Unity中的C#内存管理
今天在蛮牛上发现不知道谁总结的Unity中C#内存的管理,觉得挺好,立马转载过来
本系列文章主要讲解C#针对unity的内存管理,共有三部分,各部分内容如下:
第一篇文章讨论.NET和Mono垃圾回收的内存管理基本的原理。也涉及一些常见的内存泄漏来源。
第二篇文章着重于使用工具发现内存泄漏。Unity Profiler在此方面是一个强大的工具,但它代价太高(unity5中免费)。因此我将讨论.NET反汇编和通用中间语言(CIL),以此展示如何使用免费工具发现内存泄漏。
第三个篇文章讨论C#对象池。重点针对Unity/C# 开发中出现的特定需求。
垃圾回收的限制
大多数现代操作系统把动态内存分为堆栈和堆 (1,2) ,很多 CPU体系结构(包括PC 和 Mac以及智能手机/平板电脑) 在其指令集支持这种划分。C# 通过区分值类型(简单的内置类型以及用户定义的enum或struct类型)和引用类型(类、 接口和委托)。值类型在堆栈上分配,引用类型在堆上分配。堆栈在开启新线程时被设置为一个固定值。它通常很小― ―例如,在Windows上的.NET线程默认堆栈大小为1Mb。这种内存用于加载线程的主要功能和局部变量,以及一些频繁加载和释放的函数(与局部变量一起)被主线程调用。其中一些可能会被映射到CPU的缓存中以加快访问速度。只要函数调用深度不是过高或局部变量使用内存不多,就不必担心堆栈溢出。堆栈的这种用法很符合结构化编程的概念。
如果对象太大,无法放在堆栈中,或者如果它们的生命周期比创建它们的函数还久那么就需要使用堆。堆是除堆栈外的内存的一部分,(通常)按照自己的需求向OS申请。堆栈内存管理很简单(只需要使用一个指针记住内存块开始的位置),与之相比堆碎片在分配对象时出现,释放时回收。可以把堆看作瑞士奶酪,你必须记住所有的小孔(瑞士奶酪一般有很多小孔,记住这么多小孔是多么复杂)!内存管理自动化主要任务是辅助你跟踪所有的孔,几乎所有现代编程语言都支持。更难的工作是内存自动释放,尤其是决定在什么时候该释放对象。这样就不用去自己管理内存了。
后面的工作称为垃圾回收(GC)。不用自己告诉运行时环境何时释放对象内存,运行时自己会跟踪所有对象的引用,从而决定释放时机。GC按照一定的时间间隔工作,当对象不会被任何代码访问到时,这个对象会被销毁,占用的内存会被释放,GC会回收此对象。至今仍有很多学者在研究GC,这就是为什么自从.NET框架1.0开始到现在GC的架构已经有了巨大的改变和提升。虽然Unity不使用.NET,但是毕竟.Net开源,Mono也算是.Net近亲,而Mono也一直落后于它的商业对手。此外,Unity默认的Mono版本不是最新的2.11/3.0而是2.6版本(准确的说是2.6.5,我使用Windows版Unity4.2.2和Unity4.3)。
Mono 2.6之后的版本的一个重大修订是关于GC,新版本使用的是generational GC,而2.6版本使用的是不太负责的Boehm garbage collector。现代generational GC表现很好,可以应用于实时程序,例如游戏。而Boehm风格GC是通过相对不太常见的穷举法每隔一段时间搜索堆上的垃圾(不会被引用的对象)。因此,它有种趋势,每隔一段时间产生帧率性能下降,从而影响用户体验。Unity文档推荐每当游戏进入帧率降低的下一阶段最好自己主动调用System.GC.Collect()(例如,加载新场景、显示菜单)。然而,对于很多游戏都很少出现这样的时候,这意味着GC在你想调用之前已经执行内存回收了。这种情况下,你只能咬紧牙关自己管理内存。这也是本文和接下来两篇文章要探讨的问题。
自己制作内存管理器
我们首先应该清楚什么是在Unity/.Net世界“自己管理内存”。你自己去跟踪分配了多少内存的能力是有限的。你需要选择自定义的数据结构是类(通常在堆上分配)还是结构体(通常在堆栈分配,除非是类的成员变量)。如果你想要更多魔力,你需要使用C#的“unsafe”关键字。但是unsafe代码是无法校验的代码,意味着它不能在unity web player和其它可能的目标平台中运行,基于这些种种原因,最好不用“unsafe”。由于上述那些堆栈的限制,而且因为C#数组只是System.Array(是个类)的语法封装,你不能也不应该避免使用自动堆分配功能。你需要避免的只是不必要的堆分配。我们将在后面的文章中介绍这方面的知识。
当对象被释放之后你所能做的相当有限。事实上,唯一可以释放分配堆对象的只是GC,GC的工作对开发者是不可见的。你能影响的只是堆中对象最后的引用失效的时间,因为GC只会在对象不再被引用时去访问它们。这种限制有很强的实际意义,因为周期性的垃圾回收(你无法避免)在没有对象需要释放时效率非常快。
[C#] 纯文本查看 复制代码
foreach (SomeType s in someList)
s.DoSomething();
转换成
[C#] 纯文本查看 复制代码
using (SomeType.Enumerator enumerator = this.someList.GetEnumerator())
{
while(enumerator.MoveNext()){
SomeType s = (SomeType) enumerator.Current;
s.DoSomething();
}
}
常见的非必须堆分配原因
我们应该避免使用“foreach”循环吗?
一般建议是避免使用foreach循环,尽量使用for或者while循环,我在Unity论坛遇到很多人提到这个建议。这背后的原因咋一看似乎是合理的,foreach只是语法封装,因为编译器处理代码的流程大体是下面这样:
[C#] 纯文本查看 复制代码
foreach (SomeType s in someList)
s.DoSomething();
转换为如下:
[C#] 纯文本查看 复制代码
using (SomeType.Enumerator enumerator = this.someList.GetEnumerator())
{
while (enumerator.MoveNext())
{
SomeType s = (SomeType)enumerator.Current;
s.DoSomething();
}
}
换句话说,每次使用foreach都会创建一个enumerator对象,一个System.Collections.IEnumerator接口实例。但这创建在堆栈还是堆上呢?这是一个很好的问题。因为,都有可能。最重要的是,几乎所有System.Collections.Generic(List<T>, Dictionary<K,V>, LinkedList<T>, etc.)命名空间中的集合类型都可以从GetEnumerator()函数执行返回一个结构。包括Mono 2.6.5正式版(Unity使用的版本)。
你可能知道可以使用微软的Visual Studio 开发然后编译成Unity/Mono兼容的代码。你只需把相应的集合拖进Assets文件夹。所有代码就会在Unity/Mono 运行时环境执行。然而,不同编译器编译的代码会有不同的结果,我现在才明白,foreach循环也是如此。虽然两个编译器都可以识别 GetEnumerator()返回的是结构体或类,Mono/C#在将枚举结构装箱为引用类型时有Bug(见下面的装箱部分)。
应该避免使用foreach循环吗?
不要在Unity编译C#脚本代码时使用.
在使用标准通用集合迭代器时使用(例如List<T>),而且使用VS或者.Net框架sdk编译代码。我猜测(没有验证)Mono最新版和MonoDevelop也可以。
使用外部编译器时,可以使用foreach循环迭代来枚举其他类型的集合吗?不幸的是,没有通用的答案。第二篇文章将讨论并找出哪些集合使用foreach是安全的。
[C#] 纯文本查看 复制代码
int result = 0;
void Update()
{
for (int i = 0; i < 100; i++){
System.Func<int, int> myFunc = (p) => p * p;
result += myFunc(i);
}
}
应该避免使用闭包和LINQ吗?
C#提供了匿名方法和lambda表达式(两者几乎但不完全相同)。你可以分别使用delegate关键字和=>操作符来创建,它们是非常方便的工具,如果你想使用某些库函数(例如 List<T>.Sort())或LINQ很难不用到它们。
匿名方法和lambda表达式会引起内存泄露吗?答案是:这取决于C#编译器,有两种区别很大的方式来处理。想了解其中的区别,先看看下面的代码:
[C#] 纯文本查看 复制代码
int result = 0;
void Update()
{
for (int i = 0; i < 100; i++)
{
System.Func<int, int> myFunc = (p)=> p * p;
result += myFunc(i);
}
}
如你所见,以上代码似乎每帧要创建100次委托函数myFunc ,每次调用它执行一次计算。但是Mono只在第一次调用Update()方法时分配堆内存(在我的系统上只用了52字节),在之后的帧也没有更多的堆分配操作。这是怎么了?使用代码反编译器(将会在下篇文章解释)可以看见C#编译器只是简单的把myFunc 替换为类的一个静态System.Func<int, int> 类型字段,包括 Update()函数也是。这个字段的名字很奇怪但是也有一些意义:f__am$cache1(不同系统上可能会有差别),也就是说,托管方法只分配一次,然后就被缓存了。
现在我们在托管定义方式上做一些小小的改变:
[C#] 纯文本查看 复制代码
System.Func<int, int> myFunc = (p) => p * i++;
通过把“p”替换为“i++”,我们已经局部定义方法转变成一个真的闭包。闭包是函数编程的一大支柱。它把数据和函数联系到一起,更准确的说是非局部变量在函数之外定义。在myFunc中,p是一个局部变量但i是一个非局部变量,属于Update()方法。C#编译器现在不得不将myFunc转换成可访问、甚至是可修改,包含非局部变量的方法。它通过声明一个全新的类表示myFunc创建的引用来实现这一功能。For循环每次执行都要分配一个类的实例,瞬间产生大量的内存泄露(在我的电脑上每帧26KB)。
当然,闭包和其他语言特性在C# 3.0被引入的主要原因是LINQ。如果闭包可以引起内存泄露,在游戏中使用LINQ还安全码?我不是能回答这个问题的最佳人选,因为,我总是像躲避瘟疫一样避免使用LINQ。LINQ明显在不支持即时编译的操作系统上无法工作,例如iOS。但是从内存角度来说,LINQ弊大于利。下面是一个难以置信的基础表达式:
[C#] 纯文本查看 复制代码
int[] array = { 1, 2, 3, 6, 7, 8 };
void Update()
{
IEnumerable<int> elements = from element in array
orderby element descending
where element > 2
select element;
...
}
在我的系统上每帧分配了68字节(Enumerable.OrderByDescending() 占用了28字节, Enumerable.Where() 40字节)。罪魁祸首不是闭包而是IEnumerable的扩展方法:LINQ创建了中间数组来实现最终结果,而且也没有一个系统在之后回收它们。我不是LINQ专家,我并不知道是否可以在实时环境中安全的使用其组件。
协程
如果你通过 StartCoroutine()运行一个协程,则会隐式分配Unity Coroutine (在我系统上占用21字节)类和Enumerator(占用16字节)。重要的是当协程调用yiled和恢复时不会分配。所以,为了避免内存泄露,在游戏运行时尽量少用StartCoroutine()。
[C#] 纯文本查看 复制代码
void Update()
{
string string1 = "Two";
string string2 = "One" + string1 + "Three";
}
字符串
C#和Unity内存问题必须会提到字符串。从内存角度,字符串很奇怪,因为,他们是堆分配且不变的。当你连接两个字符串时(无论是变量还是常量):
[C#] 纯文本查看 复制代码
void Update()
{
string string1 = "Two";
string string2 = "One" + string1 + "Three";
}
运行时不得不分配至少一个新的字符串对象存储新的结果。String.Concat()有效地通过调用FastAllocateString()分配新对象,但是必定会产生多余的堆分配(上面例子在我的系统上占用40字节)。如果你需要在运行时修改或者连接字符串,最好使用 System.Text.StringBuilder。
装箱
有时,数据必须在堆栈和堆之间传输。例如:
[C#] 纯文本查看 复制代码
string result = string.Format("{0} = {1}", 5, 5.0f);
你正在调用下面的签名方法:
[C#] 纯文本查看 复制代码
public static string Format(string format, params Object[] args )
换句话说,当调用Format()时整数“5”和浮点数“5.0f”必须被强制转成System.Object。但是,对象是引用类型,而其它两个是值类型。因此C#不得不在堆上分配内存,将值复制到堆上,把新的int和float对象的引用传递给Format()。这个流程就叫做装箱,反之对应的过程叫开箱。
这种行为也许不是 String.Format()的问题,因为你知道它会在堆上分配内存。
但是,装箱很少以预期情况出现。一个臭名昭著的例子是,你使用“==”运算符判断自定义值类型(例如,一个表示复数的结构体)。所有避免装箱例子见这里。
[C#] 纯文本查看 复制代码
public static class ListExtensions
{
public static void Reverse_NoHeapAlloc<T>(this List<T> list)
{
int count = list.Count;
for (int i = 0; i < count / 2; i++)
{
T tmp = list[/color][/font][font=微软雅黑][color=#000000][i];[/i]
list[/color][/font][font=微软雅黑][color=#000000][i] = [/i]list[count - i - 1];
list[count - i - 1] = tmp;
}
}
}
库方法
最后讲一下各种库方法也会隐式分配内存。捕捉它们最好的方法是分析。最近碰到的有趣例子是:
我之前已经写过的 foreach-循环,大多数标准泛型集合不会导致堆分配。Dictionary <K、 V>也是。然而,有点神秘地,Dictionary <K、 V>.KeyCollection和Dictionary <K、 V>.ValueCollection是类,不是结构,这意味着"foreach(K key in myDict.Keys)......"会分配16个字节。
List <T>.Reverse()使用标准替换数组反转算法。如果你和我一样认为它不分配堆内存,那就错了,至少Mono 2.6版本会。可以使用下面的扩展方法,虽然它可能不如.NET/Mono优化的好,但至少可以避免堆内存分配。用法与List<T>.Reverse()相同:
[C#] 纯文本查看 复制代码
public static class ListExtensions
{
public static void Reverse_NoHeapAlloc<T>(this List<T> list)
{
int count = list.Count;
for (int i = 0; i < count / 2; i++)
{
T tmp = list[/color][/font][font=微软雅黑][color=#000000];
list[/color][/font][font=微软雅黑][color=#000000] = list[count - i - 1];
list[count - i - 1] = tmp;
}
}
}
在本系列教程的第一篇中,我们讨论了.Net/Mono和unity的内存管理的基础知识,并提供了一些避免不必要的堆内存分配的技巧。第三篇文章将深入介绍对象池。
让我们仔细看看找到项目中非必须堆分配的两种方法。第一种方法非常简单,使用工具Unity Profiler。第二种,反编译.Net/Mono 程序集成公共中间语言(CIL)之后检查。如果你之前从未看过反编译的.Net代码,试着阅读一下,代码并不难。反编译后的代码是免费的而且有很多可以学习参考的地方。下面,我打算教会你CIL,这样就可以检查代码实际的内存分配情况。
简单方法:使用Unity profiler
Untiy的优秀工具Profiler主要用于分析游戏中多种类型assets的性能和资源消耗,例如:着色器,纹理,声音,游戏对象等。Profiler在挖掘C#代码(即使外部的.Net/Mono程序集没有引用UnityEngine.dll)的内存相关行为方面用处非常大。但是,在当前Unity版本(4.3)只有CPU分析器有该功能,而内存分析器没有。当检查C#代码时,内存分析器只显示总大小和Mono堆已使用大小。
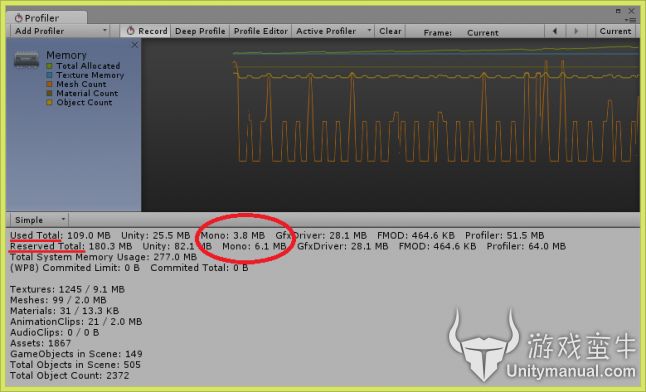
UnityProfiler显示的太简单了,如果C#代码内存泄露,你根本发现不了。即使没有使用任何脚本,堆的“已用”大小也会一直持续地在增长和减少。如果使用脚本,可以使用CPU profiler查看在哪里发生堆内存分配。
让我们看看一些示例代码,将下面脚本附加到某个游戏对象上。
[C#] 纯文本查看 复制代码
using UnityEngine;
using System.Collections.Generic;
public class MemoryAllocatingScript : MonoBehaviour
{
void Update() {
List<int> iList = new List<int>(new int[]{ 072, 101, 108, 108, 111, 032, 119, 111, 114, 108, 100, 033});
string result = "";
foreach (int i in iList.ToArray())
result += ((char)i).ToString();
Debug.Log(result);
}
}
脚本功能只是以循环方式从一堆整数生成字符串("Hello world!"),过程中产生了一些不必要的分配。有多少?我很高兴你问了这个问题,但是我很懒,所以,我们使用CPU profiler来查看一下。选中窗口最上面的“Deep Profile”,它会在每一帧尽可能记录所有函数调用的深度,并以调用树的形式展示出来。
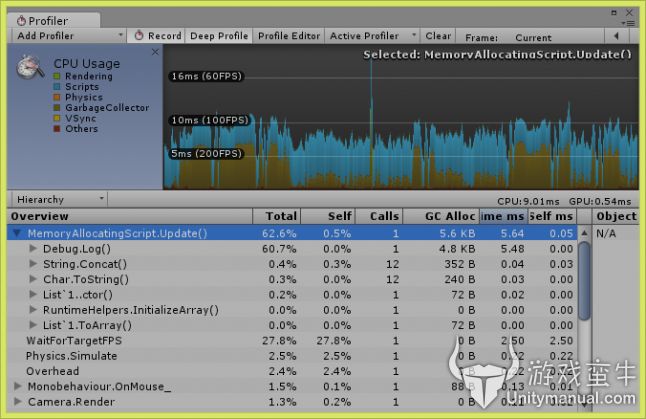
如你所见,我们的Update函数在5个不同地方分配了堆内存。初始化List,之后在foreach循环中转换成数组,每个数字都转成一个字符串,连接所有这些字符串产生的内存分配。有趣的是,不经常调用的Debug.Log()也分配了很大一块内存―即使Debug.Log在发布时会被过滤掉,我们也需要牢记这一点。
如果你没有专业版的Unity,但是碰巧有Microsoft Visual Studio,请注意,有一个与记录调用树功能类似的工具可以替代Unity Profiler。Telerik 告诉我他们的JustTrace内存分析器有这个类似的功能(见这里)。然而,我不知道它替代Unity在每一帧记录函数调用树的能力是不是好于Unity。此外,虽然可以在Visual Studio(通过我最喜欢的工具UnityVS)中远程调试Unity工程,但是,我还没有成功地使用JustTrace来配置Unity调用的程序集。
稍微困难的方法:反编译自己的代码
CIL背景介绍
如果你已经有了.NET/Mono反编译器,现在开始反编译吧。如果没有,我推荐ILSpy。这个工具不但免费,而且界面简洁使用简单。我们需要深入了解下面一些特定功能。
C#编译器不会把C#代码编译成机器语言,而是编译成公共通用语言CIL。CIL是由.Net团队开发的一种底层语言,包含高级语言的两个特性。它在不同硬件平台不需要重新编译,同时还拥有面向对象的特性。例如,可以引用其他模块和类(其他程序集)。
没有经过混淆的CIL代码非常容易被逆向还原出源码。在许多情况下,逆向代码和原来C#代码几乎相同。ILSpy就是反编译的工具,它反编译之后的代码可读性高(ILSpy调用ildasm.exe,属于.Net/Mono的一部分)。让我们从一个非常简单的方法开始,将两个整数相加。
[C#] 纯文本查看 复制代码
int AddTwoInts(int first, int second) {
int result = first + second;
return result;
}
如果你愿意,可以拷贝上面这段代码保存到MemoryAllocatingScript.cs文件。确定使用Unity来编译,然后在ILSpy中打开编译后的库文件Assembly-Csharp.dll(一般在Unity工程目录的Library\ScriptAssemblies中)。在程序集中选择theAddTwoInts方法,你将会看到下面的反编译代码。
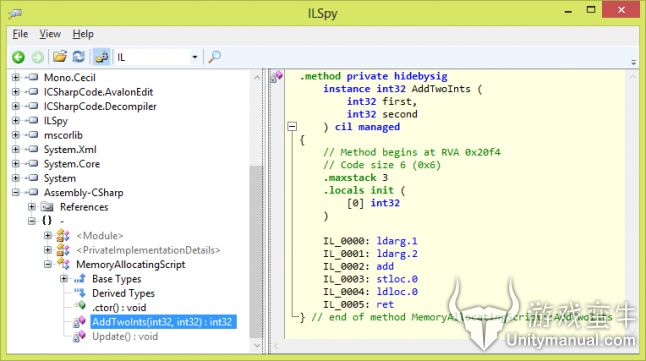
我们可以忽略蓝色关键字“hidebysig”,该方法看起来很熟悉。要明白函数体代码的意思,你需要了解,CIL把计算机的CPU当做一个堆栈栈机而不是寄存器机。CIL假定CPU可以处理非常基本的指令(主要是算数运算指令,如:“两个整数相加”),并且可以随机存取任何内存地址。CIL还假定CPU不直接在RAM执行算数运算,而是首先加载数据到“evaluation stack”(evaluation stack和C#堆栈不是一个概念,只是一个抽象概念,假定占用空间也不大)。从IL_0000 到IL_0005代码的意思是:
两个整数参数被压入堆栈
两数相加,弹出堆栈开始的两个单元,自动把计算结果压入堆栈
第3、4行可以忽略,因为在发行版他们会被优化掉
该方法返回堆栈的最上面第一个值(相加的结果)
在CIL中查找内存分配
CIL代码的优势在于堆分配代码不会被隐藏。相反,完全可以在反编译的代码中找到堆分配的三种指令。
newobj <constructor>:通过构造函数创建一个指定类型的未初始化对象。如果对象是值类型(结构体等),则在堆栈创建。如果是引用类型(类等)则在堆上分配。可以从CIL代码知道对象类型,所以,可以很容易知道在哪分配。
newarr <元素类型>:在堆上创建一个数组。元素类型在参数中指定。
box <值类型标记>:装箱(传递数据)专用指令,在第一部分已经介绍过。
我们来看一个使用了上面三种分配类型的方法,代码如下:
[C#] 纯文本查看 复制代码
void SomeMethod() {
object[] myArray = new object[1];
myArray[0] = 5;
Dictionary<int, int> myDict = new Dictionary<int, int>();
myDict[4] = 6;
foreach (int key in myDict.Keys)
Console.WriteLine(key);
}
这几句代码生成的CIL代码很多,我只摘录了关键部分:
[C#] 纯文本查看 复制代码
IL_0001: newarr [mscorlib]System.Object
...
IL_000a: box [mscorlib]System.Int32
...
IL_0010: newobj instance void class [mscorlib]System.
Collections.Generic.Dictionary'2<int32, int32>::.ctor()
...
IL_001f: callvirt instance class [mscorlib]System.
Collections.Generic.Dictionary`2/KeyCollection<!0, !1>
class [mscorlib]System.Collections.Generic.Dictionary`2<int32,
int32>::get_Keys()
正如我们怀疑的那样,使用newarr 指令(SomeMethod第一行代码)来分配数组对象。整数“5”是这个数组的第一个元素,需要使用“装箱操作(Box)”传递数据。使用newobj指令来分配Dictionary<int, int>。
但是,这里产生了第四个堆分配。我在第一篇文章说过,Dictionary<K, V>. KeyCollection被声明为类,而不是结构体。创建类的实例之后foreach才能循环遍历所有项。不幸的是,这个堆分配为了获取Keys 字段调用了一个特殊的getter方法,你可以在CIL代码中看到,这个方法的名字是get_Keys,它的返回值是类。看完这段代码,你可能已经对发生的事情有了些眉目。但是,为了弄清楚newobj 指令产生的KeyCollection 实例,你需要使用ILSpy反编译mscorlib ,并定位到 get_Keys()方法。
有一个查找内存泄露的基本策略,在ILSpy中通过快捷键Ctrl+S(File->Save Code)为整个程序集创建一个CIL-dump。之后在文本编辑器中打开这个dump,并搜索上面所说的三个指令定位到内存分配的代码。找到其它程序集中的内存分配是有难度的。我唯一知道的策略是仔细查看C#代码,找到所有调用外部方法的代码,逐一检查他们的CIL代码。
备注:如何验证系统安装的Mono版本呢?有了ILSpy事情变得非常简单。在ILSpy中单击打开Unity根目录,定位到Data/Mono/lib/mono/2.0(在Unity 5.1 Mac版本中没有该目录,Windows没有验证。可能是老版本的Unity才有)目录,然后选择mscorlib.dll,在层次导航中找到“Consts”类,你将会发现一个字符串常量MonoVersion ,即Mono的版本号。
本系列文章的第一部分讨论了.Net/Mono和unity内存管理的基本知识。第二部分深入介绍了Unity Profiler和CIL相关知识,以发现C#代码中不必要的内存分配。
第三篇文章即本文将介绍对象池。到目前为止,我们一直关注的是堆分配。现在我们还想要避免不必要的内存释放,以至于在游戏运行时不会因为垃圾回收器(GC)回收内存而产生帧率下降。对象池是解决这个问题的理想方案。我将展示三种对象池的完整代码(你可以在GithubGist中找到这些代码)。
从一个非常简单的对象池类开始
对象池背后的理念非常简单。不再使用new创建新的对象,而是在对象池中储存用过的对象,允许他们之后再被回收,从而在需要时重复使用他们。对象池最重要的一个特性、真正的对象池设计模式的本质是当我们需要获得一个新的对象时,不需要关心对象是重新创建的还是循环使用的原来对象。下面几行代码就是对象池设计模式的具体实现:
[C#] 纯文本查看 复制代码
public class ObjectPool<T> where T : class, new()
{
private Stack<T> m_objectStack = new Stack<T>();
public T New()
{
return (m_objectStack.Count == 0) ? new T() : m_objectStack.Pop();
}
public void Store(T t)
{
m_objectStack.Push(t);
}
}
本帖最后由 小刺刺 于 2015-8-31 15:33 编辑
本系列文章的第一部分讨论了.Net/Mono和unity内存管理的基本知识。第二部分深入介绍了Unity Profiler和CIL相关知识,以发现C#代码中不必要的内存分配。
第三篇文章即本文将介绍对象池。到目前为止,我们一直关注的是堆分配。现在我们还想要避免不必要的内存释放,以至于在游戏运行时不会因为垃圾回收器(GC)回收内存而产生帧率下降。对象池是解决这个问题的理想方案。我将展示三种对象池的完整代码(你可以在GithubGist中找到这些代码)。
从一个非常简单的对象池类开始
对象池背后的理念非常简单。不再使用new创建新的对象,而是在对象池中储存用过的对象,允许他们之后再被回收,从而在需要时重复使用他们。对象池最重要的一个特性、真正的对象池设计模式的本质是当我们需要获得一个新的对象时,不需要关心对象是重新创建的还是循环使用的原来对象。下面几行代码就是对象池设计模式的具体实现:
[C#] 纯文本查看 复制代码
?
01
02
03
04
05
06
07
08
09
10
11
public class ObjectPool<T> where T : class, new()
{
private Stack<T> m_objectStack = new Stack<T>();
public T New()
{
return (m_objectStack.Count == 0) ? new T() : m_objectStack.Pop();
}
public void Store(T t)
{
m_objectStack.Push(t);
}
}
非常简单,但这的确是核心模式的完美实现。(如果你不懂"where T..."语法,下面将会解释)。想用这个类,就不能像下面这样用new操作符来创建类:
[C#] 纯文本查看 复制代码
void Update() {
MyClass m = new MyClass();
}
而是成对使用 New() 和 Store()方法:
[C#] 纯文本查看 复制代码
ObjectPool<MyClass> poolOfMyClass = new ObjectPool<MyClass>();
void Update()
{
MyClass m = poolOfMyClass.New();
// do stuff...
poolOfMyClass.Store(m);
}
这样比较繁琐,因为你需要记住在New()方法之后在正确的位置调用Store()方法。不幸的是,没有一种通用的方法来简化此设计模式的使用,因为不管是ObjectPool还是C#编译器都不知道对象什么时候可以被重新使用。恩,其实还有一种通过垃圾回收器自动管理内存的方法。这种方法的缺点在文章开始处你已经读过。也就是说,在幸运的情况下,你可以使用文章最后说明的“对象池全部重置”模式。那里,所有的Store()调用都会被替换为调用ResetAll()方法。
增加ObjectPool 类的复杂度
我是简洁代码(simplicity)的粉丝,大道至简。但是,ObjectPool 类现阶段可能有些太简单了。如果你搜索C#的对象池库,会找到很多解决方案,其中有些方案相当精妙且复杂。因此,退一步来思考我们需要或者不需要什么功能,比如通用的对象池查找功能。
许多对象类型在被重新使用之前需要以某种方式“重置”。至少,所有的成员变量都可以被设置为其默认状态。这些都是由对象池透明处理而非使用者。重置调用的时机和方式由下面两个设计特征决定:
积极重置(每次存储时重置)或者延迟重置(对象使用前重置)。
重置由池(由池处理,对类来说透明)或者类(对池对象的声明者透明)来管理。
在上面的例子中,对象池“poolOfMyClass”被显示声明为类成员变量。很明显,这样的对象池需要为每个新类型资源声明一个实例(My2ndClass等)。还有一种方案,ObjectPool类可以创建和管理这些对象池,而用户不用关心这些。
你在这里、还有这里可以找到几个对象池库,用它们来管理各种类型的资源(内存、数据库连接、游戏对象、外部assets等)。这往往会增加对象池代码的复杂度,因为,不同资源的处理逻辑差别很大。
一些稀缺资源类型(例如,数据库连接)对象池需要强制设定使用上限,并提供一种安全的方式来分配一个新的或者循环使用的对象。
如果对象池在某些时刻创建了大量对象,我们可能希望对象池有能力减少对象的创建(自动或者按命令)。
最后,对象池可以由多个线程共享,在这种情况下它必须是线程安全的。
上面这些特性哪些是值得实现的呢?我们都有自己的看法。但是,我来解释一下我自己的优先级。
重置功能必须有。但是,下面你会发现,完全没必要纠结重置逻辑是由对象池还是托管类来处理。你可能两者都需要,后文的代码分别实现了两种情况。
Unity强加了多线程限制。基本上,除了游戏主线程之外你还可以创建一个工作线程。但是,只有游戏主线程可以调用Unity的API。在我看来,这意味着我们可以为所有线程单独创建对象池,因此也可以移除“多线程支持”的需求。
就个人而言,我不介意为每个对象类型声明一个新的对象池。但是,还有一种方案:单例模式。ObjectPool类通过存储在静态变量中的对象池Dictionary创建和保存对象池实例。要让其正常工作,你必须保证ObjectPool类可以在多线程环境正常工作。然而,我至今为止也没有看到一个100%安全的多线程对象池解决方案。
在本篇教程中,我只关心对象池处理的一种稀缺资源类型:内存。但是,其它类型的对象池也很重要。只是超出了本教程的范围。
这里对象池不会强制设置最大限制。如果游戏消耗太多内存,说明游戏存在问题,这不是对象池要解决的问题。
同样,我们假定没有其它进程正在等待你尽快释放内存。这意味着重置是可以延迟的,而且对象池没有动态减少占用内存的功能。
带有初始化和重置功能的基本对象池
我们修正的ObjectPool <T>类如下所示:
[C#] 纯文本查看 复制代码
public class ObjectPool<T> where T : class, new() {
private Stack<T> m_objectStack;
private Action<T> m_resetAction;
private Action<T> m_onetimeInitAction;
public ObjectPool(int initialBufferSize, Action<T>
ResetAction = null, Action<T> OnetimeInitAction = null)
{
m_objectStack = new Stack<T>(initialBufferSize);
m_resetAction = ResetAction;
m_onetimeInitAction = OnetimeInitAction;
}
public T New()
{
if (m_objectStack.Count > 0)
{
T t = m_objectStack.Pop();
if (m_resetAction != null)
m_resetAction(t);
return t;
}else{
T t = new T();
if (m_onetimeInitAction != null)
m_onetimeInitAction(t);
return t;
}
}
public void Store(T obj) { m_objectStack.Push(obj); } }
这种实现非常简单明了,参数T通过“whereT:class, new()”指定了两种限制方式。第一,T必须是一个类(毕竟,只有引用类型需要对象池),第二,它必须有无参构造函数。
构造函数使用估测的最大值作为对象池的第一个参数。其他两个参数都是可选参数。如果有值,则第一个用来重置对象池,第二个用来初始化一个新的对象池。ObjectPool<T>除构造函数外只有两个方法:New()、Store()。因为,对象池使用的是延迟重置方法,所以,所有工作都在New()方法中,即重新创建或者循环使用对象被初始化或重置之后。这就是两个可选参数的设计目的。下面是继承自MonoBehavior的对象池类:
[C#] 纯文本查看 复制代码
class SomeClass : MonoBehaviour
{
private ObjectPool<List<Vector3>> m_poolOfListOfVector3 =
new ObjectPool<List<Vector3>>(32, (list) =>{
list.Clear();
},
(list) => {
list.Capacity = 1024;
});
void Update()
{
List<Vector3> listVector3 = m_poolOfListOfVector3.New();
// do stuff
m_poolOfListOfVector3.Store(listVector3);
}
}
如果你看过本系列教程的第一篇,就会知道从内存角度来说,在poolOfListOfVector3定义两个匿名委托函数是可以的。一方面,它们并非真的闭包而是“局部定义函数”,另一方面,这不重要因为对象池有类级别的作用范围。
可以让托管类型重置自身的对象池
对象池的基础版有了它应该有的功能,但它有一个概念性的缺陷。它违反了封装原则,没有把初始化/重置对象和对象类型的定义分开,导致了代码的紧耦合,这是应该要避免的。在上面的SomeClass 例子中,没有备选方案,因为我们不能改变List<T>的定义。然而,当你在对象池中使用了自定义类型对象,你可能希望它们执行IResetable 接口。相应地ObjectPoolWithReset<T>类也因此可以无需使用两个闭包作为参数(为了灵活性而保留的)。
[C#] 纯文本查看 复制代码
public interface IResetable
{ void Reset(); }
public class ObjectPoolWithReset<T> where T : class, IResetable, new()
{
private Stack<T> m_objectStack;
private Action<T> m_resetAction;
private Action<T> m_onetimeInitAction;
public ObjectPoolWithReset(int initialBufferSize, Action<T>
ResetAction = null, Action<T> OnetimeInitAction = null)
{
m_objectStack = new Stack<T>(initialBufferSize);
m_resetAction = ResetAction;
m_onetimeInitAction = OnetimeInitAction;
}
public T New()
{
if (m_objectStack.Count > 0)
{
T t = m_objectStack.Pop();
t.Reset();
if (m_resetAction != null)
m_resetAction(t);
return t;
}else{
T t = new T();
if (m_onetimeInitAction != null)
m_onetimeInitAction(t);
return t;
}
}
public void Store(T obj) { m_objectStack.Push(obj); } }
带有整体重置功能的对象池
游戏中有些数据结构可能绝不会持续超过一个序列帧,而是在每帧结束前被释放。在这种情况下,如果很好的定义了所有对象重新存入对象池的时间点,那么这个对象池将更易用,效率也会更高。让我们先看看代码。
[C#] 纯文本查看 复制代码
public class ObjectPoolWithCollectiveReset<T> where T : class, new()
{
private List<T> m_objectList;
private int m_nextAvailableIndex = 0;
private Action<T> m_resetAction;
private Action<T> m_onetimeInitAction;
public ObjectPoolWithCollectiveReset(int initialBufferSize, Action<T>
ResetAction = null, Action<T> OnetimeInitAction = null)
{
m_objectList = new List<T>(initialBufferSize);
m_resetAction = ResetAction;
m_onetimeInitAction = OnetimeInitAction;
}
public T New()
{
if (m_nextAvailableIndex < m_objectList.Count)
{
// an allocated object is already available; just reset it
T t = m_objectList[m_nextAvailableIndex];
m_nextAvailableIndex++;
if (m_resetAction != null)
m_resetAction(t);
return t;
}else{
// no allocated object is available
T t = new T();
m_objectList.Add(t);
m_nextAvailableIndex++;
if (m_onetimeInitAction != null)
m_onetimeInitAction(t);
return t;
}
}
public void ResetAll() { m_nextAvailableIndex = 0; } }
改写之后的版本与最初版本基本一致。只是Store()被ResetAll()取代,这样当所有创建的对象被存入对象池时只需要调用一次。在类的内部,存储所有(甚至是正在被使用的)对象引用的Stack<T>被替换为List<T>,我们在list中也跟踪记录了最近被创建或释放对象的索引。那样的话,New()可以知道是要创建一个新的对象还是重置一个已存在对象。
再次申明,此文档为转载,非常感谢总结此文章的博友,写的特别好,和全面!!!