spring/hibernate 优化
【编者按】对于大多数典型的 Spring/Hibernate 企业应用而言,其性能表现几乎完全依赖于持久层的性能。此篇文章中将介绍如何确认应用是否受数据库约束,同时介绍七种常用的提高应用性能的速成法,由OneAPM 工程师翻译。
以下为译文
如何确认应用是否受限于数据库
确认应用是否受限于数据库的第一步,是在开发环境中进行测试,并使用 VisualVM 进行监控。VisualVM 是一款包含在 JDK 中的 Java 分析器,在命令行输入 jvisualvm 即可调用。启用 Visual VM 之后,尝试以下步骤:
- 双击你正在运行的应用
- 选择 Sampler
- 点击 Settings 复选框
- 选择Profile only packages,然后输入下列包:
your.application.packages.*
org.hibernate.*
org.springframework.*
your.database.driver.package, 比如 oracle.*
点击 Sample CPU
如果应用性能受限于数据库,其 CPU 分析结果看起来会像下图
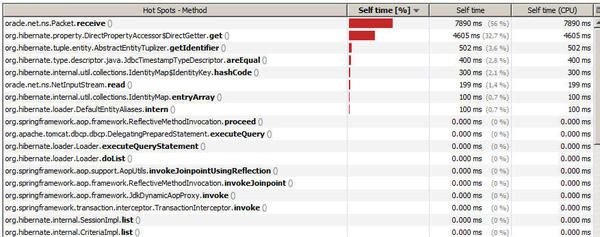
我们看到,客户端 Java 进程花在等待数据库从网络中返回结果的时间占56%。
看到数据库查询是导致应用运行缓慢的原因,其实是好兆头。Hibernate 反射调用占比32.7%是正常情况,无法进一步优化。
性能调优第一步:定义基准运行
性能调优的第一步是为程序定义基准运行,我们要定义一组能有效执行的输入数据,让程序基准运行与生产环境下的运行差不多。
主要的区别在于基准运行的耗时要小很多。作为参考,5到10分钟的执行时间比较不错。
什么是好的基准?
好的基准应该具备以下特征:
- 功能正确
- 输入数据的种类与生产环境下相似
- 在短时间内执行完毕
- 基准运行的优化方案可以外推至完整运行
定义好的基准是成功解决问题的一半。
什么是不好的基准
例如,通过批量运行处理通讯系统的电话数据记录,选取10000条记录就是错误的做法。
原因是:前10000条记录可能多为语音电话,而未知的性能问题可能发生在短信流量的处理过程中。一开始如果基准不够好,就会导致错误的结论。
收集 SQL 日志与查询时间
SQL 查询的执行语句与其执行时间可以通过 log4jdbc等方式收集。详细了解如何使用 log4jdbc 收集 SQL 查询信息,点击文章使用 log4jdbc 优化 Spring/Hibernate 应用 SQL 日志。
查询的执行时间是从 Java 客户端收集的,该时间包含查询数据库的来回网络调用。SQL 查询的日志如下:
预处理语句也是很重要的信息来源,它们常常会透露出常用的查询类型。了解更多的日志讯息,可以查看文章:Hibernate 为什么/在何处使用该 SQL 查询?
通过 SQL 日志可以了解哪些指标?
SQL 日志可以回答下列问题:
- 哪些是执行过的最慢查询?
- 哪些是最常用的查询?
- 生成主键的耗时是多少?
- 是否有数据适合缓存?
如何解析 SQL 日志
对于大量的日志文件,最可行的解析方式就是使用命令行工具,该方法的好处是非常灵活,只要写一小段脚本或命令,我们可以抽取出几乎大多数指标。只要你喜欢,任何命令行工具都适用。
如何你习惯了 Unix 命令行,bash 或是一个好选择。Bash 也可以在 Windows 工作站使用,Cygwin或 Git 都包含了 bash 命令行。
常用的速成法
下面介绍的速成法能找出 Spring/Hibernate 应用中常见的性能问题,以及对应的解决方案。
速成法1——减少生成主键的代价
在插入操作频繁的进程中,主键的生成策略很重要。生成 id 的一种常见方法是使用数据库序列,通常一张表一个 id,从而避免在不同表间进行插入时的冲突。
问题在于,如果要插入50条记录,我们希望为了获取这50个 id,可以避免50趟查询数据库的来回网络调用,让 Java 进程不一直等待。
Hibernate 通常如何解决此问题?
Hibernate 提供了优化的 ID 生成器以避免此问题。也即,对于序列,会默认使用 HiLo id 生成器。以下是 HiLo 序列生成器的工作方式:
- 调用一次序列,获得 1000 (高值)
- 用以下方式计算50个 id
为新的高值1001调用序列,依次类推
因此一次序列调用,可生成50个键,从而减少数次来回网络调用导致的负担。
这些优化的键生成器默认在 Hibernate 4中开启。如要禁用,可将hibernate.id.new_generator_mappings 设置为 false。
为什么生成主键仍是一个问题?
问题在于,如果你声明键生成策略为 AUTO,且未启用优化的键生成器,那么应用最后会面临大量的序列调用。
为了确保启用优化的键生成器,请将键生成策略改为 SEQUENCE 而非 AUTO。
改变设定之后,在插入操作频繁的应用中能看到10%到20%的性能提升,而且几乎没有改动代码。
速成法2——使用 JDBC 批处理 inserts/updates
对于批处理程序,JDBC 驱动程序提供了旨在减少网络来回传输的优化方法:”JDBC batch inserts/updates“。使用该方法后,插入或更新会先在驱动层排队,然后再传送到数据库。
当达到阈值后,所有排队的语句都会一次性传给数据库。这可以避免驱动程序逐一传送语句,导致网络来回传送的负担。
经过以下配置,就能激活批处理 inserts/updates:
仅设置 JDBC 批处理大小并不够。因为 JDBC 驱动程序只会在收到对同一张表 insert/updates 时批处理这些语句。
如果收到对一张新表的插入语句,JDBC 驱动程序会先清除对前一张表的批处理语句,然后开始分批处理针对新表的 SQL 语句。
Spring Batch 内置了相似的功能。该优化能在插入操作频繁的应用中带来30%到40%的性能提升,而不用改动任何代码行。
速成法3——定期清理 Hibernate 会话
在向数据库添加或修改数据时,Hibernate 会在会话中保留一版已经存在的实体,以防在会话关闭之前这些实体再度被修改。
但是,多数情况下,一旦对应的插入操作已经在数据库中完成,我们就可以安心地丢弃那些实体。这会释放 Java 客户端进程中的内存,避免过久的 Hibernate 会话导致的性能问题。
这种长久的会话应该尽量避免。但如果出于某种原因不得不使用它们,以下是控制内存消耗的方法:
flush 会触使新实体中的插入语句传送至数据库。clear 则会释放会话中的新实体。
速成法4——减少 Hibernate dirty-checking(脏数据检查) 的代价
Hibernate 内部使用了一种机制用于追踪被修改的实体,名为 dirty-checking。该机制并不基于实体类中的 equals 和 hashcode 方法。
Hibernate 尽可能将 dirty-checking 的性能成本保持在最低值,只在需要时使用 dirty-check。但是该机制也有成本,在列数很多的表中该成本尤其可观。
在进行任何优化之前,最重要的是使用 VisualVM 测量 dirty-checking 的成本。
如何避免 dirty-checking ?
dirty-checking 可以通过以下方式禁用:
禁用 dirty-checking 的另一种方式是使用 Hibernate 无状态会话,预知详情请查看文档。
速成法5——搜索”坏“查询计划
检查最慢查询列表,看看有没有好的查询计划。最常见的”坏“查询计划包括:
全表搜索:通常缺少一个索引或表统计过期时进行全表搜索。
全笛卡尔连接:意思是计算多张表的全笛卡尔乘积。检查一下缺少的连接条件,或拆分为几个步骤以简化查询。
速成法6——检查错误的提交间隔
如果你使用批处理程序,提交间隔会对性能造成十倍甚至百倍的影响。
请确保提交间隔是符合预期的(对于 Spring 批任务,通常是100到1000之间)。经常,该参数的配置不正确。
速成法7—— 使用二级查询缓存
如果一些数据可以缓存,则可以查看本文了解如何设置 Hibernate 缓存:Hibernate 二级/查询缓存的陷阱。
结论
解决应用性能问题的关键,在于通过收集一些指标发现当前的瓶颈。
没有一些测量指标,往往无法在短时间内找到真正的问题根源。
此外,很多典型的数据库驱动应用的性能陷阱,如果一开始就使用了 Spring Batch,就能够避免。
原文链接:Performance Tuning of Spring/Hibernate Applications (责编/仲浩)