打开关闭网卡
| [root@linux ~]# ifup {interface} [root@linux ~]# ifdown {interface} [root@linux ~]# ifup eth0 |
ifup与ifdown真是太简单了。这两个程序其实是script而已,它会直接到 /etc/ sysconfig/network-scripts目录下搜索对应的配置文件,例如ifup eth0,它会找出ifcfg-eth0这个文件的内容,然后加以设置。关于ifcfg-eth0的设置请参考前一章连上Internet的说明。 不过,由于这两个程序主要是搜索设置文件(ifcfg-ethx)来进行启动与关闭的,所以在使用前请确定ifcfg-ethx是否真的存在于正确的目录内,否则会启动失败。另外,如果以ifconfig eth0来设置或者是修改了网络接口后,就无法再以ifdown eth0的方式来关闭了。因为ifdown会分析比较目前的网络参数与ifcfg-eth0是否相符,不符的话,就会放弃这次操作。因此,使用ifconfig修改完毕后,应该要以ifconfig eth0 down才能够关闭该接口。
linux查看多核负载(经典)
1. Linux下,如何看每个CPU的使用率:
#top -d 1
之后按下数字1. 则显示多个CPU (top后按1也一样)
Cpu0 : 1.0%us, 3.0%sy, 0.0%ni, 96.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
2. 在Linux下,如何确认是多核或多CPU:
#cat /proc/cpuinfo
如果有多个类似以下的项目,则为多核或多CPU:
processor : 0
......
processor : 1
3. 如何察看某个进程在哪个CPU上运行:
#top -d 1
之后按下f.进入top Current Fields设置页面:
选中:j: P = Last used cpu (SMP)
则多了一项:P 显示此进程使用哪个CPU。
Sam经过试验发现:同一个进程,在不同时刻,会使用不同CPU Core.这应该是Linux Kernel SMP处理的。
4. 配置Linux Kernel使之支持多Core:
内核配置期间必须启用 CONFIG_SMP 选项,以使内核感知 SMP。
Processor type and features ---> Symmetric multi-processing support
察看当前Linux Kernel是否支持(或者使用)SMP
#uname -a
5. Kernel 2.6的SMP负载平衡:
在 SMP 系统中创建任务时,这些任务都被放到一个给定的 CPU 运行队列中。通常来说,我们无法知道一个任务何时是短期存在的,何时需要长期运行。因此,最初任务到 CPU 的分配可能并不理想。
为了在 CPU 之间维护任务负载的均衡,任务可以重新进行分发:将任务从负载重的 CPU 上移动到负载轻的 CPU 上。Linux 2.6 版本的调度器使用负载均衡(load balancing) 提供了这种功能。每隔 200ms,处理器都会检查 CPU 的负载是否不均衡;如果不均衡,处理器就会在 CPU 之间进行一次任务均衡操作。
这个过程的一点负面影响是新 CPU 的缓存对于迁移过来的任务来说是冷的(需要将数据读入缓存中)。
记住 CPU 缓存是一个本地(片上)内存,提供了比系统内存更快的访问能力。如果一个任务是在某个 CPU 上执行的,与这个任务有关的数据都会被放到这个 CPU 的本地缓存中,这就称为热的。如果对于某个任务来说,CPU 的本地缓存中没有任何数据,那么这个缓存就称为冷的。
不幸的是,保持 CPU 繁忙会出现 CPU 缓存对于迁移过来的任务为冷的情况。
6. 应用程序如何利用多Core :
开发人员可将可并行的代码写入线程,而这些线程会被SMP操作系统安排并发运行。
另外,Sam设想,对于必须顺序执行的代码。可以将其分为多个节点,每个节点为一个thread.并在节点间放置channel.节点间形如流水线。这样也可以大大增强CPU利用率。
例如:
游戏可以分为3个节点。
1.接受外部信息,声称数据 (1ms)
2.利用数据,物理运算(3ms)
3.将物理运算的结果展示出来。(2ms)
如果线性编程,整个流程需要6ms.
但如果将每个节点作为一个thread。但thread间又同步执行。则整个流程只需要3ms.
mpstat及sar补遗(经典)
安装步骤
可以到http://pagesperso-orange.fr/sebastien.godard/download.html去下载
1 安装
tar zxvf xxx.tar.gz
./configure
make
make install
2 先来说mpstat
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。下面只介绍 mpstat与CPU相关的参数,mpstat的语法如下:mpstat [-P {|ALL}] [internal [count]]
参数的含义如下:
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
比如mpstat -P ALL 1
internal 相邻的两次采样的间隔时间
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。与CPU有关的输出的含义如下:
参数 解释 从/proc/stat获得数据
CPU 处理器ID
user 在internal时间段里,用户态的CPU时间(%) ,不包含 nice值为负 进程 usr/total*100
nice 在internal时间段里,nice值为负进程的CPU时间(%) nice/total*100
system 在internal时间段里,核心时间(%) system/total*100
iowait 在internal时间段里,硬盘IO等待时间(%) iowait/total*100
irq 在internal时间段里,软中断时间(%) irq/total*100
soft 在internal时间段里,软中断时间(%) softirq/total*100
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间 (%) idle/total*100
intr/s 在internal时间段里,每秒CPU接收的中断的次数 intr/total*100
CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirq
顺便说下
cat /proc/stat
“ctxt”给出了自系统启动以来CPU发生的上下文交换的次数。
“btime”给出了从系统启动到现在为止的时间,单位为秒。
“processes (total_forks) 自系统启动以来所创建的任务的个数目。
“procs_running”:当前运行队列的任务的数目。
“procs_blocked”:当前被阻塞的任务的数目。
3 sar采样
SAR采样之前在http://jackyrong.iteye.com/blog/238663
有说到,这里补遗下:
sar [options] [-A] [-o file] t [n]
在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有
的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式
存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar命令
的选项很多,下面只列出常用选项:
-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:内存和交换空间的使用统计。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-q:报告队列长度和系统平均负载
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
-x { pid | SELF | ALL }:报告指定进程ID的统计信息,SELF关键字是sar进程本身的统计,ALL关键字是所有系统进程的统计。
用sar进行CPU利用率的分析#sar -u 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/200907:40:17 PM CPU %user %nice %system %iowait %steal %idle
%user:CPU处在用户模式下的时间百分比。 %nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。 %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。 在所有的显示中,我们应主要注意%iowait和%idle,%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如 果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低, 表明系统中最需要解决的资源是CPU。用sar进行运行进程队列长度分析:#sar -q 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/200907:58:14 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
0.49runq-sz 准备运行的进程运行队列。
plist-sz 进程队列里的进程和线程的数量
4 注意不要迷信!
(转自http://developers.sun.com.cn/blog/yutoujava/entry/14)
T2000服务器上的性能测试,对于同一个系统,我们经常会发现,有时候用mpstat或vmstat观察出来很奇怪的结果,就是在CPU利用率比较低的时候,性能反而要好,而CPU利用得很充分的时候,响应时间反而很不好。按理说,CPU越忙就说明执行的指令越多,干活越多呀,为什么会慢呢?
T2000的服务器是单CPU的,但是这个CPU有8个核,每个核有4个硬件线程,在Solaris的操作系统下显示有32个虚拟CPU。实际上每个核有一个独立的执行单元(或叫Pipeline),因此,一般来说可以把T2000等同8CPU的机器。而每个核有4个硬件线程,主要是为每个核来准备可执行的指令集。硬件线程的利用率和核的利用率是两个不同的概念。而mpstat和vmstat主要用于单硬件线程的环境下,在多线程的CPU中,显示的结果有偏差。
通常来说,如果一个CPU不是idle状态,mpstat或vmstat就会认为这个CPU当前是busy。CPU在执行指令的时候,会遇上一些情况停止下来,不再执行任何指令。但是在非多线程的CPU中,如果当前的CPU因为一些原因无法执行其他的指令,也会被当做busy。这种情况经常出现,例如一些大指令(load),会跨好几个指令周期,在这段周期内,CPU暂时无法执行其他的指令,所以也算busy。但是在多线程的CPU下,当CPU在任何停顿的时间内,都可以切换到执行其他线程中的指令,因此,传统的mpstat或vmstat无法真实的反映这种情况。
那为什么mpstat或vmstat反映使用率较低,但系统的性能较好呢。这是因为,对于一个核中的4个线程,虽然每个线程的CPU占用率不高(例如各25%),但是这个核的执行单元却充分的得到了利用。
而有的时候,每个线程的CPU占用率都很高,CPU(核)也不一定在干活。例如这个核的每个线程都在执行load指令,在这些时候,四个线程的CPU都是100%的busy,但是CPU在一段周期内什么也没有执行。
在多线程的CPU环境下,需要其他的操作系统的命令才能真正观察到CPU的利用情况,例如cpustat:
cpustat -n -c pic0=L2_dmiss_ld,pic1=Instr_cnt -c pic0=L2_dmiss_ld,pic1=Instr_cnt,nouser,sys 1
或者到http://cooltools.sunsource.net/corestat/下载corestat工具包。
Linux下的top命令的图解使用
转载:http://www.cnblogs.com/xuxm2007/archive/2011/08/18/2144998.html
mpstat -P ALL 和 sar -P ALL 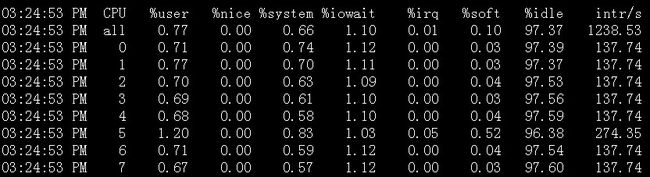
说明:sar -P ALL > aaa.txt 重定向输出内容到文件 aaa.txt
top命令经常用来监控linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。
本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。
top进入视图
top视图 01
【top视图 01】是刚进入top的基本视图,我们来结合这个视图讲解各个数据的含义。
第一行:
10:01:23 — 当前系统时间
126 days, 14:29 — 系统已经运行了126天14小时29分钟(在这期间没有重启过)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行:
Tasks — 任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
6.7% us — 用户空间占用CPU的百分比。
0.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
92.9% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。
第四行:内存状态
8306544k total — 物理内存总量(8GB)
7775876k used — 使用中的内存总量(7.7GB)
530668k free — 空闲内存总量(530M)
79236k buffers — 缓存的内存量 (79M)
第五行:swap交换分区
2031608k total — 交换区总量(2GB)
2556k used — 使用的交换区总量(2.5M)
2029052k free — 空闲交换区总量(2GB)
4231276k cached — 缓冲的交换区总量(4GB)
这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器“危矣”:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:530668+79236+4231276 = 4.7GB。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行是空行
第七行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
top视图 02
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在【top视图 01】中进程ID为14210的java进程排在第一(cpu占用100%),进程ID为14183的java进程排在第二(cpu占用12%)。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:
1. 敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
top视图 03
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
2. 敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
top视图 04
可以看到,top默认的排序列是“%CPU”。
3. 通过”shift + >”或”shift + <”可以向右或左改变排序列,下图是按一次”shift + >”的效果图:
top视图 05
视图现在已经按照%MEM来排序了。
改变进程显示字段
1. 敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:
top视图 06
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
top视图 07
2. “回车”返回基本视图,可以看到多了“CODE”和“DATA”两个字段:
top视图 08
top命令的补充
top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。
监控java线程数:
ps -eLf | grep java | wc -l
监控网络客户连接数:
netstat -n | grep tcp | grep 侦听端口 | wc -l
上面两个命令,可改动grep的参数,来达到更细致的监控要求。
在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l
在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID
TCP的状态迁移图详解
1、建立连接协议(三次握手)
(1)客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的报文1。
(2) 服务器端回应客户端的,这是三次握手中的第2个报文,这个报文同时带ACK标志和SYN标志。因此它表示对刚才客户端SYN报文的回应;同时又标志SYN给客户端,询问客户端是否准备好进行数据通讯。
(3) 客户必须再次回应服务段一个ACK报文,这是报文段3。
2、连接终止协议(四次握手)
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
(4) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)。
CLOSED: 这个没什么好说的了,表示初始状态。
LISTEN: 这个也是非常容易理解的一个状态,表示服务器端的某个SOCKET处于监听状态,可以接受连接了。
SYN_RCVD: 这个状态表示接受到了SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat你是很难看到这种状态的,除非你特意写了一个客户端测试程序,故意将三次TCP握手过程中最后一个ACK报文不予发送。因此这种状态时,当收到客户端的ACK报文后,它会进入到ESTABLISHED状态。
SYN_SENT: 这个状态与SYN_RCVD遥想呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,因此也随即它会进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。
ESTABLISHED:这个容易理解了,表示连接已经建立了。
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
CLOSING: 这种状态比较特殊,实际情况中应该是很少见,属于一种比较罕见的例外状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?其实细想一下,也不难得出结论:那就是如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT: 这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。
LAST_ACK: 这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。
最后有2个问题的回答,我自己分析后的结论(不一定保证100%正确)
1、 为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
2、 为什么TIME_WAIT状态还需要等2MSL后才能返回到CLOSED状态?
这是因为:虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到,因此对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文
linux下ss工具简介
http://blog.lifeibo.com/?p=244
在实际工作中,熟练使用工具,可以为我们提高不少效率。今天我们简单了解下ss工具的使用。ss即socket state,也就是说,是可以查看系统中socket的状态的。我们可以用netstat,但为什么还要用ss这个工具呢,当然ss也是有好处的。当我们打开的socket数量很多时,netstat就会变得慢了。
我们先来看看ss的使用格式:
- $ ss [ OPTIONS ] [ STATE-FILTER ] [ ADDRESS-FILTER ]
- $ ss [ OPTIONS ] [ STATE-FILTER ] [ ADDRESS-FILTER ]
options我从man手册里摘了过来:
-h – show help page
-? – the same, of course
-v, -V – print version of ss and exit
-s – print summary statistics. This option does not parse socket lists obtaining summary from various sources. It is useful when amount of sockets is so huge that parsing /proc/net/tcp is painful.
-D FILE – do not display anything, just dump raw information about TCP sockets to FILE after applying filters. If FILE is – stdout is used.
-F FILE – read continuation of filter from FILE. Each line of FILE is interpreted like single command line option. If FILE is – stdin is used.
-r – try to resolve numeric address/ports
-n – do not try to resolve ports
-o – show some optional information, f.e. TCP timers
-i – show some infomration specific to TCP (RTO, congestion window, slow start threshould etc.)
-e – show even more optional information
-m – show extended information on memory used by the socket. It is available only with tcp_diag enabled.
-p – show list of processes owning the socket
-f FAMILY – default address family used for parsing addresses. Also this option limits listing to sockets supporting given address family. Currently the following families are supported: unix, inet, inet6, link, netlink.
-4 – alias for -f inet
-6 – alias for -f inet6
-0 – alias for -f link
-A LIST-OF-TABLES – list of socket tables to dump, separated by commas. The following identifiers are understood: all, inet, tcp, udp, raw, unix, packet, netlink, unix_dgram, unix_stream, packet_raw, packet_dgram.
-x – alias for -A unix
-t – alias for -A tcp
-u – alias for -A udp
-w – alias for -A raw
-a – show sockets of all the states. By default sockets in states LISTEN, TIME-WAIT, SYN_RECV and CLOSE are skipped.
-l – show only sockets in state LISTEN
ss的强大之处,大于可以设定过滤条件,我们可以根据socket的状态来进行过滤,也可通过端口与ip地址进行过滤。也就是我们在命令格式里面看到的STATE-FILTER与ADDRESS-FILTER。
首先看看STATE-FILTER,STATE-FILTER可用的过滤条件有:
1. 所有的TCP状态,包含:established, syn-sent, syn-recv, fin-wait-1, fin-wait-2, time-wait, closed, close-wait, last-ack, listen and closing.
2. all,包含所有的状态。
3. connected,除了listen与closed的所有其它状态。
4. synchronized,除了syn-sent的所有connected的状态。
5. bucket
6. big
使用时,如:
- $ ss state connected
- $ ss state connected
再看看ADDRESS-FILTER,ADDRESS-FILTER用于过滤端口与地址。而且可以进行表达式组合。可用的子表达式有:
1. dst ADDRESS_PATTERN
2. src ADDRESS_PATTERN
3. dport RELOP PORT
4. sport RELOP PORT
5. autobound
其中ADDRESS_PATTERN为ip地址与端口匹配,ip:port,可以用*代替。RELOP为<= >=或==。
如:
- $ ss dst 192.168.0.1:80
- $ ss dport == 80
- $ ss dst 192.168.0.1:80
- $ ss dport == 80
多个子表达式之间可以组合,当然跟tcpdump一样,可以用or and not来组合。但括号要用转义符号表示。
如:
- $ ss -o state fin-wait-1 \( sport = :http or sport = :https \) dst 193.233.7/24
- $ ss -o state fin-wait-1 \( sport = :http or sport = :https \) dst 193.233.7/24
看看几个例子:
查看系统总体信息:
- $ ss -s
- Total: 85 (kernel 108)
- TCP: 15 (estab 4, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 12
- Transport Total IP IPv6
- * 108 - -
- RAW 0 0 0
- UDP 10 7 3
- TCP 15 12 3
- INET 25 19 6
- FRAG 0 0 0
- $ ss -s
- Total: 85 (kernel 108)
- TCP: 15 (estab 4, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 12
- Transport Total IP IPv6
- * 108 - -
- RAW 0 0 0
- UDP 10 7 3
- TCP 15 12 3
- INET 25 19 6
- FRAG 0 0 0
想看当前机器的8088端口被谁占用了:
- $ ss -lp src :8088
- Recv-Q Send-Q Local Address:P
- 0 0 *:8ers:(("nginx",2942,5),("nginx",2943,5))
- $ ss -lp src :8088
- Recv-Q Send-Q Local Address:P
- 0 0 *:8ers:(("nginx",2942,5),("nginx",2943,5))
我们可以看到,是一个叫nginx的进程,进程id是2942。
当然,用lsof工具也可以看到,还会更简单呢。lsof -i :80
好吧,就先简单介绍到这了。
转自:http://blog.csdn.net/zhangxinrun?viewmode=contents