amoeba的读写分离和负载均衡
Amoeba(变形虫)项目,专注 分布式数据库 proxy 开发。座落与Client、DB Server(s)之间。对客户端透明。具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。
主要解决了哪些问题:
• 降低数据切分带来的复杂多数据库结构
• 提供切分规则并降低数据切分规则给应用带来的影响
• 降低db 与客户端的连接数
• 读写分离
据说Amoeba性能比mysql proxy要好
在使用amoeba的时候,需要先有一个主从结构的数据库群,具体操作请查看我转载的文章:
环境说明:
操作系统:Red Hat Enterprise Linux 6 64
服务器IP:192.183.3.205(主) 192.183.3.207(从) 192.183.3.242(amoeba)
软件列表:jdk-7u40-linux-x64.tar.gz amoeba-mysql-binary-2.2.0.tar.gz
一,先安装jdk
# mkdir /usr/jdk
#tar -zvxf jdk-7u40-linux-x64.tar.gz -C /usr/jdk
配置环境变量
#vi /etc/profile
加入以下内容
export JAVA_HOME=/usr/jdk7/jdk1.7.0_40
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH
#source /etc/profile
检查jdk是否安装成功,输入java 、javac 如果有出现一堆关于java的可选参数,那么就是安装成功了
二,安装amoeba
# mkdir /usr/amoeba
#tar -zvxf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/amoeba
# cd /usr/amoeba/conf
# ls
Amoeba For MySQL 的使用非常简单,所有的配置文件都是标准的XML 文件,总共有四个配置文件.分别为:
amoeba.xml:主配置文件,Amoeba自身的参数设置以及读写分离的配置
dbServers.xml: 主要配置相关数据源的配置以及连接池配置
rule.xml:配置所有Query 路由规则的信息;
functionMap.xml:配置用于解析Query 中的函数所对应的Java 实现类;
rullFunctionMap.xml:配置路由规则中需要使用到的特定函数的实现类;
我们主要修改amoeba.xml 以及 dbServers.xml
修改amoeba.xml
1
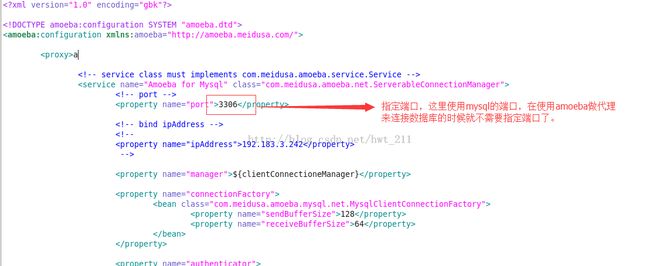
2

3
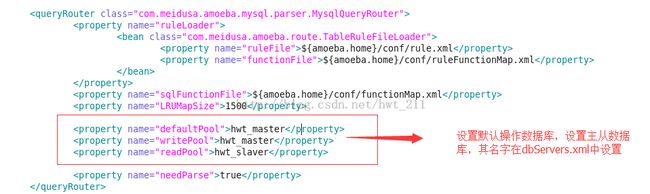
修改dbServers.xml
1.设置主从数据库公共的一些参数
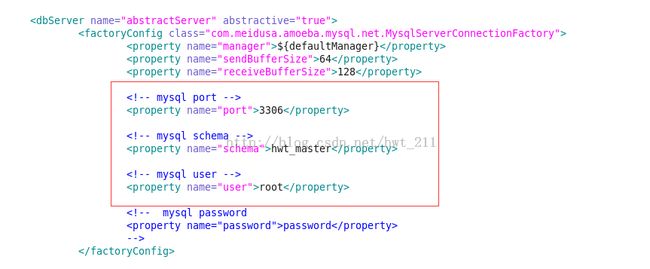
2.
修改完成后,启动amoeba服务
#cd /usr/amoeba/bin
#./amoeba start
如果没有报异常,即启动成功
测试

1,先登录主数据库(master)(192.183.3.205):mysql -uroot -p
2,再登录从数据库(slaver):mysql -h 192.183.3.207 -uroot -p
3,在登录amoeba: mysql -h 192.183.3.242 -uhwt -p (这里的用户名密码是在amoeba的amoeba.xml中配置的)
在amoeba上创建数据库和表:
>Create database if not exists hwt_master;
>create table if not exists temp(id int ,username varchar(20));
>Use hwt_master;
>insert into temp values(1,’amoeba’);
在主数据库(master)上查找:
Select * from temp;
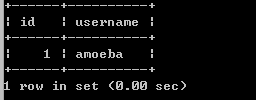
在从数据库(slaver)上查找:
Select * from temp;
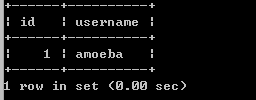
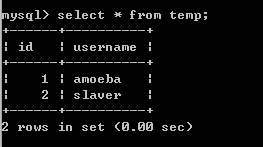
此时我们发现主从数据库上都有数据,这样我们只是知道主从数据库实现了复制,那我们来测试一下amoeba的读写分离:
我们先在从数据库(slaver)上停止主从复制:stop slave;
然后在从数据库(slaver)上插入一条数据:insert into temp values(2,’slaver’);
再在主数据(master)上插入一条数据:insert into temp values(3,’master’);
在amoeba上查询一下结果:
从结果可以看出他是查找的从数据库(slaver)的数据;
然后在amoeba上插入一条数据:insert into temp values(4,’write amoeba’);
在amoeba上查询:
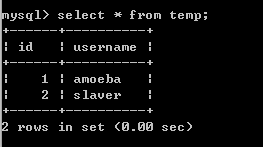
在主数据库(master)上查询:

在从数据库(slaver)上查询