窥探算法之美妙——详细讲解寻找最长重复字符串的原理
原文发表在我的博客主页,转载请注明出处。
前言
据统计,在所有程序中,关于字符串处理的程序占到了百分之八十以上,所以关于字符串处理的算法十分多,而且关于数字处理的很多算法同样可以用于字符串中,包括本文提到的快速排序,除此之外关于字符串还有很多其他的算法,比如回文串,重复子串等等,这些问题还可以组合成为更复杂的问题,在字符串处理中,有一些较复杂或者说适用性不广的算法,即这个算法只对这类题目适用,但是他确实很巧妙。当然这些都不是重点,重点是将算法当作艺术去品,看见其魅力便可。闲话少说,开始正文。
问题
这个问题有很多版本,下面的便是一种经典的出题方式(题目来自于网上):
给定一个文本文件作为输入,查找其中最长的重复子字符串。例如,"Ask not what your country can do for you, but what you can do for your country"中最长的重复字符串是“can do for you”,第二长的是"your country"。
讲解
看完这个题目,片刻思忖,相信大多数人会和我一样得到最naive的解法,暴力解决办法,枚举遍历等等,因为这个题目本身给人一种重复性很强的感觉,所以算法的时间复杂度不会太低,想在O(N)时间内解决基本不大可能。naive的解法有我经过思考和参考列举下面两种,不附代码了,只用文字描述。
- 第一种方法,时间复杂度:O(N^3)
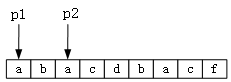
如下图:有一个字符串“abacdbacf”,我们用两个指针,p1从头开始,p2从p1+1开始,进行两层循环,在每层循环内部,寻找p1和p2所指的字符串的最长公共子串,这个思路比较简单,时间复杂度也容易求得,伪代码如下:
def find_longest_repeating_strings(string):
for p1 in range(len(string)):
for p2 in range(p1+1, len(string)):
max = find_common_string()
return max- 第二种方法,时间复杂度:O(N^3)
和第一种方法十分类似,都是遍历的思想,这次从长度开始,同样用两个指针,只是外层循环从1到字符串长度来控制p1和p2所指的要比较子串的长度,时间复杂度也十分容易分析,伪代码如下:
def find_longest_repeating_strings(string):
for i in range(1, len(string)):
for p1 in range(len(string)-i):
for p2 in range(p1+1, len(string)-i):
max = find_common_string()
return max- 第三种方法,时间复杂度:O(N^2logN)
这种方法用到了后缀数组,后缀数组是什么呢?用我自己理解来说,后缀是相对于前缀来说,前缀就是一个字符串的左子集,那后缀就是字符串的右子集,字符串的所有右子集的集合便组成了后缀数组。比如字符串“abc”的后缀数组就是["abc","bc","c"],很好理解吧。接下来先讲解第三种方法,以“abacdbacf”为例,然后再讲为什么这样可以,我想像我这种见识少的人会吃惊的。
- 求字符串的后缀数组
求解方法刚才已经说过,得到的后缀数组为:[abacdbacf,bacdbacf,acdbacf,cdbacf,dbacf,bacf,acf,acf,cf,f] - 将字符串的后缀数组按照字典序进行排序
可以使用任何方法将后缀数组进行排序,排序是按照字符的ASCII排序,我这里选择的是快速排序。排序后的结果为:['abacdbacf', 'acdbacf', 'acf', 'bacdbacf', 'bacf', 'cdbacf', 'cf', 'dbacf', 'f'] - 两两从头比较比较排序后的后缀数组相邻的两个字符串的公共子串
分别比较后缀数组里面相邻的两个字符串的公共子串,得到的最长公共子串即为题目所求,比如“abacdbacf”和“acdbacf”的最长公共子串为“a”,注意这里只需要从头比较,比如“banana”和“ana”的最长公共子串为“”,而不是“ana”,至于原因,接下来解释。
操作的步骤讲解完毕,由于在快速排序中我们的时间复杂度可以达到O(NlogN),所以最终的时间复杂度减少了,为O(N^2logN),为什么可以这样做呢?考虑第一种用两个指针的方法,不失一般性,假设现在指针指向了任意两个字符x,y,接下来需要的便是比较其指向的字符串的公共子串,这和先求后缀子串其实是一个道理,那求后缀子串的优势在哪里呢?不用挨个重复遍历,在得到了后缀数组之后,我们按照字典序进行排序,所有具有最长公共子串的肯定会相邻,所以在得到排好序的后缀数组之后,只需要O(N)的时间复杂度便可得到结果,但是要注意这里的最长公共子串是从第一个字符串开始比较,一旦不同,立马返回,比如“banana”和“ana”的最长公共子串为“”,而不是“ana”,因为您只要稍微想一下,就会发现,“anana”也是后缀数组中的一元素。最后附上代码如下,或者直接从github下载:
def partition(suffix_array, start, end):
if end <= start:
return
index1, index2 = start, end
base = suffix_array[start]
while index1 < index2 and suffix_array[index2] >= base:
index2 -= 1
suffix_array[index1] = suffix_array[index2]
while index1 < index2 and suffix_array[index1] <= base:
index1 += 1
suffix_array[index2] = suffix_array[index1]
suffix_array[index1] = base
partition(suffix_array, start, index1 - 1)
partition(suffix_array, index1 + 1, end)
def find_common_string(str1, str2):
if not str1 or not str2:
return 0, ''
index1, index2 = 0, 0
length, comm_substr = 0, ''
while index1 < len(str1) and index2 < len(str2):
if str1[index1] == str2[index2]:
length += 1
comm_substr += str1[index1]
else:
break
index1 += 1
index2 += 1
return length, comm_substr
def find_longest_repeating_strings(string):
if not string:
return None, None
suffix_array = []
# first, get the suffix arrays
length = len(string)
for i in range(length):
suffix_array.append(string[i:])
# second, sort suffix array
start, end = 0, len(suffix_array) - 1
partition(suffix_array, start, end)
# third, get the longest repeating substring
max_length, repeat_substring = 0, ''
for i in range(len(suffix_array) - 1):
common_len, common_substring = find_common_string(suffix_array[i], suffix_array[i+1])
if common_len > max_length:
max_length, repeat_substring = common_len, common_substring
return max_length, repeat_substring
if __name__ == "__main__":
string = "Ask not what your country can do for you, but what you can do for your country"
length, substr = find_longest_repeating_strings(string)
print length, substr总结
关于字符串的处理有太多的巧招妙招,本文只是其中的一种,总之自己看完这种解法之后,大呼美妙~