spent by all reduces
waiting after reserving slots (ms)=0
12/08/09 14:39:37 INFO mapred.JobClient: Total time spent by all maps
waiting after reserving slots (ms)=0
12/08/09 14:39:37 INFO mapred.JobClient: Launched map tasks=4
12/08/09 14:39:37 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
12/08/09 14:39:37 INFO mapred.JobClient: FileSystemCounters
12/08/09 14:39:37 INFO mapred.JobClient: HDFS_BYTES_READ=457
12/08/09 14:39:37 INFO mapred.JobClient: FILE_BYTES_WRITTEN=278928
12/08/09 14:39:37 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=2368
12/08/09 14:39:37 INFO mapred.JobClient: Map-Reduce Framework
12/08/09 14:39:37 INFO mapred.JobClient: Map input records=23
12/08/09 14:39:37 INFO mapred.JobClient: Physical memory (bytes) snapshot=291364864
12/08/09 14:39:37 INFO mapred.JobClient: Spilled Records=0
12/08/09 14:39:37 INFO mapred.JobClient: CPU time spent (ms)=1610
12/08/09 14:39:37 INFO mapred.JobClient: Total committed heap usage (bytes)=168034304
12/08/09 14:39:37 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2074587136
12/08/09 14:39:37 INFO mapred.JobClient: Map output records=23
12/08/09 14:39:37 INFO mapred.JobClient: SPLIT_RAW_BYTES=457
12/08/09 14:39:37 INFO mapreduce.ImportJobBase: Transferred 2.3125 KB in 16.7045
seconds (141.7585 bytes/sec)
12/08/09 14:39:37 INFO mapreduce.ImportJobBase: Retrieved 23 records.
# now look at the results
$ hls
Found 4 items
-rw-r--r-- 1 cloudera supergroup 459386 2012-08-08 19:34 /user/cloudera/DS.txt.gz
drwxr-xr-x - cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out
-rw-r--r-- 1 cloudera supergroup 597587 2012-08-08 19:35 /user/cloudera/HF.txt
drwxr-xr-x - cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders
$ hls orders
Found 6 items
-rw-r--r-- 1 cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders/_SUCCESS
drwxr-xr-x - cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders/_logs
-rw-r--r-- 1 cloudera ...roup 630 2012-08-09 14:39 /user/cloudera/orders/part-m-00000
-rw-r--r-- 1 cloudera supergroup
564 2012-08-09 14:39 /user/cloudera/orders/part-m-00001
-rw-r--r-- 1 cloudera supergroup
527 2012-08-09 14:39 /user/cloudera/orders/part-m-00002
-rw-r--r-- 1 cloudera supergroup
647 2012-08-09 14:39 /user/cloudera/orders/part-m-00003
# wow there are four files part-m-0000x
# look inside one
# some of the lines are edited to fit on the screen
$ hcat /user/cloudera/orders/part-m-00002
1013,2008-06-22,104,express ,n,B77930 ,2008-07-10,60.80,12.20,2008-07-31
1014,2008-06-25,106,ring bell, ,n,8052 ,2008-07-03,40.60,12.30,2008-07-10
1015,2008-06-27,110, ,n,MA003 ,2008-07-16,20.60,6.30,2008-08-31
1016,2008-06-29,119, St. ,n,PC6782 ,2008-07-12,35.00,11.80,null
1017,2008-07-09,120,use ,n,DM354331 ,2008-07-13,60.00,18.00,null
|
为什么有四个不同的文件,而且每个文件只包含一部分数据?Sqoop 是一个高度并行化的实用程序。如果一个运行 Sqoop 的具有 4000 个节点的集群从数据库全力执行导入操作,那么 4000 个数据库连接看起来非常像针对数据库的拒绝服务攻击。Sqoop 的默认连接限制是 4 个 JDBC 连接。每个连接在 HDFS 中生成一个数据文件。因此会有四个文件。不用担心,您会看到 Hadoop 如何毫无难度地跨这些文件进行工作。
下一步是导入一个 DB2 表。如清单 17 所示,通过指定 -m 1 选项,就可以导入没有主键的表,其结果也是一个单一文件。
清单 17. Sqoop 从 DB2 样本数据库导入到 HDFS
# very much the same as above, just a different jdbc connection
# and different table name
sqoop import --driver com.ibm.db2.jcc.DB2Driver \
--connect "jdbc:db2://192.168.1.131:50001/sample" \
--table staff --username db2inst1 \
--password db2inst1 -m 1
# Here is another example
# in this case set the sqoop default schema to be different from
# the user login schema
sqoop import --driver com.ibm.db2.jcc.DB2Driver \
--connect "jdbc:db2://192.168.1.3:50001/sample:currentSchema=DB2INST1;" \
--table helloworld \
--target-dir "/user/cloudera/sqoopin2" \
--username marty \
-P -m 1
# the the schema name is CASE SENSITIVE
# the -P option prompts for a password that will not be visible in
# a "ps" listing
|
使用 Hive:联接 Informix 和 DB2 数据
将数据从 Informix 联接到 DB2 是一个有趣的用例。若只是两个简单的表格,并不会非常令人兴奋,但对于多个 TB 或 PB 的数据则是一个巨大的胜利。
联接不同的数据源有两种基本方法:让数据静止,并使用联邦技术与将数据移动到单一存储,以执行联接。Hadoop 的经济性和性能使得将数据移入 HDFS 和使用 MapReduce 执行繁重的工作成为一个必然的选择。如果试图使用联邦技术联接静止状态的数据,网络带宽的限制会造成一个基本障碍。有关联邦的更多信息,请参阅 参考资料 部分。
Hive 提供了一个在集群上运行的 SQL 子集。Hive 不提供事务语义,也不是 Informix 或 DB2 的替代品。如果您有一些繁重的工作(如表联接),那么即使您的一些表规模较小,但需要执行讨厌的 Cartesian 产品,Hadoop 也是首选的工具。
要使用 Hive 查询语言,需要称为 Hiveql 表元数据的 SQL 子集。您可以针对 HDFS 中的现有文件定义元数据。Sqoop 利用 create-hive-table 选项提供了一个便捷的快捷方式。
MySQL 用户可随时调整清单 18 中的示例。将 MySQL 或任何其他关系数据库表联接到大型电子表格,这将是一个有趣的练习。
清单 18. 将 informix.customer 表联接到 db2.staff 表
# import the customer table into Hive
$ sqoop import --driver com.informix.jdbc.IfxDriver \
--connect \
"jdbc:informix-sqli://myhost:54321/stores_demo:informixserver=ifx;user=me;password=you" \
--table customer
# now tell hive where to find the informix data
# to get to the hive command prompt just type in hive
$ hive
Hive history file=/tmp/cloudera/yada_yada_log123.txt
hive>
# here is the hiveql you need to create the tables
# using a file is easier than typing
create external table customer (
cn int,
fname string,
lname string,
company string,
addr1 string,
addr2 string,
city string,
state string,
zip string,
phone string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/cloudera/customer'
;
# we already imported the db2 staff table above
# now tell hive where to find the db2 data
create external table staff (
id int,
name string,
dept string,
job string,
years string,
salary float,
comm float)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/cloudera/staff'
;
# you can put the commands in a file
# and execute them as follows:
$ hive -f hivestaff
Hive history file=/tmp/cloudera/hive_job_log_cloudera_201208101502_2140728119.txt
OK
Time taken: 3.247 seconds
OK
10 Sanders 20 Mgr 7 98357.5 NULL
20 Pernal 20 Sales 8 78171.25 612.45
30 Marenghi 38 Mgr 5 77506.75 NULL
40 O'Brien 38 Sales 6 78006.0 846.55
50 Hanes 15 Mgr 10 80
... lines deleted
# now for the join we've all been waiting for :-)
# this is a simple case, Hadoop can scale well into the petabyte range!
$ hive
Hive history file=/tmp/cloudera/hive_job_log_cloudera_201208101548_497937669.txt
hive> select customer.cn, staff.name,
> customer.addr1, customer.city, customer.phone
> from staff join customer
> on ( staff.id = customer.cn );
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=number
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=number
In order to set a constant number of reducers:
set mapred.reduce.tasks=number
Starting Job = job_201208101425_0005,
Tracking URL = http://0.0.0.0:50030/jobdetails.jsp?jobid=job_201208101425_0005
Kill Command = /usr/lib/hadoop/bin/hadoop
job -Dmapred.job.tracker=0.0.0.0:8021 -kill job_201208101425_0005
2012-08-10 15:49:07,538 Stage-1 map = 0%, reduce = 0%
2012-08-10 15:49:11,569 Stage-1 map = 50%, reduce = 0%
2012-08-10 15:49:12,574 Stage-1 map = 100%, reduce = 0%
2012-08-10 15:49:19,686 Stage-1 map = 100%, reduce = 33%
2012-08-10 15:49:20,692 Stage-1 map = 100%, reduce = 100%
Ended Job = job_201208101425_0005
OK
110 Ngan 520 Topaz Way Redwood City 415-743-3611
120 Naughton 6627 N. 17th Way Phoenix 602-265-8754
Time taken: 22.764 seconds
|
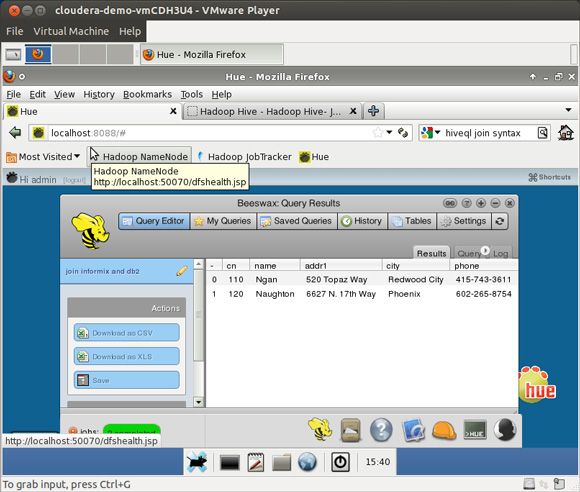
若您使用 Hue 实现图形化浏览器界面,它会更漂亮,如图 9、图 10 和图 11 所示。
图 9. CDH4 中的 Hue Beeswax GUI for Hive,查看 Hiveql 查询
图 10. Hue Beeswax GUI for Hive,查看 Hiveql 查询

图 11. Hue Beeswax 图形化浏览器,查看 Informix-DB2 联接结果
使用 Pig:联接 Informix 和 DB2 数据
Pig 是一种过程语言。就像 Hive 一样,它在幕后生成 MapReduce 代码。随着越来越多的项目可用,Hadoop 的易用性将继续提高。虽然我们中的一些人真的很喜欢命令行,但有几个图形用户界面与 Hadoop 配合得很好。
清单 19 显示的 Pig 代码用于联接前面示例中的 customer 表和 staff 表。
清单 19. 将 Informix 表联接到 DB2 表的 Pig 示例
$ pig
grunt> staffdb2 = load 'staff' using PigStorage(',')
>> as ( id, name, dept, job, years, salary, comm );
grunt> custifx2 = load 'customer' using PigStorage(',') as
>> (cn, fname, lname, company, addr1, addr2, city, state, zip, phone)
>> ;
grunt> joined = join custifx2 by cn, staffdb2 by id;
# to make pig generate a result set use the dump command
# no work has happened up till now
grunt> dump joined;
2012-08-11 21:24:51,848 [main] INFO org.apache.pig.tools.pigstats.ScriptState
- Pig features used in the script: HASH_JOIN
2012-08-11 21:24:51,848 [main] INFO org.apache.pig.backend.hadoop.executionengine
.HExecutionEngine - pig.usenewlogicalplan is set to true.
New logical plan will be used.
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
0.20.2-cdh3u4 0.8.1-cdh3u4 cloudera 2012-08-11 21:24:51
2012-08-11 21:25:19 HASH_JOIN
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime
MaxReduceTime MinReduceTime AvgReduceTime Alias Feature Outputs
job_201208111415_0006 2 1 8 8 8 10 10 10
custifx,joined,staffdb2 HASH_JOIN hdfs://0.0.0.0/tmp/temp1785920264/tmp-388629360,
Input(s):
Successfully read 35 records from: "hdfs://0.0.0.0/user/cloudera/staff"
Successfully read 28 records from: "hdfs://0.0.0.0/user/cloudera/customer"
Output(s):
Successfully stored 2 records (377 bytes) in:
"hdfs://0.0.0.0/tmp/temp1785920264/tmp-388629360"
Counters:
Total records written : 2
Total bytes written : 377
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_201208111415_0006
2012-08-11 21:25:19,145 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
2012-08-11 21:25:19,149 [main] INFO org.apache.hadoop.mapreduce.lib.
input.FileInputFormat - Total input paths to process : 1
2012-08-11 21:25:19,149 [main] INFO org.apache.pig.backend.hadoop.
executionengine.util.MapRedUtil - Total input paths to process : 1
(110,Roy ,Jaeger ,AA Athletics ,520 Topaz Way
,null,Redwood City ,CA,94062,415-743-3611 ,110,Ngan,15,Clerk,5,42508.20,206.60)
(120,Fred ,Jewell ,Century Pro Shop ,6627 N. 17th Way
,null,Phoenix ,AZ,85016,602-265-8754
,120,Naughton,38,Clerk,null,42954.75,180.00)
|
我如何选择 Java、Hive 还是 Pig?
您有多种选择来进行 Hadoop 编程,而且最好先查看用例,选择合适的工具来完成工作。您可以不局限于处理关系型数据,但本文的重点是 Informix、DB2 和 Hadoop 的良好配合。编写几百行 Java 来实施关系型散列联接完全是浪费时间,因为 Hadoop 的 MapReduce 算法已经可用。您如何选择?这是一个个人喜好的问题。有些人喜欢 SQL 中的编码集操作。有些人喜欢过程代码。您应该选择让您效率最高的语言。如果您有多个关系数据库系统,并希望以低廉的价格通过强大的性能整合所有数据,那么 Hadoop、MapReduce、Hive 和 Pig 随时可以提供帮助。
不要删除您的数据:将分区从 Informix 滚动到 HDFS
大多数现代关系型数据库都可以对数据进行分区。一个常见的用例是按时间段进行分区。固定窗口的数据被存储,例如,滚动 18 个月的间隔,在此之后的数据被归档。分离分区的功能非常强大。但分区被分离后,该怎么处理数据呢?
旧数据的磁带归档是摒弃旧数据的一种非常昂贵的方式。一旦移动到可访问性较低的介质,除非有法定的审计要求,否则数据将极少被访问。Hadoop 提供了一种更好的替代方案。
将归档数据从旧分区移动到 Hadoop,这提供了高性能的访问,而且比起将数据保存在原来的事务或数据集市/数据仓库系统中的成本要低得多。数据太旧会失去事务性价值,但对于组织的长期分析仍然非常有价值。之前的 Sqoop 示例提供了如何将这些数据从关系分区移动到 HDFS 的基本知识。
Fuse - 通过 NFS 访问 HDFS 文件
可以通过 NFS 访问 HDFS 中的 Informix/DB2/平面文件数据,如清单 20 所示。这提供了命令行操作,但无需使用 “hadoop fs -yadayada” 界面。从技术用例的角度来看,NFS 在大数据环境受到严重限制,但所包含的这些示例是面向开发者的,并且数据不是太大。
清单 20. 设置 Fuse - 通过 NFS 访问您的 HDFS 数据
# this is for CDH4, the CDH3 image doesn't have fuse installed...
$ mkdir fusemnt
$ sudo hadoop-fuse-dfs dfs://localhost:8020 fusemnt/
INFO fuse_options.c:162 Adding FUSE arg fusemnt/
$ ls fusemnt
tmp user var
$ ls fusemnt/user
cloudera hive
$ ls fusemnt/user/cloudera
customer DS.txt.gz HF.out HF.txt orders staff
$ cat fusemnt/user/cloudera/orders/part-m-00001
1007,2008-05-31,117,null,n,278693 ,2008-06-05,125.90,25.20,null
1008,2008-06-07,110,closed Monday
,y,LZ230 ,2008-07-06,45.60,13.80,2008-07-21
1009,2008-06-14,111,next door to grocery
,n,4745 ,2008-06-21,20.40,10.00,2008-08-21
1010,2008-06-17,115,deliver 776 King St. if no answer
,n,429Q ,2008-06-29,40.60,12.30,2008-08-22
1011,2008-06-18,104,express
,n,B77897 ,2008-07-03,10.40,5.00,2008-08-29
1012,2008-06-18,117,null,n,278701 ,2008-06-29,70.80,14.20,null
|
Flume - 创建一个加载就绪的文件
Flume next generation(也称为 flume-ng)是一个高速并行加载程序。数据库具有高速加载程序,那么,它们如何良好配合呢?Flume-ng 的关系型用例是在本地或远程创建一个加载就绪的文件,那么关系服务器就可以使用其高速加载程序。是的,此功能与 Sqoop 重叠,但在清单 21 中所示的脚本是根据客户专门针对这种风格的数据库加载的要求而创建的。
清单 21. 将 HDFS 数据导出到一个平面文件,以供数据库进行加载
$ sudo yum install flume-ng
$ cat flumeconf/hdfs2dbloadfile.conf
#
# started with example from flume-ng documentation
# modified to do hdfs source to file sink
#
# Define a memory channel called ch1 on agent1
agent1.channels.ch1.type = memory
# Define an exec source called exec-source1 on agent1 and tell it
# to bind to 0.0.0.0:31313. Connect it to channel ch1.
agent1.sources.exec-source1.channels = ch1
agent1.sources.exec-source1.type = exec
agent1.sources.exec-source1.command =hadoop fs -cat /user/cloudera/orders/part-m-00001
# this also works for all the files in the hdfs directory
# agent1.sources.exec-source1.command =hadoop fs
# -cat /user/cloudera/tsortin/*
agent1.sources.exec-source1.bind = 0.0.0.0
agent1.sources.exec-source1.port = 31313
# Define a logger sink that simply file rolls
# and connect it to the other end of the same channel.
agent1.sinks.fileroll-sink1.channel = ch1
agent1.sinks.fileroll-sink1.type = FILE_ROLL
agent1.sinks.fileroll-sink1.sink.directory =/tmp
# Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = ch1
agent1.sources = exec-source1
agent1.sinks = fileroll-sink1
# now time to run the script
$ flume-ng agent --conf ./flumeconf/ -f ./flumeconf/hdfs2dbloadfile.conf -n
agent1
# here is the output file
# don't forget to stop flume - it will keep polling by default and generate
# more files
$ cat /tmp/1344780561160-1
1007,2008-05-31,117,null,n,278693 ,2008-06-05,125.90,25.20,null
1008,2008-06-07,110,closed Monday ,y,LZ230 ,2008-07-06,45.60,13.80,2008-07-21
1009,2008-06-14,111,next door to ,n,4745 ,2008-06-21,20.40,10.00,2008-08-21
1010,2008-06-17,115,deliver 776 King St. if no answer ,n,429Q
,2008-06-29,40.60,12.30,2008-08-22
1011,2008-06-18,104,express ,n,B77897 ,2008-07-03,10.40,5.00,2008-08-29
1012,2008-06-18,117,null,n,278701 ,2008-06-29,70.80,14.20,null
# jump over to dbaccess and use the greatest
# data loader in informix: the external table
# external tables were actually developed for
# informix XPS back in the 1996 timeframe
# and are now available in may servers
#
drop table eorders;
create external table eorders
(on char(10),
mydate char(18),
foo char(18),
bar char(18),
f4 char(18),
f5 char(18),
f6 char(18),
f7 char(18),
f8 char(18),
f9 char(18)
)
using (datafiles ("disk:/tmp/myfoo" ) , delimiter ",");
select * from eorders;
|
Oozie - 为多个作业添加工作流
Oozie 将多个 Hadoop 作业链接在一起。有一组很好的示例,其中包含清单 22 所示的代码集里使用的 oozie。
清单 22. 使用 oozie 进行作业控制
# This sample is for CDH3
# untar the examples
# CDH4
$ tar -zxvf /usr/share/doc/oozie-3.1.3+154/oozie-examples.tar.gz
# CDH3
$ tar -zxvf /usr/share/doc/oozie-2.3.2+27.19/oozie-examples.tar.gz
# cd to the directory where the examples live
# you MUST put these jobs into the hdfs store to run them
$ hadoop fs -put examples examples
# start up the oozie server - you need to be the oozie user
# since the oozie user is a non-login id use the following su trick
# CDH4
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-sys.sh start
# CDH3
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-start.sh
# checkthe status
oozie admin -oozie http://localhost:11000/oozie -status
System mode: NORMAL
# some jar housekeeping so oozie can find what it needs
$ cp /usr/lib/sqoop/sqoop-1.3.0-cdh3u4.jar examples/apps/sqoop/lib/
$ cp /home/cloudera/Informix_JDBC_Driver/lib/ifxjdbc.jar examples/apps/sqoop/lib/
$ cp /home/cloudera/Informix_JDBC_Driver/lib/ifxjdbcx.jar examples/apps/sqoop/lib/
# edit the workflow.xml file to use your relational database:
#################################
<command> import
--driver com.informix.jdbc.IfxDriver
--connect jdbc:informix-sqli://192.168.1.143:54321/stores_demo:informixserver=ifx117
--table orders --username informix --password useyours
--target-dir /user/${wf:user()}/${examplesRoot}/output-data/sqoop --verbose<command>
#################################
# from the directory where you un-tarred the examples file do the following:
$ hrmr examples;hput examples examples
# now you can run your sqoop job by submitting it to oozie
$ oozie job -oozie http://localhost:11000/oozie -config \
examples/apps/sqoop/job.properties -run
job: 0000000-120812115858174-oozie-oozi-W
# get the job status from the oozie server
$ oozie job -oozie http://localhost:11000/oozie -info 0000000-120812115858174-oozie-oozi-W
Job ID : 0000000-120812115858174-oozie-oozi-W
-----------------------------------------------------------------------
Workflow Name : sqoop-wf
App Path : hdfs://localhost:8020/user/cloudera/examples/apps/sqoop/workflow.xml
Status : SUCCEEDED
Run : 0
User : cloudera
Group : users
Created : 2012-08-12 16:05
Started : 2012-08-12 16:05
Last Modified : 2012-08-12 16:05
Ended : 2012-08-12 16:05
Actions
----------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
---------------------------------------------------------------------
0000000-120812115858174-oozie-oozi-W@sqoop-node OK
job_201208120930_0005 SUCCEEDED -
--------------------------------------------------------------------
# how to kill a job may come in useful at some point
oozie job -oozie http://localhost:11000/oozie -kill
0000013-120812115858174-oozie-oozi-W
# job output will be in the file tree
$ hcat /user/cloudera/examples/output-data/sqoop/part-m-00003
1018,2008-07-10,121,SW corner of Biltmore Mall ,n,S22942
,2008-07-13,70.50,20.00,2008-08-06
1019,2008-07-11,122,closed till noon Mondays ,n,Z55709
,2008-07-16,90.00,23.00,2008-08-06
1020,2008-07-11,123,express ,n,W2286
,2008-07-16,14.00,8.50,2008-09-20
1021,2008-07-23,124,ask for Elaine ,n,C3288
,2008-07-25,40.00,12.00,2008-08-22
1022,2008-07-24,126,express ,n,W9925
,2008-07-30,15.00,13.00,2008-09-02
1023,2008-07-24,127,no deliveries after 3 p.m. ,n,KF2961
,2008-07-30,60.00,18.00,2008-08-22
# if you run into this error there is a good chance that your
# database lock file is owned by root
$ oozie job -oozie http://localhost:11000/oozie -config \
examples/apps/sqoop/job.properties -run
Error: E0607 : E0607: Other error in operation [<openjpa-1.2.1-r752877:753278
fatal store error> org.apache.openjpa.persistence.RollbackException:
The transaction has been rolled back. See the nested exceptions for
details on the errors that occurred.], {1}
# fix this as follows
$ sudo chown oozie:oozie /var/lib/oozie/oozie-db/db.lck
# and restart the oozie server
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-stop.sh
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-start.sh
|
HBase:一个高性能的键值存储
HBase 是一个高性能的键值存储。如果您的用例需要可扩展性,并且只需要相当于能自动提交事务的数据库,那么 HBase 很可能就是适合的技术。HBase 不是一个数据库。这个名称起得不好,因为对于某些人来说,术语 base 意味着数据库。它为高性能键值存储做了出色的工作。HBase、Informix、DB2 和其他关系数据库的功能之间有一些重叠。对于 ACID 事务、完整的 SQL 合规性和多个索引来说,传统的关系型数据库是显而易见的选择。
最后这个代码练习提供对 HBase 的基本了解。这个练习设计简单,并且不代表 HBase 的功能范围。请用该示例来了解 HBase 的一些基本功能。如果您打算在您的特定用例中实施或拒绝 HBase,那么由 Lars George 编写的 “HBase, The Definitive Guide” 是必读书籍之一。
如清单 23 和清单 24 所示,最后这个示例使用 HBase 提供的 REST 接口将键值插入 HBase 表。测试工具是基于旋度的。
清单 23. 创建一个 HBase 表并插入一行
# enter the command line shell for hbase
$ hbase shell
HBase Shell; enter 'help<RETURN> for list of supported commands.
Type "exit<RETURN> to leave the HBase Shell
Version 0.90.6-cdh3u4, r, Mon May 7 13:14:00 PDT 2012
# create a table with a single column family
hbase(main):001:0> create 'mytable', 'mycolfamily'
# if you get errors from hbase you need to fix the
# network config
# here is a sample of the error:
ERROR: org.apache.hadoop.hbase.ZooKeeperConnectionException: HBase
is able to connect to ZooKeeper but the connection closes immediately.
This could be a sign that the server has too many connections
(30 is the default). Consider inspecting your ZK server logs for
that error and then make sure you are reusing HBaseConfiguration
as often as you can. See HTable's javadoc for more information.
# fix networking:
# add the eth0 interface to /etc/hosts with a hostname
$ sudo su -
# ifconfig | grep addr
eth0 Link encap:Ethernet HWaddr 00:0C:29:8C:C7:70
inet addr:192.168.1.134 Bcast:192.168.1.255 Mask:255.255.255.0
Interrupt:177 Base address:0x1400
inet addr:127.0.0.1 Mask:255.0.0.0
[root@myhost ~]# hostname myhost
[root@myhost ~]# echo "192.168.1.134 myhost" >gt; /etc/hosts
[root@myhost ~]# cd /etc/init.d
# now that the host and address are defined restart Hadoop
[root@myhost init.d]# for i in hadoop*
> do
> ./$i restart
> done
# now try table create again:
$ hbase shell
HBase Shell; enter 'help<RETURN> for list of supported commands.
Type "exit<RETURN> to leave the HBase Shell
Version 0.90.6-cdh3u4, r, Mon May 7 13:14:00 PDT 2012
hbase(main):001:0> create 'mytable' , 'mycolfamily'
0 row(s) in 1.0920 seconds
hbase(main):002:0>
# insert a row into the table you created
# use some simple telephone call log data
# Notice that mycolfamily can have multiple cells
# this is very troubling for DBAs at first, but
# you do get used to it
hbase(main):001:0> put 'mytable', 'key123', 'mycolfamily:number','6175551212'
0 row(s) in 0.5180 seconds
hbase(main):002:0> put 'mytable', 'key123', 'mycolfamily:duration','25'
# now describe and then scan the table
hbase(main):005:0> describe 'mytable'
DESCRIPTION ENABLED
{NAME => 'mytable', FAMILIES => [{NAME => 'mycolfam true
ily', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '
0', COMPRESSION => 'NONE', VERSIONS => '3', TTL =>
'2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'f
alse', BLOCKCACHE => 'true'}]}
1 row(s) in 0.2250 seconds
# notice that timestamps are included
hbase(main):007:0> scan 'mytable'
ROW COLUMN+CELL
key123 column=mycolfamily:duration,
timestamp=1346868499125, value=25
key123 column=mycolfamily:number,
timestamp=1346868540850, value=6175551212
1 row(s) in 0.0250 seconds
|
清单 24. 使用 HBase REST 接口
# HBase includes a REST server
$ hbase rest start -p 9393 &
# you get a bunch of messages....
# get the status of the HBase server
$ curl http://localhost:9393/status/cluster
# lots of output...
# many lines deleted...
mytable,,1346866763530.a00f443084f21c0eea4a075bbfdfc292.
stores=1
storefiless=0
storefileSizeMB=0
memstoreSizeMB=0
storefileIndexSizeMB=0
# now scan the contents of mytable
$ curl http://localhost:9393/mytable/*
# lines deleted
12/09/05 15:08:49 DEBUG client.HTable$ClientScanner:
Finished with scanning at REGION =>
# lines deleted
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<CellSet><Row key="a2V5MTIz">
<Cell timestamp="1346868499125" column="bXljb2xmYW1pbHk6ZHVyYXRpb24=">MjU=</Cell>
<Cell timestamp="1346868540850" column="bXljb2xmYW1pbHk6bnVtYmVy">NjE3NTU1MTIxMg==</Cell>
<Cell timestamp="1346868425844" column="bXljb2xmYW1pbHk6bnVtYmVy">NjE3NTU1MTIxMg==</Cell>
</Row></CellSet>
# the values from the REST interface are base64 encoded
$ echo a2V5MTIz | base64 -d
key123
$ echo bXljb2xmYW1pbHk6bnVtYmVy | base64 -d
mycolfamily:number
# The table scan above gives the schema needed to insert into the HBase table
$ echo RESTinsertedKey | base64
UkVTVGluc2VydGVkS2V5Cg==
$ echo 7815551212 | base64
NzgxNTU1MTIxMgo=
# add a table entry with a key value of "RESTinsertedKey" and
# a phone number of "7815551212"
# note - curl is all on one line
$ curl -H "Content-Type: text/xml" -d '<CellSet>
<Row key="UkVTVGluc2VydGVkS2V5Cg==">
<Cell column="bXljb2xmYW1pbHk6bnVtYmVy">NzgxNTU1MTIxMgo=<Cell>
<Row><CellSet> http://192.168.1.134:9393/mytable/dummykey
12/09/05 15:52:34 DEBUG rest.RowResource: POST http://192.168.1.134:9393/mytable/dummykey
12/09/05 15:52:34 DEBUG rest.RowResource: PUT row=RESTinsertedKey\x0A,
families={(family=mycolfamily,
keyvalues=(RESTinsertedKey\x0A/mycolfamily:number/9223372036854775807/Put/vlen=11)}
# trust, but verify
hbase(main):002:0> scan 'mytable'
ROW COLUMN+CELL
RESTinsertedKey\x0A column=mycolfamily:number,timestamp=1346874754883,value=7815551212\x0A
key123 column=mycolfamily:duration, timestamp=1346868499125, value=25
key123 column=mycolfamily:number, timestamp=1346868540850, value=6175551212
2 row(s) in 0.5610 seconds
# notice the \x0A at the end of the key and value
# this is the newline generated by the "echo" command
# lets fix that
$ printf 8885551212 | base64
ODg4NTU1MTIxMg==
$ printf mykey | base64
bXlrZXk=
# note - curl statement is all on one line!
curl -H "Content-Type: text/xml" -d '<CellSet><Row key="bXlrZXk=">
<Cell column="bXljb2xmYW1pbHk6bnVtYmVy">ODg4NTU1MTIxMg==<Cell>
<Row><CellSet>
http://192.168.1.134:9393/mytable/dummykey
# trust but verify
hbase(main):001:0> scan 'mytable'
ROW COLUMN+CELL
RESTinsertedKey\x0A column=mycolfamily:number,timestamp=1346875811168,value=7815551212\x0A
key123 column=mycolfamily:duration, timestamp=1346868499125, value=25
key123 column=mycolfamily:number, timestamp=1346868540850, value=6175551212
mykey column=mycolfamily:number, timestamp=1346877875638, value=8885551212
3 row(s) in 0.6100 seconds
|
回页首
结束语
哇,您坚持到了最后,做得好!这仅仅是了解 Hadoop 以及其如何与 Informix 和 DB2 交互的开始。以下是针对您的下一步工作的一些建议。
- 采用上述示例,并使其适应您的服务器。因为虚拟映像中没有那么多的空间,所以您将要使用的数据量不大。
- 获得 Hadoop Administrator 认证。访问 Cloudera 的站点,了解课程和测试信息。
- 获得 Hadoop Developer 认证。
- 使用免费版本的 Cloudera Manager 启动一个集群。
- 开始使用在 CDH4 上运行的 IBM Big Sheets。