边学边记(四) lunene index结构一
lucene的索引文件信息主要包括 段(segment),文档(document),域(field),项(term)
说到lucene的索引存储的存储结构,堪称精妙。lucene给出的存储的数据类型有以下几种
- Primitive Types
- Byte
- UInt32
- Uint64
- VInt
- Chars
- String
bype就是一个字节8位二进制,对于lucene中的数字的存储,先看java中的两种整数类型 int long
一个int的数值的范围是-231 到 231 -1 对应lucene中的UInt32
一个long型的数值的范围是-263 到 263 -1 对应lucene中的UInt64
VINT 类型lucene给出了定义是一个可变长度的byte组合来表示一个正整数
VInt lucene给出了一个例子表格
| Value |
First byte |
Second byte |
Third byte |
| 0 |
00000000 |
|
|
| 1 |
00000001 |
|
|
| 2 |
00000010 |
|
|
| ... |
|
|
|
| 127 |
01111111 |
|
|
| 128 |
10000000 |
00000001 |
|
| 129 |
10000001 |
00000001 |
|
| 130 |
10000010 |
00000001 |
|
| ... |
|
|
|
| 16,383 |
11111111 |
01111111 |
|
| 16,384 |
10000000 |
10000000 |
00000001 |
| 16,385 |
10000001 |
10000000 |
00000001 |
看表格里德数据意思就是一个byte 表示0-127的整数 如果次数<=127那么只占用一个byte,如果>127则会追加byte来存储此整数的值,那么第一个byte和第二个byte的关系和规则是什么呢 看表格中的表示形式貌似是如果此byte不够表示的话那么将当前byte的二进制中的头位变1,这样一来就没有符号位的表示了,首位0说明只有一个byte首位1则说明后续还有byte来存储此数字。看看lucene的代码中是如果来存储一个int数字为一个VInt类型的可变的byte的吧
/** Writes an int in a variable-length format. Writes between one and * five bytes. Smaller values take fewer bytes. Negative numbers are not * supported. * @see IndexInput#readVInt() */ public void writeVInt(int i) throws IOException { while ((i & ~0x7F) != 0) { writeByte((byte)((i & 0x7f) | 0x80)); i >>>= 7; } writeByte((byte)i); }
首先~0x7F的二进制表示是
11111111 11111111 11111111 10000000
一个正整数如果<127的话和此值进行逻辑与操作的话都是0 这样就只写入一个byte
在看大数的情况下是如果确定第一个byte的值的 就拿128来说吧
0x7F的 和0x80的二进制表示形式
0x7F的二进制如下:
00000000 00000000 00000000 01111111 就是~0x7F的补码
0x80的二进制如下:
00000000 00000000 00000000 10000000
128 & 0x7F
00000000 00000000 00000000 10000000 &
00000000 00000000 00000000 01111111
= 00000000 00000000 00000000 00000000 |
00000000 00000000 00000000 10000000
= 00000000 00000000 00000000 10000000
和列表中给出的值是一样的 强转为byte的话取低8位写入
然后带符号位右移7位舍掉前7位 将1写入
按照这个逻辑0-127只有一位 128-255 一位只有低8位表示 所以经过第二次右移以后第二个byte始终都是00000001 以此类推 256 -
27*2 - 1 只有两位byte。。。。。。
看看这样移位以后再读取的时候lucene的反向移位运算代码:
/** Reads an int stored in variable-length format. Reads between one and * five bytes. Smaller values take fewer bytes. Negative numbers are not * supported. * @see IndexOutput#writeVInt(int) */ public int readVInt() throws IOException { byte b = readByte(); int i = b & 0x7F; for (int shift = 7; (b & 0x80) != 0; shift += 7) { b = readByte(); i |= (b & 0x7F) << shift; } return i; }
反向运算中先于0x7F取与 如果<=127那么次操作过后i的值就等于b的值 直接返回 如果>127 则i的值只是b的低7位不涉及符号位这时进入循环将第二个byte取出还是去掉符号位(和0x7F取于的话就是去掉符号位的低7位)就是正向操作里头一次将高位付给第一个byte以后的值
高位在左移7 14 21.。。。就可以返回原来的高位 在和i进行或操作 就对高位和低位进行了合并操作以此类推 返回原值
这个的存储就有点麻烦 线比较两外两种存储数字的类型就比较容易 UInt32 UInt64分别固定保存为4个byte和8个byte 和vint不同的是这两种类型可以保存负数
这个逻辑比较简单有兴趣的可以二进制计算下以下是lucene中写入和读取两种数据类型的源码
写入一个UInt32的数据 (int 类型)
/** Writes an int as four bytes. * @see IndexInput#readInt() */ public void writeInt(int i) throws IOException { writeByte((byte)(i >> 24)); writeByte((byte)(i >> 16)); writeByte((byte)(i >> 8)); writeByte((byte) i); }
写入一个UInt64(long类型)
/** Writes a long as eight bytes. * @see IndexInput#readLong() */ public void writeLong(long i) throws IOException { writeInt((int) (i >> 32)); writeInt((int) i); }
读取的时候就是反向移位在进行或运算
读取UInt32
/** Reads four bytes and returns an int. * @see IndexOutput#writeInt(int) */ public int readInt() throws IOException { return ((readByte() & 0xFF) << 24) | ((readByte() & 0xFF) << 16) | ((readByte() & 0xFF) << 8) | (readByte() & 0xFF); }
读取UInt64
/** Reads eight bytes and returns a long. * @see IndexOutput#writeLong(long) */ public long readLong() throws IOException { return (((long)readInt()) << 32) | (readInt() & 0xFFFFFFFFL); }
这两种类型的数据相对比较简单就不在分析正向反向的移位运算和逻辑运算了
这样对数字存储的话有效地控制了数字类型的数据占用的索引文件的容量
举个例子加入将数字作为字符串写入磁盘的话 一位数字就是一个byte
0就占一个byte 127就占三个byte 100000 就占6个byte 一个最大的整数231 -1 = 2147483647 就需要10个byte 数字位数越多byte数就越多
而按照lucene的这三个数字类型的话 VInt是可变的 根据数字的大小使用不同的byte数目
相应的UInt32 和UInt64也一样 固定需要4个byte和8个byte
有了这几个类型数据的存储和读取方法我们就可以读取lucene的file format中说明的segment.gen文件了读取的函数直接继承lucene的org.apache.lucene.store.BufferedIndexInput类作为lucene索引文件的读取类 只要将其中的byte能翻译成我们想要的结果 自然就知道里面存的是什么值怎么存储了。
lucene3.0以前的版本没用过,在3.0中lucene创建索引的时候默认使用混合文件模式 文件只有cfx,cfs,gen,segments_N文件 如果做过删除操作的话应该还有.del的文件 其他的文件类型.tvd,.tvx等什么时候出现现在我还不晓得。
先创建包含一两个document的索引文件(不使用混合文件模式)
/**************** * *Create Class:CreateIndex.java *Author:a276202460 *Create at:2010-6-1 */ package com.rich.lucene.index; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class CreateIndex { /** * @param args * @throws IOException * @throws CorruptIndexException */ public static void main(String[] args) throws CorruptIndexException, IOException { String indexdir = "D:/lucenetest/indexs/txtindex/index4"; Directory indexdirectory = FSDirectory.open(new File(indexdir)); Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30); IndexWriter writer = null; try { writer = new IndexWriter(indexdirectory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); writer.addDocument(getDocument("http://www.baidu.com", "百度搜索", "百度搜索引擎,国内最大的搜索引擎")); writer.addDocument(getDocument("http://www.g.cn", "谷歌搜索", "全球做大的搜索引擎")); writer.optimize(); } finally { writer.close(); } } public static Document getDocument(String url, String title, String content) { Document doc = new Document(); doc.add(new Field("title", title, Field.Store.YES, Field.Index.ANALYZED)); doc.add(new Field("url", url, Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("content", content, Field.Store.NO, Field.Index.ANALYZED)); return doc; } }
索引创建完成后文件结构如下:
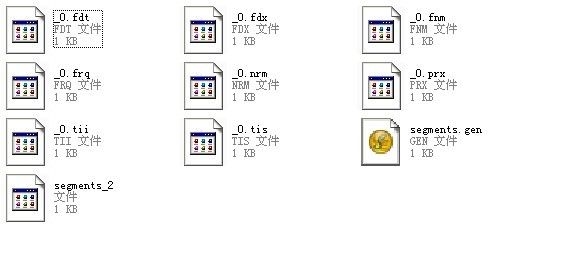
lucene的索引文件读取类IndexFileInput:
/**************** * *Create Class:IndexFileInput.java *Author:a276202460 *Create at:2010-6-1 */ package com.rich.lucene.io; import java.io.IOException; import java.io.RandomAccessFile; import org.apache.lucene.store.BufferedIndexInput; public class IndexFileInput extends BufferedIndexInput { private final IndexFile file; boolean isClone; public IndexFileInput(String filepath) throws Exception{ super(); file = new IndexFile(filepath,"r"); } protected void readInternal(byte[] b, int offset, int length) throws IOException { synchronized(file){ long position = this.getFilePointer(); if(position != file.position){ file.seek(position); file.position = position; } int total = 0; do{ int readlength = length - total; final int i = file.read(b, offset+total, readlength); if(i == -1){ throw new IOException("read past EOF"); } total += i; }while(total < length); } } protected void seekInternal(long pos) throws IOException { } public void close() throws IOException { if(!isClone) file.close(); } public long length() { return file.length; } public Object Clone(){ IndexFileInput input = (IndexFileInput)super.clone(); input.isClone = true; return input; } } class IndexFile extends RandomAccessFile{ protected volatile boolean isOpen; long position; final long length; public IndexFile(String name, String mode) throws Exception { super(name, mode); isOpen = true; length = this.length(); } public void close() throws IOException { if (isOpen) { isOpen=false; super.close(); } } }
lucene的文档中对segments.gen文件的解释是这样的
As of 2.1, there is also a file segments.gen . This file contains the current generation (the _N in segments_N ) of the index. This is used only as a fallback in case the current generation cannot be accurately determined by directory listing alone (as is the case for some NFS clients with time-based directory cache expiraation). This file simply contains an Int32 version header (SegmentInfos.FORMAT_LOCKLESS = -2), followed by the generation recorded as Int64, written twice
其中就只存了两项 一个是Int32 version header 一个是段信息文件中的the _N in segments_N
按照存储的内容此文件只有20个byte 用IndexFileInput来读取这个文件看看里面存储的什么信息
/**************** * *Create Class:Segmentread.java *Author:a276202460 *Create at:2010-6-1 */ package com.rich.lucene.io; public class Segmentread { /** * @param args * @throws Exception */ public static void main(String[] args) throws Exception { String segmentpath = "D:/lucenetest/indexs/txtindex/index4/segments.gen"; IndexFileInput input = new IndexFileInput(segmentpath); int length = (int)input.length(); System.out.println("segments.gen文件存储的byte数目为:"+length); for(int i = 0;i < length;i++ ){ System.out.print(input.readByte()+" "); } System.out.println(); input.seek(0); System.out.println(input.readInt()); System.out.println(input.readLong()); System.out.println(input.readLong()); input.close(); } }
运行结果如下:
segments.gen文件存储的byte数目为:20
-1 -1 -1 -2 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 2
-2
2
2
存储的byte个数确实是20个按照lucene的及时 前4个byte存储的是一个UInt32的数字 后面存了两个8位的UInt64的数据