Prege(图计算框架)l: A System for Large-Scale Graph Processing(译)
http://duanple.blog.163.com/blog/static/70971767201281610126277/
2012-09-16 22:12:06| 分类:搜索与分布式 | 标签:pregel google论文 图计算 |举报|字号大中小 订阅
作者:Grzegorz Malewicz, Matthew H. Austern .etc.Google Inc 2010-6
原文: http://people.apache.org/~edwardyoon/documents/pregel.pdf
译者:phylips@bmy 2012-09-14
译文: http://duanple.blog.163.com/blog/static/70971767201281610126277/
[说明:Pregel这篇是发表在2010年的SIGMOD上,Pregel这个名称是为了纪念欧拉,在他提出的格尼斯堡七桥问题中,那些桥所在的河就叫Pregel。最初是为了解决PageRank计算问题,由于MapReduce并不适于这种场景,所以需要发展新的计算模型去完成这项计算任务,在这个过程中逐步提炼出一个通用的图计算框架,并用来解决更多的问题。核心思想源自BSP模型,这个就更早了,是在上世纪80年代由Leslie Valiant(2010年图灵奖得主)提出,之后在1990的Communications of the ACM 上,正式发表了题为A bridging model for parallel computation的文章。目前实际上已经有针对Pregel这篇文章的翻译版本了,不过只翻译了出了前半部分关于Pregel的设计与实现部分。其实后半部分也很重要,有助于理解整个图计算的历史背景,以及Pregel本身的性能和项目本身的演化等,另外最近越来越多的人开始关注这一文章,所以还是抽出时间重新阅读了一遍,并重新翻译出来,以供参考]
摘要
很多现实中的计算问题都会涉及到大规模的图。经典的例子像网页链接关系和各种社交关系等。这些图的规模—某些情况下,可能达到数十亿的顶点和数万亿的边—使得如何对它们进行高效的处理成为一个巨大的挑战。在这篇论文中,我们将提出一种适于处理这类问题的计算模型。程序使用一系列的迭代过程来表达,在每一次迭代中,每个顶点会接收来自上一次迭代的信息,并发送信息给其它顶点,同时可能修改其自身状态以及以它为顶点的出边的状态,或改变整个图的拓扑结构。这种以顶点为中心的策略非常灵活,足以用来表达一大类的算法。该模型的设计目标就是可以高效,可扩展,和容错地在由上千台机器组成的集群中得以实现。此外它的隐式的同步性(implied synchronicity)使得程序本身很容易理解。分布式相关的细节被隐藏在一组抽象出来的API下面。这样展现给人们的就是一个具有丰富表现力,易于编程的大规模图处理框架。
关键词
分布式计算,图算法
1.导引
Internet使得Web graph成为一个人们争相分析和研究的热门对象。Web 2.0更是激发了人们对社交网络的关注。其他的一些大型图对象(如交通路线图,新闻文章的相似性,疾病爆发路径,以及发表的科学研究文章中的引用关系等),也已经被研究了数十年了。经常被用到的一些算法包括最短路径算法,不同种类的聚类算法,各种page rank算法变种。还有其他许多具有实际价值的图计算问题,比如最小切割,连通分支。
对大型图对象进行高效的处理,是非常具有挑战性的。图算法常常表现出比较差的内存访问局部性,针对单个顶点的处理工作过少,以及计算过程中伴随着的并行度的改变等问题[31,39]。分布式的介入更是加剧了locality的问题,并且增加了在计算过程中机器发生故障的概率。尽管大型图对象无处不在,及其在商业上的重要性,但是据我们所知,目前还不存在一种在大规模分布式环境下,可以基于各种图表示方法来实现任意图算法的,可扩展的通用系统。
要实现一种处理大规模图对象的算法通常意味着要在以下几点中作出选择:
1.
为特定的图应用定制相应的分布式实现。在面对新的图算法或者图表示方式时,就需要做大量的重复实现,不通用。
2.
基于现有的分布式计算平台,而这种情况下,通常它们并不适于做图处理。比如mapreduce就是一个对许多大规模计算问题都非常合适的计算框架。有时它也被用来对大规模图对象进行挖掘[11,30],但是通常在性能和易用性上都不是最优的。尽管这种对数据处理的基本模式经过扩展,已经可以使用方便的聚合(facilitate aggregation)[Sawzall]以及类SQL的查询方式[Pig,DryadLINQ],但这些扩展对于图算法这种更适合用消息传递模型的问题来说,通常并不理想。
3.
使用单机的图算法库,如BGL[43],LEAD[35],NetworkX[25],JDSL[20],Standford GraphBase[29],FGL[16]等,但对可以解决的问题的规模提出了很大的限制。
4.
使用已有的并行图计算系统。Parallel BGL[22]和CGMgraph[8]这些库实现了很多并行图算法,但是并没有解决对大规模分布式系统中来说非常重要的容错等一些问题。
以上的这些选择都或多或少的存在一些局限性。为了解决大型图的分布式计算问题,我们搭建了一套可扩展,有容错机制的平台,该平台提供了一套非常灵活的API,可以描述各种各样的图计算。这篇论文将描述这套名为Pregel的系统,并分享我们的经验。
对Pregel计算系统的灵感来自Valiant提出的BSP(Bluk Synchronous Parallell)模型[45]。Pregel的计算过程由一系列被称为超级步(superstep)的迭代(iterations)组成。在每一个超级步中,计算框架都会针对每个顶点调用用户自定义的函数,这个过程是并行的{!即不是一个一个顶点的串行调用,同一时刻可能有多个顶点被调用}。该函数描述的是一个顶点V在一个superstep S中需要执行的操作。该函数可以读取前一个超级步(S-1)中发送给V的消息,并发送消息给其他顶点,这些消息将会在下一个超级步(S+1)中被接收,并且在此过程中修改顶点V及其出边的状态。消息通常沿着顶点的出边发送,但一个消息可能会被发送到任意已知ID的顶点上去。
这种以顶点为中心的策略很容易让人联想起MapReduce,因为他们都让用户只需要关注其本地的执行逻辑,每条记录的处理都是独立的{!相互之间不需要通信},系统将这些行为组合起来就可以完成大规模数据的处理。根据设计,这种计算模型非常的适合分布式的实现:它没有将任何检测执行顺序的机制暴露在单个超级步中,所有的通信都仅限于S到S+1之间。
模型的同步性使得在实现算法时很容易理解程序的语义,并且使得Pregel程序天生对异步系统中经常出现的死锁以及临界资源竞争就是免疫的。理论上,Pregel程序的性能即使在与足够并行化的异步系统[28,34]的对比中都有一定的竞争力。因为通常情况下图计算的应用中顶点的数量要远远大于机器的数量,所以必须要平衡各机器之间的负载,这样各个superstep间的同步就不会增加过多的延迟{!负载平衡会引入大量的通信开销,就使得超级步间的同步开销并不那么显眼了}。
本文接下来的结构如下:第2节主要描述该模型;第3节描述其C++ API;第4节讨论实现方面的情况,包括性能和容错等;第5节将列举几个实际应用;第6节将提供一些性能的对比结果;最后我们会讨论下相关的研究工作和未来的方向。
2.计算模型
在Pregel计算模型中,输入是一个有向图,该有向图的每一个顶点都有一个相应的由String描述的顶点标识符。每一个顶点都有一个与之对应的可修改的用户自定义值。每一条有向边都和其源顶点关联,并且也拥有一个可修改的用户自定义值,并同时还记录了其目标顶点的标识符。
一个典型的Pregel计算过程如下:读取输入初始化该图,当图被初始化好后,运行一系列的超级步直到整个计算结束,这些超级步之间通过一些全局的同步点分隔,输出结果结束计算。
在每个超级步中,顶点的计算都是并行的,每个顶点执行相同的用于表达给定算法逻辑的用户自定义函数。每个顶点可以修改其自身及其出边的状态,接收前一个超级步(S-1)中发送给它的消息,并发送消息给其他顶点(这些消息将会在下一个超级步中被接收),甚至是修改整个图的拓扑结构。边,在这种计算模式中并不是核心对象,没有相应的计算运行在其上。
算法是否能够结束取决于是否所有的顶点都已经“vote”标识其自身已经达到“halt”状态了。在第0个超级步,所有顶点都处于active状态,所有的active顶点都会参与所有对应superstep中的计算。顶点通过将其自身的status设置成“halt”来表示它已经不再active。这就表示该顶点没有进一步的计算需要执行,除非被再次被外部触发,而Pregel框架将不会在接下来的superstep中执行该顶点,除非该顶点收到其它顶点传送的消息。如果顶点接收到消息被唤醒进入active状态,那么在随后的计算中该顶点必须显式的deactive {!?是说顶点此后会一直处于active状态,然后要想不active必须显示deactive,但是也可以选择不deactive,还是说顶点必须要显式deactive呢,感觉前者更合理}。整个计算在所有顶点都达到“inactive”状态,并且没有message在传送的时候宣告结束。这种简单的状态机如下图所示:
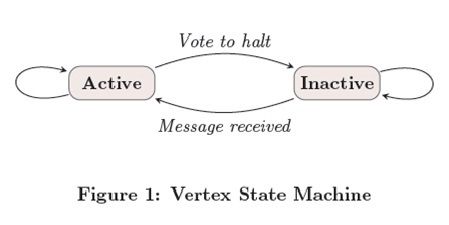
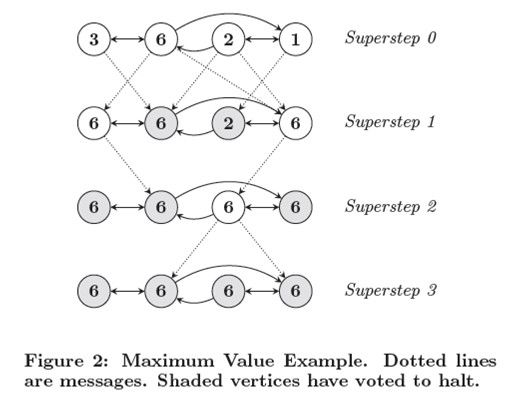
图2通过一个简单的例子来说明这些基本概念:给定一个强连通图,图中每个顶点都包含一个值,它会将最大值传播到每个顶点。在每个超级步中,顶点会从接收到的消息中选出一个最大值,并将这个值传送给其所有的相邻顶点。当某个超级步中已经没有顶点更新其值,那么算法就宣告结束。
图算法其实也可以被写成是一系列的链式MapReduce调用[11,30]。我们选择了另外一种不同的模式的原因在于可用性和性能。Pregel将顶点和边保存在执行计算的那台机器上,而仅仅利用网络来传输信息。而MapReduce本质上是函数式的,所以将图算法用链式MapReduce来实现就需要将整个图的状态从一个阶段传输到另外一个阶段,这样就需要许多的通信和随之而来的序列化和反序列化的开销。另外,这一连串的MapReduce作业各执行阶段需要的协同工作也增加了编程复杂度,而在Pregel中通过引入超级步避免了这样的情况。
3.C++ API
这一节主要介绍Pregel C++ API中最重要的几个方面,暂时忽略相关其他机制。编写一个Pregel程序需要继承Pregel中已预定义好的一个基类——Vertex类(见图3)。

用户覆写Vertex类的虚函数Compute(),该函数会在每一个超级步中对每一个顶点进行调用。预定义的Vertex类方法允许Compute()方法查询当前顶点及其边的信息,以及发送消息到其他的顶点。Compute()方法可以通过调用GetValue()方法来得到当前顶点的值,或者通过调用MutableValue()方法来修改当前顶点的值。同时还可以通过由出边的迭代器提供的方法来查看修改出边对应的值。这种状态的修改是立时可见的。由于这种可见性仅限于被修改的那个顶点,所以不同顶点并发进行的数据访问是不存在竞争关系的。
顶点和其对应的边所关联的值是唯一需要在超级步之间持久化的顶点级状态。将由计算框架管理的图状态限制在一个单一的顶点值或边值的这种做法,简化了主计算流程,图的分布以及故障恢复。
3.1 消息传递机制
顶点之间的通信是直接通过发送消息,每条消息都包含了消息值和目标顶点的名称。消息值的数据类型是由用户通过Vertex类的模版参数来指定。
在一个超级步中,一个顶点可以发送任意多的消息。当顶点V的Compute()方法在S+1超级步中被调用时,所有在S超级步中发送给顶点V的消息都可以通过一个迭代器来访问到。在该迭代器中并不保证消息的顺序,但是可以保证消息一定会被传送并且不会重复。
一种通用的使用方式为:对一个顶点V,遍历其自身的出边,向每条出边发送消息到该边的目标顶点,如图4中PageRank算法(参见5.1节)所示的那样。但是,dest_vertex并不一定是顶点V的相邻顶点。一个顶点可以从之前收到的消息中获取到其非相邻顶点的标识符,或者顶点标识符可以隐式的得到。比如,图可能是一个clique(一个图中两两相邻的一个点集,或是一个完全子图),顶点的命名规则都是已知的(从V1到Vn),在这种情况下甚至都不需要显式地保存边的信息。
当任意一个消息的目标顶点不存在时,便执行用户自定义的handlers。比如在这种情况下,一个handler可以创建该不存在的顶点或从源顶点中删除这条边。
3.2 Combiners
发送消息,尤其是当目标顶点在另外一台机器时,会产生一些开销。某些情况可以在用户的协助下降低这种开销。比方说,假如Compute() 收到许多的int 值消息,而它仅仅关心的是这些值的和,而不是每一个int的值,这种情况下,系统可以将发往同一个顶点的多个消息合并成一个消息,该消息中仅包含它们的和值,这样就可以减少传输和缓存的开销。
Combiners在默认情况下并没有被开启,这是因为要找到一种对所有顶点的Compute()函数都合适的Combiner是不可能的。而用户如果想要开启Combiner的功能,需要继承Combiner类,覆写其virtual函数Combine()。框架并不会确保哪些消息会被Combine而哪些不会,也不会确保传送给Combine()的值和Combining操作的执行顺序。所以Combiner只应该对那些满足交换律和结合律的操作打开。
对于某些算法来说,比如单源最短路径(参见5.2节),我们观察到通过使用Combiner将流量降低了4倍多。
3.3 Aggregators
Pregel的aggregators是一种提供全局通信,监控和数据查看的机制。在一个超级步S中,每一个顶点都可以向一个aggregator提供一个数据,系统会使用一种reduce操作来负责聚合这些值,而产生的值将会对所有的顶点在超级步S+1中可见。Pregel包含了一些预定义的aggregators,如可以在各种整数和string类型上执行的min,max,sum操作。
Aggregators可以用来做统计。例如,一个sum aggregator可以用来统计每个顶点的出度,最后相加就是整个图的边的条数。更复杂的一些reduce操作还可以产生统计直方图。
Aggregators也可以用来做全局协同。例如, Compute()函数的一些逻辑分支可能在某些超级步中执行,直到and aggregator表明所有顶点都满足了某条件,之后执行另外的逻辑分支直到结束。又比如一个作用在顶点ID之上的min和max aggregator,可以用来选定某顶点在整个计算过程中扮演某种角色等。
要定义一个新的aggregator,用户需要继承预定义的Aggregator类,并定义在第一次接收到输入值后如何初始化,以及如何将接收到的多个值最后reduce成一个值。Aggregator操作也应该满足交换律和结合律。
默认情况下,一个aggregator仅仅会对来自同一个超级步的输入进行聚合,但是有时也可能需要定义一个sticky aggregator,它可以从所有的supersteps中接收数据。这是非常有用的,比如要维护全局的边条数,那么就仅仅在增加和删除边的时候才调整这个值了。
还可以有更高级的用法。比如,可以用来实现一个△-stepping最短路径算法所需要的分布式优先队列[37]。每个顶点会根据它的当前距离分配一个优先级bucket。在每个超级步中,顶点将它们的indices汇报给min aggregator。在下一个超级步中,将最小值广播给所有worker,然后让在最小index的bucket中的顶点放松它们的边。{!说明此处的核心在于说明aggregators用法,关于△-stepping最短路径算法不再解释,感兴趣的可以参考这篇文章: Δ-Stepping: A Parallel Single Source Shortest Path Algorithm }
3.4 Topology Mutations
有一些图算法可能需要改变图的整个拓扑结构。比如一个聚类算法,可能会将每个聚类替换成一个单一顶点,又比如一个最小生成树算法会删除所有除了组成树的边之外的其他边。正如用户可以在自定义的Compute()函数能发送消息,同样可以产生在图中增添和删除边或顶点的请求。
多个顶点有可能会在同一个超级步中产生冲突的请求(比如两个请求都要增加一个顶点V,但初始值不一样)。Pregel中用两种机制来决定如何调用:局部有序和handlers。
由于是通过消息发送的,拓扑改变在请求发出以后,在超级步中可以高效地执行。在该超级步中,删除会首先被执行,先删除边后删除顶点,因为顶点的删除通常也意味着删除其所有的出边。然后执行添加操作,先增加顶点后增加边,并且所有的拓扑改变都会在Compute()函数调用前完成。这种局部有序保证了大多数冲突的结果的确定性。
剩余的冲突就需要通过用户自定义的handlers来解决。如果在一个超级步中有多个请求需要创建一个相同的顶点,在默认情况下系统会随便挑选一个请求,但有特殊需求的用户可以定义一个更好的冲突解决策略,用户可以在Vertex类中通过定义一个适当的handler函数来解决冲突。同一种handler机制将被用于解决由于多个顶点删除请求或多个边增加请求或删除请求而造成的冲突。我们委托handler来解决这种类型的冲突,从而使得Compute()函数变得简单,而这样同时也会限制handler和Compute()的交互,但这在应用中还没有遇到什么问题。
我们的协同机制比较懒,全局的拓扑改变在被apply之前不需要进行协调{!即在变更请求的发出端不会进行任何的控制协调,只有在它被接收到然后apply时才进行控制,这样就简化了流程,同时能让发送更快}。这种设计的选择是为了优化流式处理。直观来讲就是对顶点V的修改引发的冲突由V自己来处理。
Pregel同样也支持纯local的拓扑改变,例如一个顶点添加或删除其自身的出边或删除其自己。Local的拓扑改变不会引发冲突,并且顶点或边的本地增减能够立即生效,很大程度上简化了分布式的编程。
3.5 Input and Output
可以采用多种文件格式进行图的保存,比如可以用text文件,关系数据库,或者Bigtable[9]中的行。为了避免规定死一种特定文件格式,Pregel将从输入中解析出图结构的任务从图的计算过程中进行了分离。类似的,结果可以以任何一种格式输出并根据应用程序选择最适合的存储方式。Pregel library本身提供了很多常用文件格式的readers和writers,但是用户可以通过继承Reader和Writer类来定义他们自己的读写方式。
4.Implementation
Pregel是为Google的集群架构[3]而设计的。每一个集群都包含了上千台机器,这些机器都分列在许多机架上,机架之间有这非常高的内部通信带宽。集群之间是内部互联的,但地理上是分布在不同地方的。
应用程序通常通过一个集群管理系统执行,该管理系统会通过调度作业来优化集群资源的使用率,有时候会杀掉一些任务或将任务迁移到其他机器上去。该系统中提供了一个名字服务系统,所以各任务间可以通过与物理地址无关的逻辑名称来各自标识自己。持久化的数据被存储在GFS[19]或Bigtable[9]中,而临时文件比如缓存的消息则存储在本地磁盘中。
4.1 Basic Architecture
Pregel library将一张图划分成许多的partitions,每一个partition包含了一些顶点和以这些顶点为起点的边。将一个顶点分配到某个partition上去取决于该顶点的ID,这意味着即使在别的机器上,也是可以通过顶点的ID来知道该顶点是属于哪个partition,即使该顶点已经不存在了。默认的partition函数为hash(ID) mod N,N为所有partition总数,但是用户可以替换掉它。
将一个顶点分配给哪个worker机器是整个Pregel中对分布式不透明的主要地方。有些应用程序使用默认的分配策略就可以工作地很好,但是有些应用可以通过定义更好地利用了图本身的locality的分配函数而从中获益。比如,一种典型的可以用于Web graph的启发式方法是,将来自同一个站点的网页数据分配到同一台机器上进行计算。
在不考虑出错的情况下,一个Pregel程序的执行过程分为如下几个步骤:
1.
用户程序的多个copy开始在集群中的机器上执行。其中有一个copy将会作为master,其他的作为worker,master不会被分配图的任何一部分,而只是负责协调worker间的工作。worker利用集群管理系统中提供的名字服务来定位master位置,并发送注册信息给master。
2.
Master决定对这个图需要多少个partition,并分配一个或多个partitions到worker所在的机器上。这个数字也可能由用户进行控制。一个worker上有多个partition的情况下,可以提高partitions间的并行度,更好的负载平衡,通常都可以提高性能。每一个worker负责维护在其之上的图的那一部分的状态(顶点及边的增删),对该部分中的顶点执行Compute()函数,并管理发送出去的以及接收到的消息。每一个worker都知道该图的计算在所有worker中的分配情况。
3.
Master进程为每个worker分配用户输入中的一部分,这些输入被看做是一系列记录的集合,每一条记录都包含任意数目的顶点和边。对输入的划分和对整个图的划分是正交的,通常都是基于文件边界进行划分。如果一个worker加载的顶点刚好是这个worker所分配到的那一部分,那么相应的数据结构就会被立即更新。否则,该worker就需要将它发送到它所应属于的那个worker上。当所有的输入都被load完成后,所有的顶点将被标记为active状态,
4.
Master给每个worker发指令,让其运行一个超级步,worker轮询在其之上的顶点,会为每个partition启动一个线程。调用每个active顶点的Compute()函数,传递给它从上一次超级步发送来的消息。消息是被异步发送的,这是为了使得计算和通信可以并行,以及进行batching,但是消息的发送会在本超级步结束前完成。当一个worker完成了其所有的工作后,会通知master,并告知当前该worker上在下一个超级步中将还有多少active节点。
不断重复该步骤,只要有顶点还处在active状态,或者还有消息在传输。
5.
计算结束后,master会给所有的worker发指令,让它保存它那一部分的计算结果。
4.2 Fault tolerance
容错是通过checkpointing来实现的。在每个超级步的开始阶段,master命令worker让它保存它上面的partitions的状态到持久存储设备,包括顶点值,边值,以及接收到的消息。Master自己也会保存aggregator的值。
worker的失效是通过master发给它的周期性的ping消息来检测的。如果一个worker在特定的时间间隔内没有收到ping消息,该worker进程会终止。如果master在一定时间内没有收到worker的反馈,就会将该worker进程标记为失败。
当一个或多个worker发生故障,被分配到这些worker的partitions的当前状态信息就丢失了。Master重新分配图的partition到当前可用的worker集合上,所有的partition会从最近的某超级步S开始时写出的checkpoint中重新加载状态信息。该超级步可能比在失败的worker上最后运行的超级步 S’早好几个阶段,此时失去的几个superstep将需要被重新执行{!应该是所有的partition都需要重新分配,而不仅仅是失败的worker上的那些,否则如何重新执行丢失的超级步,也正是这样才有了下面的confined recovery}。我们对checkpoint频率的选择基于某个故障模型[13]的平均时间,以平衡checkpoint的开销和恢复执行的开销。
为了改进恢复执行的开销和延迟, Confined recovery已经在开发中。除了基本的checkpoint,worker同时还会将其在加载图的过程中和超级步中发送出去的消息写入日志。这样恢复就会被限制在丢掉的那些 partitions上。它们会首先通过checkpoint进行恢复,然后系统会通过回放来自正常的partitions的记入日志的消息以及恢复过来的partitions重新生成的消息,更新状态到S’阶段。这种方式通过只对丢失的partitions进行重新计算节省了在恢复时消耗的计算资源,同时由于每个worker只需要恢复很少的partitions,减少了恢复时的延迟。对发送出去的消息进行保存会产生一定的开销,但是通常机器上的磁盘带宽不会让这种IO操作成为瓶颈。
Confined recovery要求用户算法是确定性的,以避免原始执行过程中所保存下的消息与恢复时产生的新消息并存情况下带来的不一致。随机化算法可以通过基于超级步和partition产生一个伪随机数生成器来使之确定化。非确定性算法需要关闭Confined recovery而使用老的恢复机制。
4.3 Worker implementation
一个worker机器会在内存中维护分配到其之上的graph partition的状态。概念上讲,可以简单地看做是一个从顶点ID到顶点状态的Map,其中顶点状态包括如下信息:该顶点的当前值,一个以该顶点为起点的出边(包括目标顶点ID,边本身的值)列表,一个保存了接收到的消息的队列,以及一个记录当前是否active的标志位。该worker在每个超级步中,会循环遍历所有顶点,并调用每个顶点的Compute()函数,传给该函数顶点的当前值,一个接收到的消息的迭代器和一个出边的迭代器。这里没有对入边的访问,原因是每一条入边其实都是其源顶点的所有出边的一部分,通常在另外的机器上。
出于性能的考虑,标志顶点是否为active的标志位是和输入消息队列分开保存的。另外,只保存了一份顶点值和边值,但有两份顶点active flag和输入消息队列存在,一份是用于当前超级步,另一个用于下一个超级步。当一个worker在进行超级步S的顶点处理时,同时还会有另外一个线程负责接收从处于同一个超级步的其他worker接收消息。由于顶点当前需要的是S-1超级步的消息,那么对superstep S和superstep S+1的消息就必须分开保存。类似的,顶点V接收到了消息表示V将会在下一个超级步中处于active,而不是当前这一次。
当Compute()请求发送一个消息到其他顶点时,worker首先确认目标顶点是属于远程的worker机器,还是当前worker。如果是在远程的worker机器上,那么消息就会被缓存,当缓存大小达到一个阈值,最大的那些缓存数据将会被异步地flush出去,作为单独的一个网络消息传输到目标worker。如果是在当前worker,那么就可以做相应的优化:消息就会直接被放到目标顶点的输入消息队列中。
如果用户提供了Combiner,那么在消息被加入到输出队列或者到达输入队列时,会执行combiner函数。后一种情况并不会节省网络开销,但是会节省用于消息存储的空间。
4.4 Master implementation
Master主要负责的worker之间的工作协调,每一个worker在其注册到master的时候会被分配一个唯一的ID。Master内部维护着一个当前活动的worker列表,该列表中就包括每个worker的ID和地址信息,以及哪些worker被分配到了整个图的哪一部分。Master中保存这些信息的数据结构大小与partitions的个数相关,与图中的顶点和边的数目无关。因此,虽然只有一台master,也足够用来协调对一个非常大的图的计算工作。
绝大部分的master的工作,包括输入 ,输出,计算,保存以及从 checkpoint中恢复,都将会在一个叫做barriers的地方终止:Master在每一次操作时都会发送相同的指令到所有的活着的worker,然后等待从每个worker的响应。如果任何一个worker失败了,master便进入4.2节中描述的恢复模式。如果barrier同步成功,master便会进入下一个处理阶段,例如master增加超级步的index,并进入下一个超级步的执行。
Master同时还保存着整个计算过程以及整个graph的状态的统计数据,如图的总大小,关于出度分布的柱状图,处于active状态的顶点个数,在当前超级步的时间信息和消息流量,以及所有用户自定义aggregators的值等。为方便用户监控,Master在内部运行了一个HTTP服务器来显示这些信息。
4.5 Aggregators
每个Aggregator(见3.3节)会通过对一组value值集合应用aggregation函数计算出一个全局值。每一个worker都保存了一个aggregators的实例集,由type name和实例名称来标识。当一个worker对graph的某一个partition执行一个超级步时,worker会combine所有的提供给本地的那个aggregator实例的值到一个local value:即利用一个aggregator对当前partition中包含的所有顶点值进行局部规约。在超级步结束时,所有workers会将所有包含局部规约值的aggregators的值进行最后的汇总,并汇报给master。这个过程是由所有worker构造出一棵规约树而不是顺序的通过流水线的方式来规约,这样做的原因是为了并行化规约时cpu的使用。在下一个超级步开始时,master就会将aggregators的全局值发送给每一个worker。
5.Applications
本节包含四个例子,它们是由Pregel用户开发地用来解决如下实际问题的简化版算法:PageRank,最短路径,二分图匹配和Semi-Clustering算法。
5.1 PageRank
{!首先来简要介绍下PageRank算法:将文献检索中的引用理论用到Web中,引用网页的链接数一定程度上反映了该网页的重要性和质量。PageRank发展了这种思想,网页间的链接是不平等的。PageRank定义如下: 我们假设T1…Tn指向网页A(例如,被引用)。参数d是制动因子,取值在0,1之间。通常d等于0.85。网页A的PageRank值由下式给出:
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))。
PageRank或PR(A)可以用简单的迭代算法计算,计算过程是收敛的,随着迭代次数的增加,各网页的PageRank值趋于平稳。可以从如下角度进行理解:
1.
假设网上冲浪是随机的,不断点击链接,从不返回,最终烦了,另外随机选一个网页重新开始冲浪。随机访问一个网页的可能性就是它的PageRank值。制动因子d是随机访问一个网页烦了的可能性,随机另选一个网页。对单个网页或一组网页,一个重要的变量加入到制动因子d中。这允许个人可以故意地误导系统,以得到较高的PageRank值。
2.
直觉上判断,一个网页有很多网页指向它,或者一些PageRank值高的网页指向它,则这个网页很重要。直觉地,在Web中,一个网页被很多网页引用,那么这个网页值得一看。一个网页被象Yahoo这样重要的主页引用即使一次,也值得一看。如果一个网页的质量不高,或者是死链接,象Yahoo这样的主页不会链向它。PageRank处理了这两方面因素,并通过网络链接递归地传递。
关于该公式需要说明的是,Google后来调整时使用了1-d/N,公式的其他部分未作任何变动,这里的N是互联网中全部的网页数量,也就是本论文中使用的公式,据说这样做使得PageRank变为了被随机访问的期望值。关于PageRank更具体的解释可以参考这篇文章: 数据挖掘10大算法(1):PageRank。
}
PageRank算法[7]的Pregel实现如图4所示。PageRankVertex继承自Vertex类。顶点value类型是double,用来保存PageRank中间值,消息类型也是double,用来传输PageRank分数,边的value类型是void,因为不需要存储任何信息。我们假设,在第0个超级步时,图中各顶点的value值被初始化为1/NumVertices()。在前30个超级步中,每个顶点都会沿着它的出边发送它的PageRank值除以出边数后的结果值。从第1个超级步开始,每个顶点会将到达的消息中的值加到sum值中,同时将它的PageRank值设为0.15/ NumVertices()+0.85*sum。到了第30个超级步后,就没有需要发送的消息了,同时所有的顶点VoteToHalt。在实际中,PageRank算法需要一直运行直到收敛,可以使用aggregators来检查是否满足收敛条件。

最短路径问题是图论中最有名的问题之一了,同时具有广泛的应用[10,24],该问题有几个形式:单源最短路径,是指要找出从某个源顶点到其他所有顶点的最短路径;s-t最短路径,是指要找出给定源顶点s和目标顶点t间的最短路径,这个问题具有广泛的实验应用比如寻找驾驶路线,并引起了广泛关注,同时它也是相对简单的;全局最短路径,对于大规模的图对象来说通常都不太实际,因为它的空间复杂度是O(V*V)的。为简化起见,我们这里以非常适于用Pregel解决的单源最短路径为例,实现代码见图5。

该算法中的消息保存都是潜在的最小距离。由于接收顶点实际上只关注最小值,因此该算法是可以通过combiner进行优化的,combiner实现如图6所示,它可以大大减少worker间的消息量,以及在执行下一个超级步前所需要缓存的数据量。图5中的实现只是计算出了最短距离,如果要计算最短路径生成树也是很简单的。

5.3二分匹配
二分匹配算法的输入由两个不同的顶点集合组成,所有边的两顶点分别位于两个集合中,输出是边的一个子集,它们之间没有公共顶点。极大匹配(Maximal Matching)是指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配的边数。我们实现了一个随机化的极大匹配算法[1],以及一个最大权匹配算法[4];我们只在此描述下前者。
在该算法的Pregel实现中,顶点的关联值是由两个值组成的元组(tuple):一个是用于标识该顶点所处集合(L or R)的flag,一个是跟它所匹配的顶点名称。边的关联值类型为void,消息的类型为boolean。该算法是由四个阶段组成的多个循环组成,用来标识当前所处阶段的index可以通过用当前超级步的index mod 4得到。
在循环的阶段0,左边集合中那些还未被匹配的顶点会发送消息给它的每个邻居请求匹配,然后会无条件的VoteToHalt。如果它没有发送消息(可能是因为它已经找到了匹配,或者没有出边),或者是所有的消息接收者都已经被匹配,该顶点就不会再变为active状态。
在循环的阶段1,右边集合中那些还未被匹配的顶点随机选择它接收到的消息中的其中一个,并发送消息表示接受该请求,然后给其他请求者发送拒绝消息。然后,它也无条件的VoteToHalt。
在循环的阶段2,左边集合中那些还未被匹配的顶点选择它所收到右边集合发送过来的接受请求中的其中一个,并发送一个确认消息。左边集合中那些已经匹配好的顶点永远都不会执行这个阶段,因为它们不会在阶段0发送任何消息。
最后,在阶段3,右边集合中还未被匹配的顶点最多会收到一个确认消息。它会通知匹配顶点,然后无条件的VoteToHalt,它的工作已经完成。
5.4 Semi-Clustering
。
6. 实验结果
我们使用5.2节描述的单源最短路径(SSSP)实现在一个由300台多核PC组成的集群上进行了多次实验。得到了在所有边的权重为1情况下,针对不同大小规模下的二叉树(为了研究可扩展属性)和对数正态随机图(为了研究更接近真实环境下的性能)的运行时间。
测量结果没有包含用于初始化集群,在内存中生成测试图以及进行结果验证的时间。因为所有的实验运行的时间都相对比较短,因此出错的概率比较低,同时关闭了checkpointing。
图7展示了一个具有十亿个顶点(由于是树,故边数应为十亿-1)的二叉树最短路径算法的在Pregel worker数目从50到800之间的情况下的运行时间。通过该图可以看出Pregel伴随着worker数增加的扩展性。可以看到运行时间从170秒降到了17.3秒,相当于使用16倍的worker数获得了大概10倍的加速。


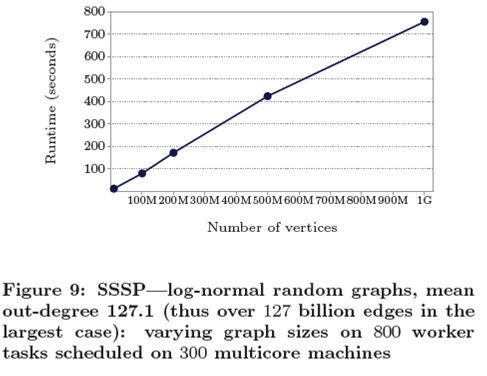
前面的实验只是展示了Pregel随着worker数目和图大小增加的情况下的可扩展性,但是二叉树很明显无法代表实际中经常碰到的那些图。因此我们需要继续实验,通过使用一个出度具有对数正态分布的随机生成的图来进行,同时我们令μ=4,σ=1.3,此时的平均出度为127.1。这个分布与很多现实中的大型图都很类似,比如web graph或者是社交网络,在这些情况下,大多数顶点的度都相对较小,但是存在少数的一些顶点的度非常大—可能成千上万甚至更多。

7. 相关工作
Pregel是一个分布式编程框架,专注于为用户编写图算法提供自然的API,同时将消息机制和容错等底层分布式细节隐藏起来。从概念上看,它非常类似于MapReduce[14],但是具有更自然的面前图的API和更高效的在图上进行迭代计算的支持。由于专注于图对象使得它与其他的一些分布式框架比如Sawzall[41],Pig Latin[40],Drayad[27,47]区别开来。Pregel之所以不同,还因为它实现了一个有状态的模型,在这个模型中进程会一直存活着,不断地进行计算,通信和修改本地状态等等,这与数据流模型不同,在数据流模型中进程只是在输入数据上进行计算,然后产生输出数据再交由其他进程处理。
Pregel借鉴了BSP模型的思想,比如它里面的由计算和通信组成的超级步概念。目前已经存在大量的普通BSP库实现,比如Oxford BSP[38],GreenBSP[21],BSPlib[26]和Paderborn University BSP Library[6]。这些库本身在提供的通信原语,处理分布式环境下的问题(比如容错)的方式,负载平衡等方面都有些不同。据我们所知,这些BSP实现都是只在几十台机器上运行过,可扩展性和容错性都比较有限,同时都没有提供一个面向图处理的API。
跟Pregel最接近的应该算是Parallel Boot Graph Library和CGMGraph了。Parallel BGL[22,23]为分布式的图定义了一些关键概念,提供了一个基于MPI[18]的实现,同时基于此实现了大量的图算法。并试图维护与BGL(串行的)[43]的兼容性,以方便算法的移植。它内部实现采用一个property map来存储与图的顶点和边相关的信息,采用ghost cells存放与远程组件相关的值。在具有很多远程组件时这会影响可扩展性。Pregel使用了一种显式的消息机制来获取远程信息,同时不会将这些值存放在本地。最关键的区别是Pregel提供了容错机制来处理计算环境中发生的故障,这就使得它可以部署在一个很大的集群环境中,在这种规模的集群中故障是很常见的,比如硬件产生了故障或者高优先级的作业发生了资源抢占。
CGMGraph[8]在概念上非常类似于Pregel,它通过基于MPI的CGM(Coarse Grained Multicomputer)模型提供了大量并行图算法实现。它暴露给用户更多的底层分布式机制,更关注于提供图算法实现而不是提供一个实现这些算法的基础设施。CGMGraph使用了面向对象的编程风格,与Parallel BGL和Pregel的泛型编程风格相比,会有一些性能损失。
除了Pregel和Parallel BGL之外,基本没有其他系统提供过在billions这个规模的顶点数的实验结果。目前已发表的最大规模的实验结果来自于一个针对s-t最短路径的定制化实现,而不是来自通用框架。Yoo 等[46]发表的广度优先搜索实现(s-t最短路径)在BlueGene/L上的实现,是运行在32786个PowerPC处理器上,同时采用了高性能torus网络,对于一个具有3.2B个顶点和32B 条边满足泊松分布的随机图的处理用了1.5秒。Bader和Madduri[2]发表了该类似问题在一个10节点Cray MTA-2上的结果,对于一个具有134M个顶点和805M条边的R-MAT随机图的处理用了0.43秒。Lumsadaine等[31]用在一个具有200个处理器的x86-64 Opteron集群上的Parallel BGL结果,与BlueGene/L实现进行了对比,对于一个具有4B个顶点和20B条边的Erdos-Renyi随机图的处理用了0.43秒。
对于一个具有256M个顶点和平均出度为4的Erdos-Renyi随机图的上的单源最短路径问题来说,在使用△-stepping算法的情况下,结果如下:Cray MTA-2(40个处理器,2.37秒,[32]),在Opterons上的Parallel BGL(112个处理器,35秒,[31])。后面的这个时间比较接近于我们针对1B顶点和边的规模在400个worker上的结果。我们还没有任何其他的在1B顶点和127.1B边这个规模上的log-normal随机图上的相关结果。
另外的一个研究方向是在单台机器上通过扩展内存磁盘来处理更大规模的问题,比如[33,36]。但是这些实现,对于1B个顶点的规模的图的处理要花几个小时。
8. 总结以及未来的工作
本文的贡献是提出了一个适用于大规模图计算的模型,并描述了它的高质量的,可扩展的,容错实现。
来自用户的数据显示,我们已经成功地让该模型被使用起来,并具有了不错的可用性。目前已经有很多Pregel应用被部署,同时还要更多地处于设计和实现的过程中。用户反映当它们将思维方式成功转换到”think like a vertex”后,发现提供的API是如此直观,灵活,太好用了。这并不令人吃惊,因为我们从一开始就是跟早期用户一起做这项工作的,从那时起他们就影响着这些API的设计了。比如,aggregators之所以被支持就是为了解决用户在早期Pregel模型发现的一些限制。此外还有其他的关于Pregel可用性方面的改进都是源自用户的使用经验,比如关于Pregel程序执行过程的详细信息的状态页面,unittesting框架,以及用来帮助用户进行快速原型开发和debug的单机运行模式。
Pregel已经在性能,可扩展性和容错方面满足了具有billios规模的边的图的处理。同时我们也在继续进行调研以扩展到更大的规模,比如放松模型的同步性,避免让那些运行的快的worker总是等待在超级步之间。
当前整个的计算状态都是驻留在内存中的。我们已经开始将一些数据存到本地磁盘,同时我们会继续在这个方向进行深入的研究,希望可以支持规模太大以至于内存无法完全存下的情况。
通过调整顶点在机器间的分配以最小化机器间的通信开销非常具有挑战性。根据图的拓扑结构对输入进行划分有时可能行地通,有时可能不行,图的拓扑结构可能会动态地发生改变。我们希望可以引入动态的re-parttioning机制。
Pregel是为那种通信主要发送在边上的稀疏图设计的,我们会一直坚持这个假设。尽管我们已经投入一些经历用于支持高的消息收发流量的情况,但是当大部分的顶点都在持续地向大部分的其他顶点发送消息时,性能问题会变得很严重。当然了,实际中dense的图还是很少的,同时需要在稀疏图上进行dense通信的算法也是很少发生的。对于这样的算法来说,其中一些可以转换成Pregel能够比较好的支持的变种,比如通过使用combiners,aggregators或者拓扑变更,当然了这样的计算对于任何高度分布式的系统来说都会是很难的。
需要注意的一点是,Pregel已经正成为我们的基础设施的一部分。现在已经不能随意地去修改API而不考虑兼容性了。但是,我们相信现有的编程接口已经是足够抽象和灵活了,足以应对底层系统未来的演化。
9. 致谢
We thank Pregel's very early users--Lorenz Huelsbergen,Galina Shubina,Zoltan Gyongyi--for their contributions to the model. Discussions with Adnan Aziz,Yossi Matias,and Steffen Meschkat helped refine several aspects of Pregel. Our interns, Punyashloka Biswal and Petar Maymounkov, provided initial evidence of Pregel's applicability to matchings and clustering, and Charles Reiss automated checkpointing
decisions. The paper benefited from comments on its earlier drafts from Jeff Dean, Tushar Chandra, Luiz Barroso, Urs Holzle, Robert Henry, Marian Dvorsky, and the anonymous reviewers. Sierra Michels-Slettvet advertised Pregel to various teams within Google computing over interesting but less known graphs. Finally, we thank all the users of Pregel for feedback and many great ideas.
参考文献
[1] Thomas Anderson, Susan Owicki, James Saxe, and Charles Thacker, High-Speed Switch Scheduling for Local-Area Networks. ACM Trans. Comp. Syst. 11(4),1993, 319{352.
[2] David A. Bader and Kamesh Madduri, Designing multithreaded algorithms for breadth-_rst search and st-connectivity on the Cray MTA-2, in Proc. 35th Intl. Conf. on Parallel Processing (ICPP'06), Columbus,OH, August 2006, 523|530.
[3] Luiz Barroso, Je_rey Dean, and Urs Hoelzle, Web search for a planet: The Google Cluster Architecture.IEEE Micro 23(2), 2003, 22{28.
[4] Mohsen Bayati, Devavrat Shah, and Mayank Sharma, Maximum Weight Matching via Max-Product Belief Propagation. in Proc. IEEE Intl. Symp. On Information Theory, 2005, 1763{1767.
[5] Richard Bellman, On a routing problem. Quarterly of Applied Mathematics 16(1), 1958, 87{90.
[6] Olaf Bonorden, Ben H.H. Juurlink, Ingo von Otte, andIngo Rieping, The Paderborn University BSP (PUB) Library. Parallel Computing 29(2), 2003, 187{207.
[7] Sergey Brin and Lawrence Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine. in Proc.7th Intl. Conf. on the World Wide Web, 1998,107{117.
[8] Albert Chan and Frank Dehne,CGMGRAPH/CGMLIB: Implementing and Testing CGM Graph Algorithms on PC Clusters and Shared Memory Machines. Intl. J. of High Performance Computing Applications 19(1), 2005, 81{97.
[9] Fay Chang, Je_rey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber, Bigtable:A Distributed Storage System for Structured Data. ACM Trans. Comp. Syst. 26(2), Art. 4, 2008.
[10] Boris V. Cherkassky, Andrew V. Goldberg, and Tomasz Radzik, Shortest paths algorithms: Theory and experimental evaluation. Mathematical Programming 73, 1996, 129{174.
[11] Jonathan Cohen, Graph Twiddling in a MapReduce World. Comp. in Science & Engineering, July/August 2009, 29{41.
[12] Joseph R. Crobak, Jonathan W. Berry, Kamesh Madduri, and David A. Bader, Advanced Shortest Paths Algorithms on a Massively-Multithreaded Architecture. in Proc. First Workshop on Multithreaded Architectures and Applications, 2007,1{8.
[13] John T. Daly, A higher order estimate of the optimum checkpoint interval for restart dumps. Future Generation Computer Systems 22, 2006, 303{312.
[14] Je_rey Dean and Sanjay Ghemawat, MapReduce:Simpli_ed Data Processing on Large Clusters. in Proc.6th USENIX Symp. on Operating Syst. Design and Impl., 2004, 137{150.
[15] Edsger W. Dijkstra, A Note on Two Problems in Connexion with Graphs. Numerische Mathematik 1,1959, 269{271.
[16] Martin Erwig, Inductive Graphs and Functional Graph Algorithms. J. Functional Programming 1(5), 2001,467{492.
[17] Lester R. Ford, L. R. and Delbert R. Fulkerson, Flows in Networks. Princeton University Press, 1962.
[18] Ian Foster and Carl Kesselman (Eds), The Grid 2:Blueprint for a New Computing Infrastructure (2nd edition). Morgan Kaufmann, 2003.
[19] Sanjay Ghemawat, Howard Gobio_, and Shun-Tak Leung, The Google File System. in Proc. 19th ACM Symp. on Operating Syst. Principles, 2003, 29{43.
[20] Michael T. Goodrich and Roberto Tamassia, Data Structures and Algorithms in JAVA. (second edition).John Wiley and Sons, Inc., 2001.
[21] Mark W. Goudreau, Kevin Lang, Satish B. Rao,Torsten Suel, and Thanasis Tsantilas, Portable and E_cient Parallel Computing Using the BSP Model.IEEE Trans. Comp. 48(7), 1999, 670
[22] Douglas Gregor and Andrew Lumsdaine, The Parallel BGL: A Generic Library for Distributed Graph Computations. Proc. of Parallel Object-Oriented Scienti_c Computing (POOSC), July 2005.
[23] Douglas Gregor and Andrew Lumsdaine, Lifting Sequential Graph Algorithms for Distributed-Memory Parallel Computation. in Proc. 2005 ACM SIGPLAN Conf. on Object-Oriented Prog., Syst., Lang., and Applications (OOPSLA'05), October 2005, 423{437.
[24] Jonathan L. Gross and Jay Yellen, Graph Theory and Its Applications. (2nd Edition). Chapman and Hall/CRC, 2005.
[25] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart, Exploring network structure, dynamics, and function using NetworkX. in Proc. 7th Python in Science Conf., 2008, 11{15.
[26] Jonathan Hill, Bill McColl, Dan Stefanescu, Mark Goudreau, Kevin Lang, Satish Rao, Torsten Suel,Thanasis Tsantilas, and Rob Bisseling, BSPlib: The BSP Programming Library. Parallel Computing 24,1998, 1947.
[27] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell,and Dennis Fetterly, Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. in Proc.European Conf. on Computer Syst., 2007, 59.
[28] Paris C. Kanellakis and Alexander A. Shvartsman,Fault-Tolerant Parallel Computation. Kluwer Academic Publishers, 1997.
[29] Donald E. Knuth, Stanford GraphBase: A Platform for Combinatorial Computing. ACM Press, 1994.
[30] U Kung, Charalampos E. Tsourakakis, and Christos Faloutsos, Pegasus: A Peta-Scale Graph Mining System - Implementation and Observations. Proc. Intl.Conf. Data Mining, 2009, 229-238.
[31] Andrew Lumsdaine, Douglas Gregor, Bruce Hendrickson, and Jonathan W. Berry, Challenges in Parallel Graph Processing. Parallel Processing Letters 17, 2007, 5
[32] Kamesh Madduri, David A. Bader, Jonathan W.Berry, and Joseph R. Crobak, Parallel Shortest Path Algorithms for Solving Large-Scale Graph Instances.DIMACS Implementation Challenge { The Shortest Path Problem, 2006.
[33] Kamesh Madduri, David Ediger, Karl Jiang, David A.Bader, and Daniel Chavarria-Miranda, A Faster Parallel Algorithm and E_cient Multithreaded Implementation for Evaluating Betweenness Centrality on Massive Datasets, in Proc. 3rd Workshop on Multithreaded Architectures and Applications (MTAAP'09), Rome, Italy, May 2009.
[34] Grzegorz Malewicz, A Work-Optimal Deterministic Algorithm for the Certi_ed Write-All Problem with a Nontrivial Number of Asynchronous Processors. SIAM J. Comput. 34(4), 2005, 993
[35] Kurt Mehlhorn and Stefan Naher, The LEDA Platform of Combinatorial and Geometric Computing.Cambridge University Press, 1999.
[36] Ulrich Meyer and Vitaly Osipov, Design and Implementation of a Practical I/O-e_cient Shortest Paths Algorithm. in Proc. 3rd Workshop on Multithreaded Architectures and Applications (MTAAP'09), Rome, Italy, May 2009.
[37] Ulrich Meyer and Peter Sanders, _-stepping: A Parallelizable Shortest Path Algorithm. J. Algorithms 49(1), 2003, 114
[38] Richard Miller, A Library for Bulk-Synchronous Parallel Programming. in Proc. British Computer Society Parallel Processing Specialist Group Workshop on General Purpose Parallel Computing, 1993.
[39] Kameshwar Munagala and Abhiram Ranade, I/O-complexity of graph algorithms. in Proc. 10th Annual ACM-SIAM Symp. on Discrete Algorithms,1999, 687
[40] Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, and Andrew Tomkins, Pig Latin: A Not-So-Foreign Language for Data Processing. in Proc. ACM SIGMOD Intl. Conf. on Management of Data, 2008, 1099
[41] Rob Pike, Sean Dorward, Robert Griesemer, and Sean Quinlan, Interpreting the Data: Parallel Analysis with Sawzall. Scienti_c Programming Journal 13(4), Special Issue on Grids and Worldwide Computing Programming Models and Infrastructure, 2005,227
[42] Protocol Bu_ers|Google's data interchange format.http://code.google.com/p/protobuf/ 2009.
[43] Jeremy G. Siek, Lie-Quan Lee, and Andrew Lumsdaine, The Boost Graph Library: User Guide and Reference Manual. Addison Wesley, 2002.
[44] Mikkel Thorup, Undirected Single-Source Shortest Paths with Positive Integer Weights in Linear Time.J. ACM 46(3), May 1999, 362
[45] Leslie G. Valiant, A Bridging Model for Parallel Computation. Comm. ACM 33(8), 1990, 103
[46] Andy Yoo, Edmond Chow, Keith Henderson, William McLendon, Bruce Hendrickson, and Umit Catalyurek,A Scalable Distributed Parallel Breadth-First Search Algorithm on BlueGene/L, in Proc. 2005 ACM/IEEE Conf. on Supercomputing (SC'05), 2005, 25|43.
[47] Yuan Yu, Michael Isard, Dennis Fetterly, Mihai Budiu,Ulfar Erlingsson, Pradeep Kumar Gunda, and Jon Currey, DryadLINQ: A System for General-Purpose Distributed Data-Parallel Computing Using a High-Level Language. in Proc. 8th USENIX Symp. On Operating Syst. Design and Implementation, 2008,
Pregel: A System for Large-Scale Graph Processing(zz)