中文化和国际化问题权威解析之三:Java中文问题分析
本章从实际的中文问题中,分析问题的根本原因,以及解决之道。
注意,本章虽然着重说明 “ 中文问题 ” ,但本章所推出的结论却是适合于世界所有语言文字的。
概述
我们在实际开发中碰到的中文问题,真是形形色色,无法一一列举。但是它们不是随机产生的,而是有规律可循,有办法解决的。
我们碰到最多的中文问题,都发生在使用 Java Servlet 写 WEB 应用时。其次,使用 Java Mail API 发送 e-mail 也会有类似的问题。从表象上区分,大致上有以下几种:
- 好端端的中文显示成了问号 “?” ,且一个中文变成 2 个问号。
- 好端端的中文显示成了问号 “?” ,且一个中文变成 1 个问号。
- 好端端的中文显示成了看不懂的符号,如 “ÎÒ°®Alibaba” 。
- WEB 页面中部分中文显示正常,部分中文是乱码。
要分析这些问题的根本原因,首先要了解这些 中文字符的输入源 ,其次是了解这些字符被输出到用户浏览器经过了哪些 转换和输出环节 。中文字符可以来源于:
- 程序内嵌的中文,我们在程序里直接书写中文字符串。
- 文本文件,利用 FileInputStream 读入文件内容并转换成字符。
- XML 文件,利用 XML 解析器读入内存。
- 数据库,利用 SQL 查询,取得的结果。
- 模板文件,例如 Velocity 或 WebMacro 模板,我们使用模板生成 WEB 页面。
- JSP 页面,在 JSP 生成的 WEB 页面。
- 用户通过浏览器提交的表单。
中文字符被装入内存以后,还要经过若干个转换和输出环节,最后才能到达用户的浏览器被用户看到。
- 文本通过 response.getWriter() 输出到浏览器端。
- 浏览器读取服务器的 HTTP 响应,并将响应中包含的 HTML 页面显示在浏览器上。
- 文本可能被写入 XML 文件、文本文件、数据库中。
以上列举的任何一个环节发生错误,都可能产生 “ 乱码 ” 现象。因此发生乱码现象时,不要慌,想想这个乱码的文本是从哪里来的,又是以什么方式输出的。
字符的输入、转换、输出环节
内嵌在程序代码中的中文
因为 Java 源代码( .java )本身是一个文本文件,所以和读普通文本文件一样,编译器( javac )必须以字节流的方式读入文件内容,并以适当的编码转换成 Unicode 字符而存储在 Java 字节码文件( .class )中。例如: Java 源代码文件中包含 GBK 编码的中文字符,则使用下面的命令编译:
- javac -encoding GBK MyClass.java
如果不指定
-encoding 参数, javac 会使用系统默认的编码:在中文 Windows 上,默认是 GBK ,在英文 Linux 上,默认是 ISO-8859-1 。因此,如果文件是在英文 Linux 下编译而未指定 -encoding ,那么文件中的中文 “ 我爱 Alibaba” 就会变成 “ÎÒ°®Alibaba” 了。从文本文件中读入的字符
正如前面的 TestDecoding 例子 所示,在读入文本文件时,需要指定正确的编码。如果不指明编码,那么 Java 就会使用系统默认的编码来转换文件中的字节流。下列代码往往会产生问题:
- public static String readStringFromFile(String filename) throws IOException {
- // 正确的方法:
- // FileInputStream istream = new FileInputStream(filename);
- // InputStreamReader reader = new InputStreamReader(istream, charset);
-
- // 可能会导致乱码的方法(取决于运行平台的默认编码):
- FileReader reader = new FileReader(filename);
- ...
- }
从XML 文件中读入的字符
XML 标准极为严格地遵守 Unicode 标准。 XML 文件的字符编码是定义在 XML 文件中,而不是定义在 XML 解析器中的。如果不明确指定,任何标准的 XML 解析总是以 UTF-8 的方式解码 XML 文件。可以用下面的方式在 XML 文件中指定字符编码:
- <? xml version = "1.0" encoding = "GB2312" ?>
在解码过程中,如果
XML 解析器发现一个非法的字节,不会像 Java 一样,转换成问号 “?” ,而是立即报错。所以 XML 解析器一般总会取得正确的 Unicode 字符。注意
注意, XML 规范并没有定义 GBK 和 GB18030 编码,因此不能在 XML 文件使用这两种编码。目前可以使用的中文编码是 GB2312 和 BIG5 。相信这种情况以后会改变。如果确实想使用中文大字符集,请指定 UTF-8 作为 XML 文件的编码。
数据库
首先,数据库一般都可以设置以何种字符编码方式存储文本;其次,数据库的客户端 —— JDBC 驱动 —— 必须设置成和数据库的内置字符编码一致;最后,尽可能使用 UTF-8 存取文本数据,因为这样可以在数据库中方便地存储所有国家的文字。
注意
我们 Alibaba 的 Oracle 数据库目前采用 7 位 ASCII 码存储文本(包括中文),这是一个极大的错误,已经导致了很多问题。我们后面会讲到。
模板文件
Velocity 和 WebMacro 是常用的 Java 模板系统。模板文件也是简单的文本文件。 Velocity 和 WebMacro 都可以在各自的配置文件定义读取模板所用的字符编码方式。例如 Velocity 可以这样设置:
- input.encoding=GBK
如果是在
Turbine (一种基于 MVC 设计模式的 WEB 应用框架, http://jakarta.apache.org/turbine )中调用 Velocity ,可以在 Turbine 的配置文件中设置:- services.VelocityService.input.encoding=GBK
这样
Velocity 就可以用 GBK 编码读取模板文件。JSP 页面
JSP 是一种特殊的 WEB 页面,在第一次使用时,被自动编译成一个普通的 servlet 。在 JSP 的开头指定 JSP 的字符编码:
- <% @page contentType= "text/html; charset=GBK" %>
上面这行告诉
JSP :- 用 javac -encoding GBK 命令选项来编译 JSP 所生成的 servlet 源代码。
2. 使用 GBK 编码输出 JSP servlet 中的所有字符,相当于:
- response.setContentType( "text/html; charset=GBK" )
3.
使用 GBK 解码用户的表单输入,相当于:
- request.setCharacterEncoding( "GBK" )
用户通过浏览器提交的表单
- request.setCharacterEncoding( "GBK" )
浏览器是根据页面的 content type 来决定以何种方式来编码用户输入的表单的。例如,一个页面的 content type 是 text/html; charset=GBK ,那么,当用户按下页面中的 submit 按钮时,浏览器自动将用户的输入用 GBK 方式编码并发送回服务器端。服务器接到用户的请求后,需要用正确的方式来解码,方法是:
- request.setCharacterEncoding( "GBK" );
然后再调用
request.getParameter(parameterName) 时就可以得到正确的 Unicode 字符。注意
必须在第一次调用 request.getParameter(parameterName) 之前调用 request.setCharacterEncoding(charset) ,因为解码是在第一次调用 request.getParameter(parameterName) 时发生的。
Servlet 规范规定,如果没有设定 request.setCharacterEncoding ,则使用 ISO-8859-1 来解码用户输入的表单,而 不是使用系统默认的编码 。
对于 multipart form (例如,上传图片的 form 表单),情况要复杂一些。因为 servlet 并没有直接支持 multipart form 。所以大多数应用程序使用了第三方的工具包来解析 multipart form ,例如: Oreilly COS工具包 。然而,这些工具包大多使用系统默认的编码来解析用户表单,和 servlet 规范不一致。如果你的 servlet 代码没有特别指明编码方式,则两种 form 表单将有不同的表现,必有一种情况会出现乱码现象。
Servlet 输出
Servlet 可以用两种方式向浏览器输出内容:
- 字节流方式 —— 输出到 response.getOutputStream() 。一般用来输出二进制内容,例如图片。
- 字符流方式 —— 输出到 response.getWriter() 。用来输出文本类型的内容,如 HTML 和纯文本。
在此我们只讨论输出文本的情形: response.getWriter() 。在调用 response.getWriter() 前,我们必须设置 content type :
- response.setContentType( "text/html; charset=GBK" );
response.getWriter()
通过 content type 中指定的字符编码来决定如何将字符流转换成字节流。在 Turbine 中,在配置文件中指定下面的内容, Turbine 会为你自动设置 content type :
- locale. default .charset=GBK
浏览器如何确定页面的字符编码
- locale. default .charset=GBK
浏览器收到从 WEB 服务器返回的页面时,
- 首先检查 HTTP 响应中指定的 content type ,也就是 servlet 通过 response.setContentType 方法设置的值。如果 content type 中指定字符编码(例如 text/html; charset=GBK ),则使用这种方式解码这个页面。
2. 如果 HTTP 响应中没有指定字符集,那么浏览器会检查 HTML 页面中是否包含:
- < meta http-equiv = "Content-Type" content = "text/html; charset=GBK" >
如果找到,则使用这里指定的字符编码。
- 如果既没有在 HTTP 响应中指定字符编码,也没有在 HTML 内容中指定字符编码,则浏览器根据一定的规则自动确定页面的字符编码。例如,在英文环境中,浏览器会使用 ISO-8859-1 ,简体中文环境中,则使用 GBK 。用户也可以根据自己的需要手工改变这一设置。
其它输出环节
文本还可能被写入 XML 文件、文本文件、数据库中。类似的,输出文件时一般都要指定字符编码。如果不指定,通常 Java 会选择系统默认的编码。这为程序运行的结果产生了不确定因素。
“ 乱码 ” 分析
明白了各输入、转换、输出环节是怎样工作的,我们的分析工作就有头绪了。在深入分析之前,有不少情况,观察乱码的表面现象就可以得到大概的结论。
一个中文变成了两个问号 “?”
这个现象通常表明字符在输入时出错,也就是解码错误。

虽然输出编码是对的,但在此之前,由于错误的输入编码,每个中文字变成了两个不相干的欧洲字符。而这些欧洲字符的编码和 GBK 编码是相冲突的(但也不一定完全冲突,例如上例中的第三个字节 B0 ,被转换成 GBK 的 E3A1 )。因此大部分中文被输出成两个问号。
如果出现乱码的中文字是从 Velocity 模板读入的,说明 Velocity 配置文件中的 input.encoding 设置不正确;如果这个中文字是从数据库读入的,说明数据库的配置出错,也有可能文本在保存进数据库之前就已经错了;如果这个中文字是从用户表单输入的,很可能是你忘了调用 request.setCharacterEncoding("GBK") 。
一个中文变成了一个问号 “?”
这个现象通常表明字符在输出时出错,也就是编码错误。
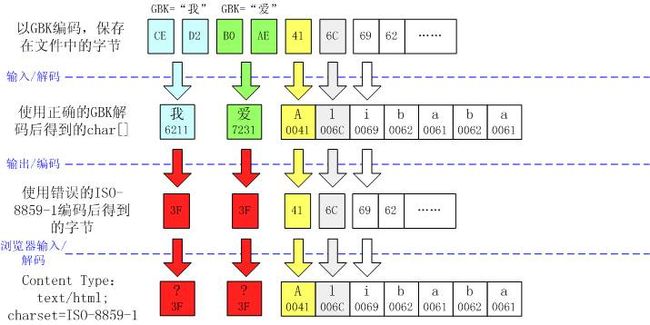
这很可能是因为没有设置 response.setContentType("text/html; charset=GBK") 。
中文显示成了看不懂的符号,如 “ÎÒ°®Alibaba”
这个现象通常表明字符在输入输出时都出错了。
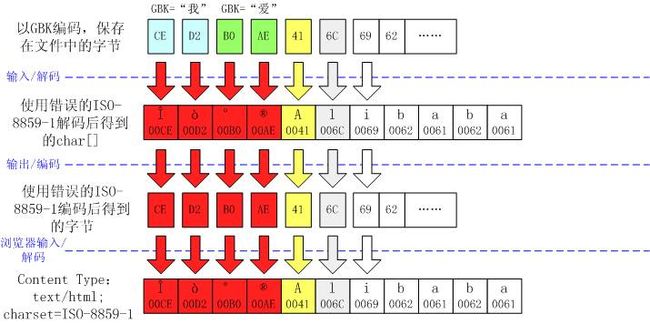
明眼人一看就发现,实际上在这种情况下,最后输出到浏览器上的 字节流是正确的 !只是因为 content type 被设成了错误的 ISO-8859-1 编码,所以才导致浏览器显示不正确的。事实上,用户可以手工改变浏览器的设置,使浏览器使用 GBK 对字节流重新解码。
看起来象是数学中的 “ 负负得正 ” 。为什么会这样呢?这是因为 ISO-8859-1 编码的特殊性导致的。 ISO-8859-1 字符集的编码范围是 0000-00FF ,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码 / 解码可以保持 编码数值 “ 不变 ” 。虽然中文字符在输入 JVM 时,被错误地 “ 拆 ” 成了两个欧洲字符,但由于输出时也是用 ISO-8859-1 ,结果被 “ 拆 ” 开的中文字的两半又被神奇地合并在一起。
这种情形在英文版的 Linux 上最常发生,事实上我们公司的很多程序就是这样做的。英文版 Linux 的系统默认编码为 ISO-8859-1 。假设我们的 servlet 从模板中生成动态网页:
- 输入环节 —— 如果我们不指定模板系统的字符编码,那么, Java 会使用系统默认的编码( ISO-8859-1 )读入模板文件,从而将一个 GBK 中文编码看作两个欧洲字符。
- 输出环节 —— 如果我们在设置 response.setContentType("text/html") 时不指明 “ charset ” ,按 servlet 规范,系统应以 ISO-8859-1 输出页面。从而恢复了正确的字节流。
- 浏览器输入环节 —— 浏览器发现 HTTP 响应中未指定字符编码,则检查 HTML 中有没有 <meta http-equiv="Content-Type" content="text/html; charset=GBK"> 之类的标记,如果有,则以 GBK 显示页面。此时页面显示是完全正常的(没有乱码)。
- 如果浏览器发现 HTTP 响应中未指定字符编码,并且 HTML 中也没有定义 meta 标记,则使用系统默认的编码。这取决于运行浏览器的平台和浏览器的设置。一般英文平台会以 ISO-8859-1 显示页面,从而显示成乱码。中文平台有可能可以正确显示页面。
同样的代码,如果在中文 Windows 上运行,因为系统默认编码为 GBK ,因而会转变成 “一个中文变成一个问号 ” 的情形。
如果页面中有部分字符不是来源于模板,而是来源于 XML 文件或 UTF-8 编码的数据库,又会转变成 “WEB页面中部分中文显示正常,部分中文是乱码 ” 的情形。
此外,把一个中文字符转换成两个欧洲字符,不仅使字符串变长了一倍,影响效率,而且前面所说的和 Unicode 相关的功能一概失效:断句断词、排序、查看字符属性、格式化日期和数字。
可见,使用这种方法显示中文,引入了诸多不确定因素,实在不是一种可取的方法。但是很多程序员满足于 “ 完成任务 ” ,却不求甚解,不理解 Unicode 的精义。甚至网上很多的文章也主张这么做,真是可悲可叹。
WEB 页面中部分中文显示正常,部分中文是乱码
很明显,这是由于同一页面中的字符是从不同的输入源取得的。假设有如下常见情形:
- 从模板取得的中文字使用了系统默认编码,中文 Windows 上是 GBK ,英文 Linux 上是 ISO-8859-1 ,后者将一个中文转变成了两个欧洲字符。
- 从 XML 取得的中文字总是正确的 Unicode 字符。
- 从用户表单读入的中文字,如果不指定编码( request.setCharacterEncoding ),总是以 ISO-8859-1 解码。
结果就是:
| Content Type |
浏览器环境 |
服务器环境 |
从模板取得的中文字 |
从 XML 取得的中文字 |
从用户表单取得的中文字 |
| text/html |
中文 Windows |
中文 Windows |
一个中文变成 1 个问号 |
一个中文变成 1 个问号 |
碰巧正常 |
| 英文 Linux |
碰巧正常 |
一个中文变成 1 个问号 |
碰巧正常 |
||
| 英文 Windows |
中文 Windows |
一个中文变成 1 个问号 |
一个中文变成 1 个问号 |
中文变成欧洲字符 |
|
| 英文 Linux |
中文变成欧洲字符 |
一个中文变成 1 个问号 |
中文变成欧洲字符 |
||
| text/html; charset=GBK |
任意 |
中文 Windows |
正常 |
正常 |
一个中文变成 2 个问号 |
| 英文 Linux |
一个中文变成 2 个问号 |
正常 |
一个中文变成 2 个问号 |
注意
所谓 “ 碰巧正常 ” 是指虽然在服务器上,一个中文被当作两个欧洲字符处理,但是输出到浏览器以后,又被重新组合成了正确的字节序列,并且浏览器按默认的选项,会以中文 GBK 解码此序列。对于 “ 中文变成欧洲字符 ” 的情形,可以在浏览器上人工设置字符编码为 GBK ,或是在 HTML 中设置 <meta http-equiv="Content-Type" content="text/html; charset=GBK"> 标记,来显示出中文。
深入分析
以上只是分析了最常见的 “ 乱码 ” 现象。实际上,还可能会发生更复杂一点的情形。但是无论什么情形,都可以通过仔细分析中文字符经过的每一个 输入 、 转换 、 输出 环节,来了解它的原因。