Spark:大数据的“电光石火”

- 轻:Spark 0.6核心代码有2万行,Hadoop 1.0为9万行,2.0为22万行。一方面,感谢Scala语言的简洁和丰富表达力;另一方面,Spark很好地利用了Hadoop和Mesos(伯克利 另一个进入孵化器的项目,主攻集群的动态资源管理)的基础设施。虽然很轻,但在容错设计上不打折扣。主创人Matei声称:“不把错误当特例处理。”言下 之意,容错是基础设施的一部分。
- 快:Spark对小数据集能达到亚秒级的延迟,这对于Hadoop MapReduce(以下简称MapReduce)是无法想象的(由于“心跳”间隔机制,仅任务启动就有数秒的延迟)。就大数据集而言,对典型的迭代机器 学习、即席查询(ad-hoc query)、图计算等应用,Spark版本比基于MapReduce、Hive和Pregel的实现快上十倍到百倍。其中内存计算、数据本地性 (locality)和传输优化、调度优化等该居首功,也与设计伊始即秉持的轻量理念不无关系。
- 灵:Spark提供了不同层面的灵活性。在实现层,它完美演绎了Scala trait动态混入(mixin)策略(如可更换的集群调度器、序列化库);在原语(Primitive)层,它允许扩展新的数据算子 (operator)、新的数据源(如HDFS之外支持DynamoDB)、新的language bindings(Java和Python);在范式(Paradigm)层,Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种 范式。
- 巧:巧在借势和借力。Spark借Hadoop之势,与Hadoop无缝结合;接着Shark(Spark上的数据仓库实现)借了Hive的势;图计算借 用Pregel和PowerGraph的API以及PowerGraph的点分割思想。一切的一切,都借助了Scala(被广泛誉为Java的未来取代 者)之势:Spark编程的Look'n'Feel就是原汁原味的Scala,无论是语法还是API。在实现上,又能灵巧借力。为支持交互式编 程,Spark只需对Scala的Shell小做修改(相比之下,微软为支持JavaScript Console对MapReduce交互式编程,不仅要跨越Java和JavaScript的思维屏障,在实现上还要大动干戈)。
说了一大堆好处,还是要指出Spark未臻完美。它有先天的限制,不能很好地支持细粒度、异步的数据处理;也有后天的原因,即使有很棒的基因,毕竟还刚刚起步,在性能、稳定性和范式的可扩展性上还有很大的空间。
计算范式和抽象
Spark首先是一种粗粒度数据并行(data parallel)的计算范式。
数据并行跟任务并行(task parallel)的区别体现在以下两方面。
- 计算的主体是数据集合,而非个别数据。集合的长度视实现而定,如SIMD(单指令多数据)向量指令一般是4到64,GPU的SIMT(单指令多线程)一般 是32,SPMD(单程序多数据)可以更宽。Spark处理的是大数据,因此采用了粒度很粗的集合,叫做Resilient Distributed Datasets(RDD)。
- 集合内的所有数据都经过同样的算子序列。数据并行可编程性好,易于获得高并行性(与数据规模相关,而非与程序逻辑的并行性相关),也易于高效地映射到底层 的并行或分布式硬件上。传统的array/vector编程语言、SSE/AVX intrinsics、CUDA/OpenCL、Ct(C++ for throughput),都属于此类。不同点在于,Spark的视野是整个集群,而非单个节点或并行处理器。
数据并行的范式决定了 Spark无法完美支持细粒度、异步更新的操作。图计算就有此类操作,所以此时Spark不如GraphLab(一个大规模图计算框架);还有一些应用, 需要细粒度的日志更新和数据检查点,它也不如RAMCloud(斯坦福的内存存储和计算研究项目)和Percolator(Google增量计算技术)。 反过来,这也使Spark能够精心耕耘它擅长的应用领域,试图粗细通吃的Dryad(微软早期的大数据平台)反而不甚成功。
Spark的RDD,采用了Scala集合类型的编程风格。它同样采用了函数式语义(functional semantics):一是闭包,二是RDD的不可修改性。逻辑上,每一个RDD算子都生成新的RDD,没有副作用,所以算子又被称为是确定性的;由于所 有算子都是幂等的,出现错误时只需把算子序列重新执行即可。
Spark的计算抽象是数据流,而且是带有工作集(working set)的数据流。流处理是一种数据流模型,MapReduce也是,区别在于MapReduce需要在多次迭代中维护工作集。工作集的抽象很普遍,如多 迭代机器学习、交互式数据挖掘和图计算。为保证容错,MapReduce采用了稳定存储(如HDFS)来承载工作集,代价是速度慢。HaLoop采用循环 敏感的调度器,保证前次迭代的Reduce输出和本次迭代的Map输入数据集在同一台物理机上,这样可以减少网络开销,但无法避免磁盘I/O的瓶颈。
Spark的突破在于,在保证容错的前提下,用内存来承载工作集。内存的存取速度快于磁盘多个数量级,从而可以极大提升性能。关键是实现容错,传统上有两种方法:日 志和检查点。考虑到检查点有数据冗余和网络通信的开销,Spark采用日志数据更新。细粒度的日志更新并不便宜,而且前面讲过,Spark也不擅长。 Spark记录的是粗粒度的RDD更新,这样开销可以忽略不计。鉴于Spark的函数式语义和幂等特性,通过重放日志更新来容错,也不会有副作用。
编程模型
来看一段代码:textFile算子从HDFS读取日志文件,返回“file”(RDD);filter算子筛出带“ERROR”的行,赋给 “errors”(新RDD);cache算子把它缓存下来以备未来使用;count算子返回“errors”的行数。RDD看起来与Scala集合类型 没有太大差别,但它们的数据和运行模型大相迥异。
图1给出了RDD数据模型,并将上例中用到的四个算子映射到四种算子类型。Spark程序工作在两个空间中:Spark RDD空间和Scala原生数据空间。在原生数据空间里,数据表现为标量(scalar,即Scala基本类型,用橘色小方块表示)、集合类型(蓝色虚线 框)和持久存储(红色圆柱)。
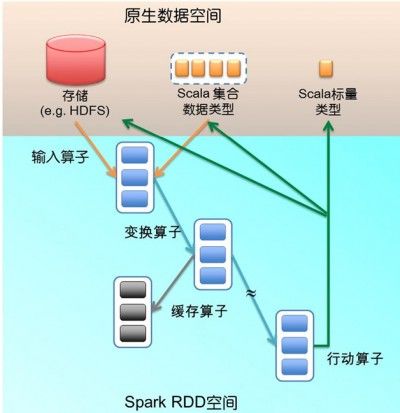
图1 两个空间的切换,四类不同的RDD算子
输入算子(橘色箭头)将Scala集合类型或存储中的数据吸入RDD空间,转为RDD(蓝色实线框)。输入算子的输入大致有两类:一类针对Scala集合类型,如parallelize;另一类针对存储数据,如上例中的textFile。输入算子的输出就是Spark空间的RDD。
因为函数语义,RDD经过变换(transformation)算子(蓝色箭头)生成新的RDD。变换算子的输入和输出都是RDD。RDD会被划分成很多的分区 (partition)分布到集群的多个节点中,图1用蓝色小方块代表分区。注意,分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存或存 储。这是很重要的优化,以防止函数式不变性导致的内存需求无限扩张。有些RDD是计算的中间结果,其分区并不一定有相应的内存或存储与之对应,如果需要 (如以备未来使用),可以调用缓存算子(例子中的cache算子,灰色箭头表示)将分区物化(materialize)存下来(灰色方块)。
一部分变换算子视RDD的元素为简单元素,分为如下几类:
- 输入输出一对一(element-wise)的算子,且结果RDD的分区结构不变,主要是map、flatMap(map后展平为一维RDD);
- 输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个)、coalesce(分区减少);
- 从输入中选择部分元素的算子,如filter、distinct(去除冗余元素)、subtract(本RDD有、它RDD无的元素留下来)和sample(采样)。
另一部分变换算子针对Key-Value集合,又分为:
- 对单个RDD做element-wise运算,如mapValues(保持源RDD的分区方式,这与map不同);
- 对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要,后面会讲);
- 对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
- 对两个RDD基于key进行join和重组,如join、cogroup。
后三类操作都涉及重排,称为shuffle类操作。
从RDD到RDD的变换算子序列,一直在RDD空间发生。这里很重要的设计是lazy evaluation:计算并不实际发生,只是不断地记录到元数据。元数据的结构是DAG(有向无环图),其中每一个“顶点”是RDD(包括生产该RDD 的算子),从父RDD到子RDD有“边”,表示RDD间的依赖性。Spark给元数据DAG取了个很酷的名字,Lineage(世系)。这个 Lineage也是前面容错设计中所说的日志更新。
Lineage一直增长,直到遇上行动(action)算子(图1中的绿色箭头),这时 就要evaluate了,把刚才累积的所有算子一次性执行。行动算子的输入是RDD(以及该RDD在Lineage上依赖的所有RDD),输出是执行后生 成的原生数据,可能是Scala标量、集合类型的数据或存储。当一个算子的输出是上述类型时,该算子必然是行动算子,其效果则是从RDD空间返回原生数据 空间。
行动算子有如下几类:生成标量,如count(返回RDD中元素的个数)、reduce、fold/aggregate(见 Scala同名算子文档);返回几个标量,如take(返回前几个元素);生成Scala集合类型,如collect(把RDD中的所有元素倒入 Scala集合类型)、lookup(查找对应key的所有值);写入存储,如与前文textFile对应的saveAsText-File。还有一个检 查点算子checkpoint。当Lineage特别长时(这在图计算中时常发生),出错时重新执行整个序列要很长时间,可以主动调用 checkpoint把当前数据写入稳定存储,作为检查点。
这里有两个设计要点。首先是lazy evaluation。熟悉编译的都知道,编译器能看到的scope越大,优化的机会就越多。Spark虽然没有编译,但调度器实际上对DAG做了线性复 杂度的优化。尤其是当Spark上面有多种计算范式混合时,调度器可以打破不同范式代码的边界进行全局调度和优化。下面的例子中把Shark的SQL代码 和Spark的机器学习代码混在了一起。各部分代码翻译到底层RDD后,融合成一个大的DAG,这样可以获得更多的全局优化机会。

另一个要点是一旦行动算子产生原生数据,就必须退出RDD空间。因为目前Spark只能够跟踪RDD的计算,原生数据的计算对它来说是不可见的(除非以后 Spark会提供原生数据类型操作的重载、wrapper或implicit conversion)。这部分不可见的代码可能引入前后RDD之间的依赖,如下面的代码:

第三行filter对errors.count()的依赖是由(cnt-1)这个原生数据运算产生的,但调度器看不到这个运算,那就会出问题了。
由于Spark并不提供控制流,在计算逻辑需要条件分支时,也必须回退到Scala的空间。由于Scala语言对自定义控制流的支持很强,不排除未来Spark也会支持。
Spark 还有两个很实用的功能。一个是广播(broadcast)变量。有些数据,如lookup表,可能会在多个作业间反复用到;这些数据比RDD要小得多,不 宜像RDD那样在节点之间划分。解决之道是提供一个新的语言结构——广播变量,来修饰此类数据。Spark运行时把广播变量修饰的内容发到各个节点,并保 存下来,未来再用时无需再送。相比Hadoop的distributed cache,广播内容可以跨作业共享。Spark提交者Mosharaf师从P2P的老法师Ion Stoica,采用了BitTorrent(没错,就是下载电影的那个BT)的简化实现。有兴趣的读者可以参考SIGCOMM'11的论文 Orchestra。另一个功能是Accumulator(源于MapReduce的counter):允许Spark代码中加入一些全局变量做 bookkeeping,如记录当前的运行指标。
运行和调度
图2显示了Spark程序的运行场景。它由客户端启动,分两个阶段:第一阶段记录变换算子序列、增量构建DAG图;第二阶段由行动算子触 发,DAGScheduler把DAG图转化为作业及其任务集。Spark支持本地单节点运行(开发调试有用)或集群运行。对于后者,客户端运行于 master节点上,通过Cluster manager把划分好分区的任务集发送到集群的worker/slave节点上执行。

图2 Spark程序运行过程
Spark 传统上与Mesos“焦不离孟”,也可支持Amazon EC2和YARN。底层任务调度器的基类是个trait,它的不同实现可以混入实际的执行。例如,在Mesos上有两种调度器实现,一种把每个节点的所有 资源分给Spark,另一种允许Spark作业与其他作业一起调度、共享集群资源。worker节点上有任务线程(task thread)真正运行DAGScheduler生成的任务;还有块管理器(block manager)负责与master上的block manager master通信(完美使用了Scala的Actor模式),为任务线程提供数据块。
最有趣的部分是DAGScheduler。下面详解它的工作过程。RDD的数据结构里很重要的一个域是对父RDD的依赖。如图3所示,有两类依赖:窄(Narrow)依赖和宽(Wide)依赖。
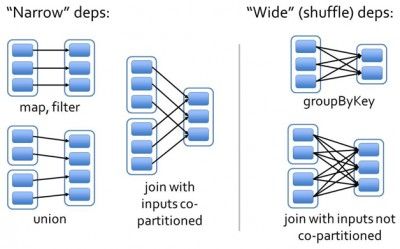
图3 窄依赖和宽依赖
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,和两个父RDD的分区对应于一个子RDD 的分区。图3中,map/filter和union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类。
宽依赖指子RDD的分区依赖于父RDD的所有分区,这是因为shuffle类操作,如图3中的groupByKey和未经协同划分的join。
窄依赖对优化很有利。逻辑上,每个RDD的算子都是一个fork/join(此join非上文的join算子,而是指同步多个并行任务的barrier): 把计算fork到每个分区,算完后join,然后fork/join下一个RDD的算子。如果直接翻译到物理实现,是很不经济的:一是每一个RDD(即使 是中间结果)都需要物化到内存或存储中,费时费空间;二是join作为全局的barrier,是很昂贵的,会被最慢的那个节点拖死。如果子RDD的分区到 父RDD的分区是窄依赖,就可以实施经典的fusion优化,把两个fork/join合为一个;如果连续的变换算子序列都是窄依赖,就可以把很多个 fork/join并为一个,不但减少了大量的全局barrier,而且无需物化很多中间结果RDD,这将极大地提升性能。Spark把这个叫做流水线 (pipeline)优化。
变换算子序列一碰上shuffle类操作,宽依赖就发生了,流水线优化终止。在具体实现 中,DAGScheduler从当前算子往前回溯依赖图,一碰到宽依赖,就生成一个stage来容纳已遍历的算子序列。在这个stage里,可以安全地实 施流水线优化。然后,又从那个宽依赖开始继续回溯,生成下一个stage。
要深究两个问题:一,分区如何划分;二,分区该放到集群内哪个节点。这正好对应于RDD结构中另外两个域:分区划分器(partitioner)和首选位置(preferred locations)。
分区划分对于shuffle类操作很关键,它决定了该操作的父RDD和子RDD之间的依赖类型。上文提到,同一个join算子,如果协同划分的话,两个父 RDD之间、父RDD与子RDD之间能形成一致的分区安排,即同一个key保证被映射到同一个分区,这样就能形成窄依赖。反之,如果没有协同划分,导致宽 依赖。
所谓协同划分,就是指定分区划分器以产生前后一致的分区安排。Pregel和HaLoop把这个作为系统内置的一部分;而Spark 默认提供两种划分器:HashPartitioner和RangePartitioner,允许程序通过partitionBy算子指定。注意,HashPartitioner能够发挥作用,要求key的hashCode是有效的,即同样内容的key产生同样的hashCode。这对 String是成立的,但对数组就不成立(因为数组的hashCode是由它的标识,而非内容,生成)。这种情况下,Spark允许用户自定义 ArrayHashPartitioner。
第二个问题是分区放置的节点,这关乎数据本地性:本地性好,网络通信就少。有些RDD产生时就 有首选位置,如HadoopRDD分区的首选位置就是HDFS块所在的节点。有些RDD或分区被缓存了,那计算就应该送到缓存分区所在的节点进行。再不 然,就回溯RDD的lineage一直找到具有首选位置属性的父RDD,并据此决定子RDD的放置。
宽/窄依赖的概念不止用在调度中,对容错也很有用。如果一个节点宕机了,而且运算是窄依赖,那只要把丢失的父RDD分区重算即可,跟其他节点没有依赖。而宽依赖需要父RDD的所有分区都存在, 重算就很昂贵了。所以如果使用checkpoint算子来做检查点,不仅要考虑lineage是否足够长,也要考虑是否有宽依赖,对宽依赖加检查点是最物 有所值的。
结语
因为篇幅所限,本文只能介绍Spark的基本概念和设计思想,内容来自Spark的多篇论文(以NSDI'12 “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing”为主),也有我和同事研究Spark的心得,以及多年来从事并行/分布式系统研究的感悟。Spark核心成员/Shark主创者辛湜 对本文作了审阅和修改,特此致谢!
Spark站在一个很高的起点上,有着高尚的目标,但它的征程还刚刚开始。Spark致力于构建开放的生态系统( http://spark-project.org/ https://wiki.apache.org/incubator/SparkProposal),愿与大家一起为之努力!
作者吴甘沙,英特尔中国研究院首席工程师,主要研究方向包括物联网、大数据、面向海量数据处理的分布式嵌入式系统,为新兴应用、使用模式和服务提供支撑的软件环境。