性能测试艺术
介绍
本文地址:http://my.oschina.net/u/1433482/blog/634047。
交流:python开发自动化测试群291184506 PythonJava单元白盒测试群144081101
英文原版书籍下载:https://bitbucket.org/xurongzhong/python-chinese-library/download。
精品文章推荐:
python 2.7 中文教程及自动化测试介绍
使用Python学习selenium测试工具
为什么要进行性能测试?
什么是好的与坏的性能?为什么性能测试在软件开发生命周期(SDLC software development life cycle)中很重要?
性能不佳的应用通常无法实现企业预期利益,花费了大量时间和金钱,但是却在用户中失去了信誉。
相比功能测试和验收测试(OAT operational acceptance testing),性能测试容易被忽略,往往在发布之后碰到性能和扩展性问题才意识到重要性。
最终用户眼中的性能
性能”是用户最终的感受。性能优异的应用在最终用户执行某项任务时不会产生过度的延迟而引起用户的不满。好的应用不会在登录时显示空屏,不会让用户走神。比如偶然的用户在购物网站上寻找和购买他们所需要的东西时,客户中心不会收到差性能的投诉。
多 数应用系统在峰值时性能表现不佳。从高层看,应用由客户端软件和基础设施组成,后者包括了运行软件所需的服务器硬件和网络基础设施。另外有些应用还有第3 方服务。任何一个组成部分中出现问题,整个系统的性能就将面临灾难。您可能会简单地认为,为了保证应用性能,观察应用每个部分在负载压力下的运行状况并且 解决所出现的问题即可。这种做法往往“太少”和“太迟”了,因此只能是治标不治本。
性能度量
关键业绩指标(KPIs key performance indicators)有服务和效率两种。
基于服务的:衡量应用系统为用户服务的好坏。
可用性(Availability): 终端用户可以使用的应用的总时间。可用性很重要,小小的故障也会导致大量的商务上的花费。用户无法有效地使用该应用系统,比如应用不响应或者响应慢到无法接受。)
响应时间(response time):一般指系统响应时间。即用户发起请求到收到结果的时间。响应有异步和同步两种。
基于效率的:衡量应用对基础设施的利用。
吞吐量(Throughput):应用处理速度,比如一定时间内某个页面的点击数。
利用率(Utilization):理论资源的使用率。当1000个用户同时在线时,应用消耗了多少网络带宽及在服务器内存和cpu等使用情况。
性能标准
没有正式的行业标准,但是有许多非正式的标准,试图对系统的性能好坏做出评价,尤其是B/S应用。比如“页面最小刷新时间”从20秒到8秒,现在是2秒最佳。用户和企业都希望系统能够“即时响应”,但现在这样的性能很难达到的。
(Martin et al.,1988)的研究表明:
超过15 秒:基本上不适合交互。某些特定的应用,一些用户可能坐在终端等待超过15秒的时间去等待查询结果的返回, 比如公安局的网上预约系统。然而繁忙的呼叫中心运营商或期货交易商,超过15 秒无法容忍的。如果真的发系统就应该设计成可以让用户转向其他的操作,后面异步响应。
超过4秒:对于要求用户保存短暂记忆里的会话来说太长,当然交易完成之后,4-15秒的延迟是可以忍受的。
2-4 秒:超过2秒很难引起用户的高度关注。买家在输入了她的地址和信用卡号码后等待2-4秒的时间可以接受。然而如果是在早先的阶段,当她正在比较不同产品的差异时,却又是不可容忍的。
低于2 秒: 用户需要记住几个响应信息时,响应时间必须很短,如果要记住更为详细的信息,则要求就更高了。
亚秒: 思想密集型的工作来说(比如写一本书),尤其是一个图形应用程序,响应时间要非常短才能够保持用户的兴趣和长时间的关注。当艺术家将图片拖曳到另一个位置时,程序必须能够立即响应。
马上响应:按键并在屏幕上出现相应的字符,或者用鼠标点击,这种响应必须几乎是瞬时的。比如游戏。
由此可见,响应时间临界点是2秒。
糟糕的性能:为何如此普遍?
IT 商业价值曲线

性能问题通常会比较晚才发现,而且越晚发现,解决成本就越高。
实线(计划)表示预期结果。方块表示部署。虚线(实际)表示实际结果,延迟上线,上线后因为性能问题产生负面效果。
性能测试成熟度
Forrester在 2006年对典型应用系统上线后发现的性能缺陷进行了调查:
图中定义了三种性能测试。
 第一种是救火(Firefighting),发布前很少或从来没有性能测试。所有性能缺陷在生产环境上发现解决。这是最不可取的,却依然比较普遍。
第一种是救火(Firefighting),发布前很少或从来没有性能测试。所有性能缺陷在生产环境上发现解决。这是最不可取的,却依然比较普遍。第二种是性能验证(performance validation)。公司为性能测试在产品的后期安排了时间,生产环境会发现30%左右的性能bug。这个当前绝大多数公司的做法。
第三种是性能驱动(performance driven),生命周期中的每一阶段都考虑了性能, 生产环境会发现5%左右的性能bug。
系统设计阶段缺少性能方面的考虑
设计的时候考虑性能有望产出好性能的应用,至少也能使应用在出现意想不到的性能问题时灵活地能进行修改或重新配置。设计相关的性能问题后期才发现就很难解决,有时候甚至需要重新开发。
多数的应用基于可独立测试的组件进行开发的,组件在单独执行的时候性能可能都不错,切记必须从整体来考虑。这些组件之间的交互必须高效且扩展性好,集成后才会有好的性能。
直到最后一刻才进行性能测试
性能验证模式下,性能测试直到系统发布前才会进行,并且很少考虑到性能测试所需的时间及失败后所造成的后果。可能无法发现一些严重的性能缺陷或发现了性能问题但却没有时间解决。
扩展性
可能忽略了用户的地理分布和规模等。需要考虑如下问题:
有多少终端用户会实际使用?
用户位于何处?
多少用户会同时使用?
用户如何连接到应用?
后期有多少额外的用户需要访问应用?
应用的服务器数量及网络拓扑?
将应用对网络容量产生什么影响?
了解流行度
很多公司低估其应用的人气,人是好奇的,系统发布的第一天,你估计1万次点击,结果却是100万次点击,您的应用系统就这样崩溃了!需要考虑高峰访问。
令人震惊的失败:一个真实的例子
在很多年以前,英国政府决定在互联网上公布1901年人口普查的结果。这涉及到大量的将旧文档转换成现代的数字格式文档的工作,并且还需要创建一个应用以供公众访问。
很多希望了解家族历史,24小时之后网站崩溃了。在之后的几个星期里始终无法访问,直到最后重新发布。
性能测试还不规范
目前性能调优的书籍很多,但是对医生而言,最重要的是识别病情,识别性能瓶颈比解决问题有时更难。
不使用自动化的测试工具
不使用自动化的测试工具和自动化:单单使用手工是很难完成性能测试的。
应用程序使用技术的影响
应用程序使用技术的影响:某些新技术不太方便进行测试。
如何选择性能测试工具?
web方面的测试工具比较多。但是非web的,尤其是涉及到加密和压缩的,就很少了,甚至是https,很多工具都处理不好。
性能测试工具架构
常见的性能测试工具架构:
脚本:描述用户的活动,支持不同协议。
测试管理模块: 创建并执行性能测试会话或场景。
负载生成器: 生成负载。
分析模块: 分析数据,有些还有自动分析的专家模式。
其他模块: 监控服务器和网络性能的同时,与其他软件集成。

选择性能测试工具
选择性能测试工具:
除了HTTP/S支持比较广泛,JavaScript, JSON和 Microsoft Silverlight就不一样了。
协议支持
授权:比如最大虚拟用户数;能支持的额外协议;附加插件集成和特定的技术栈监控,比如Oracle, Python等,)可以与APM(application performance monitoring)与CI(continuous integration)集成。
脚本支持:稍微复杂一点的测试就需要深入脚本。考虑脚本修改的难度;考虑测试团队的技术水平,比如团队如果有python高手,直接用python功能会比具体的工具要强大得多。
解决方案与负载测试工具: 有些厂商只提供个负载测试工具,而有些提供性能测试解决方案。解决方案产花费更多,但通常功能更强大,可能包括自动需求管理,自动数据创建和管理,预性能 测试的应用程序调试和优化,响应时间预测和容量建模,APM提供类和方法层面的分析,集成用户体验(EYE)监控,管理测试结果和测试资产等。
外包:可以免去工具选型等。但是次数太多的成本太高。
其他:基于云平台的测试。节约硬件成本。缺点:次数太多的成本太高,性能指标监控未必方便。程序不稳定时代价很高。
备注:Loadrunner之类的性能测试工具,中文化和文档都做得不错,对于通用的http协议效果也可以。但是扩展性差、效率低下、价格极其昂贵。所以一般认为一谈性能就谈Loadrunner的人没有真正入门性能测试。功能测试的QTP也和Loadrunner类似。
性能测试工具集:概念验证(POC Proof of Concept)
POC至少要有两个用例:读数据和写数据。目的如下:
对性能测试工具是否适合目标应用进行技术评估。
识别脚本数据要求
评估脚本需要的编写和修改时间
展示测试工具的容量。
POC检查表
一般不建议超过2天。
准备:
成功或退出标准,客户已经签字。
工具的软硬件准备ok。
安装任何需要监控软件的权限。
理想情况下保证环境专有性
应用技术支持:产品专家。
应用技术支持:技术专家(比如开发)可以咨询或者应用中间件级别的架构宣讲。
用户帐户:可以安装访问
至少两套凭据登录目标应用程序。因为需要并发执行等。
两个用例,简单的读和复杂的写。
过程
录制用例并比较异同,注意运行时和会话数据等。
修改脚本,确认用户和多用户模式都可以执行,结果正确。确保脚本无内存泄露等不良行为。
交付:
通过或者不通过
生成了数据需求。
脚本开发时间
如果是售前,要能说服客户
有效应用性能测试的基础
需要考虑的问题:
发布时要支持多少用户?6个月,12个月,2年后呢?
用户分布及如何将它们连接到应用?
发布时用户的并发? 6个月后,12个月,2年后呢?
回答会引出一些问题, 比如:
每个应用层需要的服务器规格及数量是什么?
服务器的位置?
网络基础设施的类型?
回答不出来没有关系,但是你已经开始考虑容量和扩展性了。从广义上讲,功能需求定义系统是应该做什么,非功能需求定义系统是什么样子(来自维基百科)。在软件测试中,性能测试基于基准衡量系统对性能和容量质量,包括以下内容:
项目计划
应用够稳定
足够的时间
代码冻结
基本的非功能需求
设计合适的性能测试环境
设置现实合适的性能目标
确定并脚本化的关键use case
测试数据
负荷模型
精确的性能测试设计
KPI(Key Performance Indicator)
应用准备OK
功能要运行稳定,不能10次运行,2次失败。避免性能测试成为频繁的bug修改实践。功能等问题会掩盖性能问题。要有严格的单元和功能测试保证。衡量标准如下:
大量数据(High data presentation):比如大量图片和冗余会话。
低效SQL(Poorly performing SQL): 比如下图:

大量应用的网络来回:容易导致延迟、带宽限制和网络拥塞等。
应用错误:比如HTTP 404,500等。
足够的时间
以下工作需要时间:
准备测试环境
配置负载注射器
识别user case(数天到数周)和脚本化
确定和创建测试数据(数天到数周)
测试环境安装配置
问题解决
代码冻结
不冻结可能会导致脚本失效或不能代表用户行为等。
设计性能测试环境
理论上要与生产环境完全一致,但是很多原因导致不太可能,下面列出部分原因:
服务器的数量和规格: 服务器内容和架构难以复制,尽量保持规格一致,以方便提供基准。
带宽和网络基础设施:地理位置难以复制。
部署层次:建议完全一致。
数据库大小:建议完全一致。
也有公司直接在生产环境同时部署测试环境或者直接拿生产环境做性能测试,后者注意不要影响用户,包含数据和服务等。
性能测试的环境类型有:
生产环境非常接近的副本:通常不太现实。
生产环境的子集,层次一致,服务器规格一致,但是数量有所减少:建议达到的方案。
生产环境的子集,层次有缩减,服务器规格一致,但是数量有所减少:最常见的方案。
虚拟化
虚拟化的概念请参考:https://en.wikipedia.org/wiki/Virtualization 和 https://en.wikipedia.org/wiki/Docker_(software) 等。 注意:
虚拟机管理程序层有管理开销
总线和网络的通信方式不同。前者没有带宽和延迟限制。在网络跨地理位置的情况尤其需要注意。建议虚拟化与生产环境一致。特别注意不要跨层虚拟化在同一机器。
物理与虚拟NIC:后者的开销更大。
云计算
可以简单理解云计算为商品化的虚拟主机,它便宜,容易部署。相关概念介绍参见:https://en.wikipedia.org/wiki/Cloud_computing 。
优点:
可以生成大量负载注射器。
便宜
快速
可扩展
易部署
缺点
不及时关闭很贵
有时不可靠,比如配置的机器无法启动,IP被墙等。
负载注入容量
单机能模拟的虚拟用户是有限的,特别注意测试机的CPU和内存等使用率不要过载,尽量使用多的机器机进行测试。注意以下几点:
负载均衡:一些基于IP分配服务器。所以必要的时候需要使用IP欺骗。
用户会话限制:比如一个IP只能一个会话。
其他问题:
有些中间件不能用脚本表示。解决办法,从表示层入手;改用瘦客户端;自行开发工具。
衡量表示层性能:性能测试通常工作在中间件层。比如想计算用户点击复选框的时间,建议使用前端测试工具。
网络部署模式
广域网的速度通常只有256 Kb左右,网络延迟也比较大。延迟的产生基于光速:1ms/130公里以及交换机、路由器等网络设备和服务器的时延。
如果有必要,可以:1,从WAN进行性能测试;2,测试工具模拟;3,网络模拟。
环境检查表
服务器数:物理或虚拟服务器的数量。
负载均衡策略:负载均衡机制的类型。
硬件清单:CPU的类型和数目,内存,网卡的类型和数量。
软件清单:标准版本的软件清单(不包括中间件)。
中间件清单。
内部和外部链接
软件安装约束
比如安全考虑。
务实的性能目标
目标部分来自服务级别协议(SLA service-level agreement)。无论如何目标必须明确。
一致
一致且尽早介入。
业务
C级管理负责预算和策略决定:
•首席信息官(CIO Chief information officer)
•首席技术官(CTO Chief technology officer)
•首席财务官(CFO Chief financial officer (CFO))
•部门负责人
IT
•开发人员
•测试
•架构团队
•服务提供者(内部和外部)
•终端用户
•IT或运维
性能目标定义
主要包含可用性、响应时间、吞吐量、并发、网络利用率和服务器利用率。
在性能测试中并发是同时在线的用户。要注意并发虚拟用户和并发实际用户不一定是同一回事。估算时需要基于二八原理和峰值等。
吞吐量通常更适合衡量无状态的行为。比如浏览购物时通常不会登录,看中之后才会登录,浏览购物可以认为是无状态的。
响应时间不要随着并发的增加而大幅度增加,可以基于单个用户做基准测试。
网络利用率需要关注数据量、数据吞吐量(可能会导致吞吐量突然下降是容量问题)和数据错误率。
服务器利用率主要关注CPU、内存和I/O(磁盘和网络等)
确定和脚本化关键业务user case
关键的user case一般不会超过10个。
Use-Case检查表
记录每个步骤
输入数据和期望的响应
用户类型:新的或老用户,超级用户,客户,客服等类型。
网络:LAN或WAN
主动还是被动
脚本验证
基于抓包工具或录制工具书写脚本,然后单用户到多用户调通。注意脚本不要影响到并发的执行,尽量使用不同的用户等。
检查点
业务较复杂时尤其重要。
是否需要登入登出
尽量符合实际情况。
共存
注意共存的应用和网络共享
测试数据
输入数据
用户凭据:比如用户名和密码。
查找规则:通过客户的姓名和详细地址,发票号和产品码甚至是通配符进行查询。
相关文件:比如图片。
目标数据
需要考虑数据容量是否符合规格的大小,数据回滚等。
会话数据
比如token。
数据安全
数据要保密,同时性能测试工具要实现与服务器端通信的加密方式。
性能测试设计
性能测试的类型
1.pipe-clean测试。
2.容量测试。尽量接近用户实际使用。
3.隔离测试。
4.压力测试。退出标准:没有更多的用户可以登录,响应时间难以接受,或应用程序变得不可用。
5.浸泡测试,又叫稳定测试。发现内存泄漏等问题。
6.冒烟测试,只测试修改的部分。注意和其他地方的概念不一样。
pipe-clean, volume, stress和soak test通常都需要进行。
负载模型
负载模型定义了user case的负载分布及并发和吞吐量的目标。通常先基于容量测试,再扩展到其他类型。注意测试数据、思考时间和步长的影响。比如搜索数据分类:
小数据模型:具体的产品名称或ID。
中数据模型:局部产品名称。
大数据模型: 通配符或最小的产品名称的内容。
需要模拟真实情况下各种user case的分布:

吞吐量模型对于已有一个用需要参考Google Analytics或WebTrends,新应用的需要估计。
思考时间代表着延迟和暂停。
步长是循环之间的间隔。
负载注入方式有:Big Bang、Ramp-up、Ramp-up (with step)、Ramp up (with step), ramp down (with step)、Delayed start。注意"with step"主要是为了方便观察。

KPI
服务器KPI
Windows 性能工具。Linux有monitor、top,、vmstat、sar等工具。监控分为业务层、中间件层和系统层等。
通用模板如下:
• Total processor utilization %
• Processor queue length
• Context switches/second
• Available memory in bytes
• Memory pages faults/second
• Memory cache faults/second
• Memory page reads/second
• Page file usage %
• Top 10 processes in terms of the previous counters
• Free disk space %
• Physical disk: average disk queue length
• Physical disk: % disk time
• Network interface: Packets Received errors
• Network interface: Packets Outbound errors
Web和应用服务器层:比如nginx、WebLogic、WebSphere、Apache、JBOSS等。
数据库层:比如MYSQL、Oracle等。MongoDB, Cassandra和DynamoDB可以视为应用设计的一部分。
大型主机层:比如Strobe、Candle
主机层:比如亚马逊的CloudWatch。
网络层:网络错误、延迟、带宽。
应用监控
性能测试过程
性能测试的方法
范围和非功能需求捕捉:通常需要几天。
性能测试环境准备
user case脚本化:一个user case通常需要半天。
创建和验证性能测试场景。1-2天。前提是创建了精确的负载模型,定义每个性能测试的结构和内容。
执行性能测试。通常需要5天左右。如果频繁重测,耗时更多。
收集数据和卸载软件。通常需要1天左右。
最后分析和报告。通常需要2-3天左右。
非功能需求分析
先决条件如下:
性能测试的截止期限
内部或外部资源OK。
测试环境的设计。尽量接近真实环境。
代码冻结。
专有的测试环境,
目标。
关键用例。识别、记录并准备脚本。
用例中的检查点。
选择的use case的输入、目标和会话数据。同时还需要考虑数据安全。
负载模型OK。
性能测试场景的数量、类型、use-case内容和虚拟用户的部署已经确定。还可能需要考虑时间,步长,注入细节等。
识别和记录应用、服务器和网络的KPI。注意需要关注基础设施。
性能测试的输出。
bug提交方式。涉及测试团队成员和报告结构。工具、资源、技术和授权。另外还有培训,在外包的时候尤其重要。常见的架构如下:

基于上述信息,可以输出:
1.制定包括资源,时间线和里程碑的高层计划
2.包括所有的依赖、相关时间线、详细的场景和use case,负荷模型和环境信息的性能测试计划。
3.风险评估。
另外还需要注意迭代。
性能测试环境准备
步骤如下:
1.足够的时间来采购设备,配置和构建环境。
2.考所有部署模型要在LAN和WAN环境实验。
3.考虑外部链接。
4.提供足够的负荷注入容量。比如云主机。
5.确保应用正确部署到测试环境。
6.软件授权。
7.部署和配置性能测试工具。
8.部署和配置KPI监控。
Use-Case脚本
针对每个user case:
•确定会话数据的要求。其中一些可能来自概念验证(POC)。
•确认并应用输入数据的要求。
•检查点。
•修改脚本
•脚本单用户和多用户都可以执行。
性能测试场景构建
• 测试类型是什么(pipe-clean, volume, soak, or stress?),通常是针对user case进行单个用户(pipe-clean)测试,产生基线数据。然后加大并发和吞吐量。之后进行混合user case的容量测试。然后可能有soak和stress测试,最后还可能结合负载均衡和容灾等测试。
•思考时间和步长(尤其是压力测试)。
•负载注射器和虚拟用户的数量。
•注入方式:Big Bang, ramp-up, ramp-up/ramp-down with step, or delayed start。注意这几种方式可能是连接的。比如下图:

•测试执行控制:执行一段时间段、到达一定界限或测试数据耗尽停止或是用户介入。
•是否需要IP欺骗?
•您是否需要模拟不同的波特率?
•监控需求。
•Web的性能测试需要考虑浏览器缓存。还需要考虑新用户,活跃用户,回归用户等。
•技术影响,比如SAP比较消耗资源。
性能测试执行
1.pipe-clean测试。
2.容量测试。
3.隔离测试
4.压力测试。
5.浸泡测试,发现内存泄漏等问题
6.其他测试,比如负载均衡,容灾等。
性能测试分析和报告
•进行最后的数据收集(可能有软件卸载)。数据要有备份。
•比较试验结果与目标,决定是否通过。
•测试报告。
性能测试分析
相关术语
平均值和中值
标准偏差和正态分布: 高标准偏差表示用户体验不好。

百分比
响应时间分布

吞吐量不能增加,一般有瓶颈存在:

远 程监控:Windows注册表、Web-Based Enterprise Management (WBEM)、Simple Network Monitoring Protocol (SNMP)、Java Monitoring Interface (JMX)、Rstatd(传统的基于RPC的监控工具)
客户端需要关注:CPU百分比、内存使用、页利用率、磁盘时间、磁盘空间。
查找原因
好的扩展性与响应时间:

差的扩展性与响应时间:


特别注意值的突然跳跃,一般是有瓶颈存在。另外服务器的基线数据也可供参考。
检查表
性能测试与移动端
移动端的类型
移动网站
移动应用
混合移动应用
m. site: 很少用,IOS中用来避免Apple App Store,像移动应用,但是实质是移动网站。
设计考虑
耗电量:
运行一定时间,观察耗电量;
与其他应用同时使用,观察耗电量排行。
网络:
异步:
测试考虑
兼容性:系统、浏览器等组合。
API测试。
移动测试设计
移动网站:考虑浏览器。可以参考Google Analytics。
移动应用:考虑API。

混合移动应用
m. site: 很少用,IOS中用来避免Apple App Store,像移动应用,但是实质是移动网站。
终端用户体验监控与性能
主动监控
测试需要考虑:


参考网络图如下:

主动监控主要关注:可用性和响应时间。
Multi-Mechanize简介
Multi-Mechanize 是一个开源的性能和负载测试框架,它并发运行多个 Python 脚本对网站或者服务生成负载(组合事务)。测试输出报告保存为HTML或JMeter的兼容的XML。Multi-Mechanize最常用于web性能 和可扩展性(scalability)测试,也适用于任何python可以访问的API。尤其适合后台性能测试。稍微懂点编程的话,这个工具会远强过商业 的性能测试工具。
主要特性:
支持各种 HTTP methods
高级超链接和HTML表单支持
支持 SSL
自动处理 Cookies
可设置HTTP头
自动处理重定向
支持代理
支持 HTTP 认证
安装
使 用标准的python安装方式。注意,需要安装matplotlib以支持作图,在centos6下面可以这样安装yum -y install python27-matplotlib。multi-mechanize采用标准的python安装方式pip install multi-mechanize或者easy_install multi-mechanize这里都以linux(centos)为例。
centos 5 安装注意:
注意安装依赖: python26 python26-devel python26-numpy* python26-tornado
要EPEL支持: http://dl.fedoraproject.org/pub/epel/5/x86_64/epel-release-5-4.noarch.rpm
快速入门
创建项目
# multimech-newproject my_project
执行项目
# multimech-run my_project user_groups: 2 threads: 6 [================100%==================] 30s/30s transactions: 119 timers: 119 errors: 0 waiting for all requests to finish... analyzing results... transactions: 125 errors: 0 test start: 2013-09-13 11:47:47 test finish: 2013-09-13 11:48:16 created: ./my_project/results/results_2013.09.13_11.47.46/results.html done.
如果有出现figure没有定义,请在相关文件的头部从matplotlib导入。
测试结果参见:
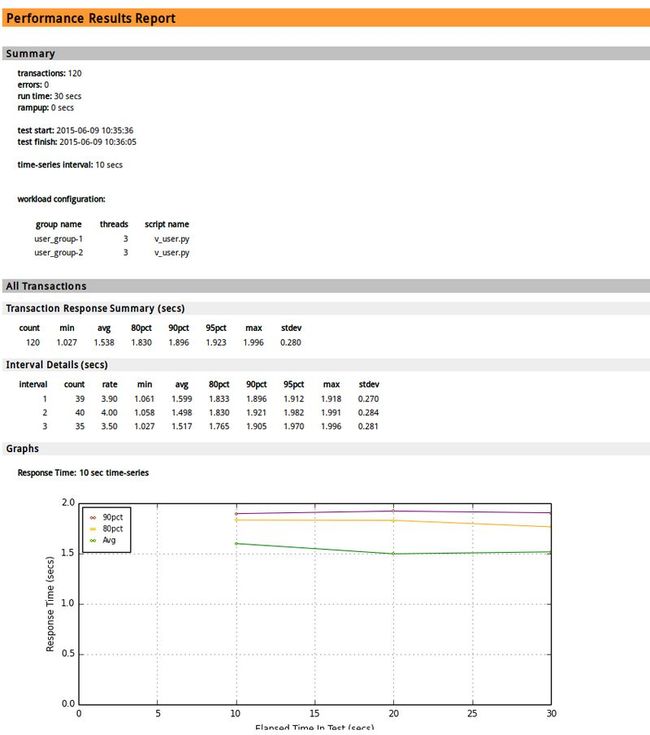
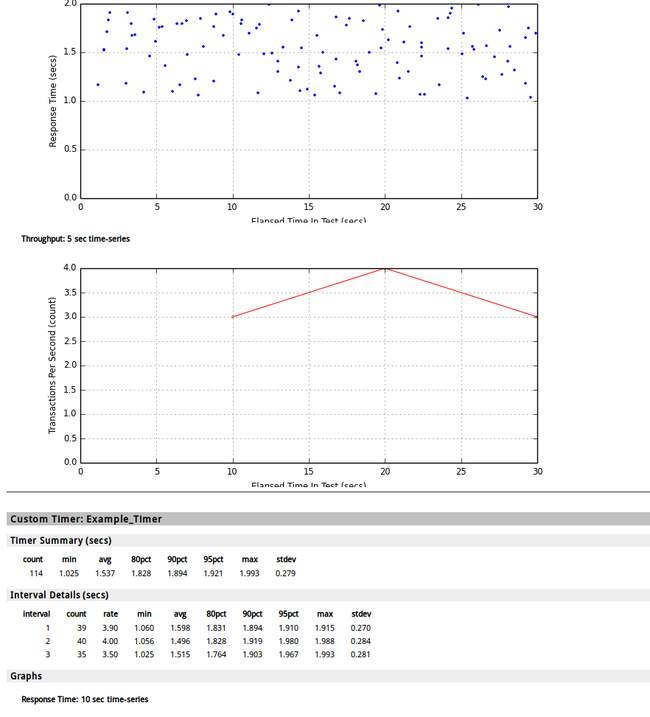
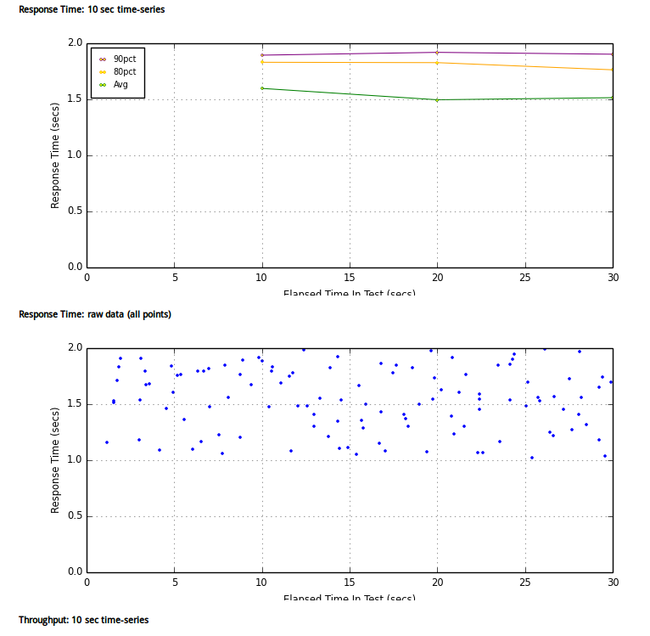
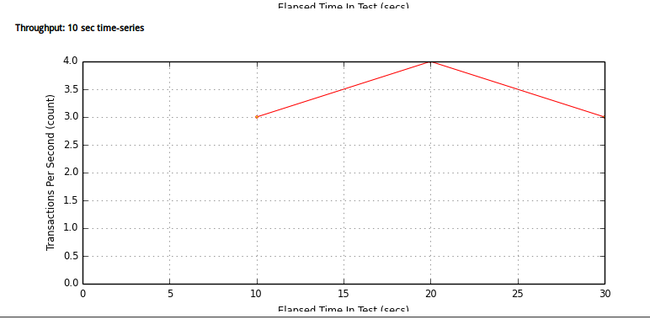
目录结构
每个测试项目包含以下内容:
config.cfg的配置文件。用于设定测试选项。
test_scripts/虚拟用户脚本的目录。在这里添加您的测试脚本。
results/:结果存储目录。对于每个测试都声称一个时间戳目录,里面包含结果的报告。
multimech-newproject,默认生成一个随机数的脚本。脚本v_user.py如下:
import randomimport timeclass Transaction(object): def __init__(self): pass def run(self): r = random.uniform(1, 2) time.sleep(r) self.custom_timers['Example_Timer'] = rif __name__ == '__main__': trans = Transaction() trans.run() print trans.custom_timers
配置参数的含义如下:
run_time: duration of test (seconds) 测试的执行时间
rampup: duration of user rampup (seconds) 多少秒内发完请求
results_ts_interval: time series interval for results analysis (seconds) 结果分析时间
progress_bar: turn on/off console progress bar during test run 是否显示进度条
console_logging: turn on/off logging to stdout 是否输出到stdout
xml_report: turn on/off xml/jtl report 是否生成xml报告。
results_database: database connection string (optional) 保存结果的数据库连接字符串(可选)
post_run_script: hook to call a script at test completion (optional) 调用的善后脚本(可选)
更多介绍参见: http://testutils.org/multi-mechanize/configfile.html
脚本书写
用Python书写,测试脚本模拟虚拟用户对网站/服务/ API的请求,脚本定义了用户事务,更多内容参见脚本手册:http://testutils.org/multi-mechanize/scripts.html#scripts-label。
每个脚本必须实现一个Transaction()类。这个类必须实现一个run()方法。基本的测试脚本结构如下:
class Transaction(object): def run(self): # do something here return
运行期间,Transaction()实例化一次,run()方法则反复调用:
class Transaction(object): def __init__(self): # do per-user user setup here # this gets called once on user creation return def run(self): # do user actions here # this gets called repeatedly return
从结构上看,如果每次run如果需要setup和teardown,时间也会计算在run里面,会显得事务处理的时间更长。这个就需要使用定时器来精确计时。
另外脚本建议先调试之后在运行,因为Multi-Mechanize有可能报错不够精准。可以这样运行:# python v_suds.py。v_suds.py是你实际使用的脚本名。另外suds这个库好像实现时性能一般,并发200时,客户端cpu占用率经常会100%,为此web service如果要上大量用户的话,建议用其他库替代,比如soapPy。进一步提升效率可以试用python的ctypes模块,或者cython(性能接近c语言)。不过Multi-Mechanize的多进程是基于python的,实在对性能有相当高的要求,就只能全部用c书写了。
下例使用mechanize进行web测试。
class Transaction(object):
def __init__(self):
pass
def run(self):
br = mechanize.Browser()
br.set_handle_robots(False)
resp = br.open('http://192.168.4.13/env.htm')
assert (resp.code == 200), 'Bad Response: HTTP %s' % resp.codes assert ('service name' in resp.get_data())
下面用httplib库重写脚本,并增加定时器。通过定时器,可以分析各个步骤的耗时。
import httplibimport timeclass Transaction(object):
def run(self):
conn = httplib.HTTPConnection('192.168.4.13')
start = time.time()
conn.request('GET', '/env.htm')
request_time = time.time()
resp = conn.getresponse()
response_time = time.time()
conn.close()
transfer_time = time.time()
self.custom_timers['request sent'] = request_time - start self.custom_timers['response received'] = response_time - start self.custom_timers['content transferred'] = transfer_time - start assert (resp.status == 200), 'Bad Response: HTTP %s' % resp.statusif __name__ == '__main__':
trans = Transaction()
trans.run()
for timer in ('request sent', 'response received', 'content transferred'):
print '%s: %.5f secs' % (timer, trans.custom_timers[timer])
http://testutils.org/multi-mechanize/scripts.html#scripts-label 还有更多的实例。
参考资料:
https://pypi.python.org/pypi/multi-mechanize/1.2.0
http://testutils.org/multi-mechanize
作者博客:http://my.oschina.net/u/1433482
类型:整理
boom:类似ab(ApacheBench)的性能测试工具
我们先对ApacheBench做个简介,再介绍boom。
ApacheBench
ApacheBench简介
ApacheBench 是一个用来衡量http服务器性能的单线程命令行工具。原本针对Apache http服务器,但是也适用于其他http服务器。
ab工具与标准 Apache源码一起发布,免费,开源,基于Apache License。
ApacheBench安装
ubuntu 14.04 执行“apt-get install apache2-utils“即可。
ApacheBench快速入门
发送1000个http get请求到http://192.168.10.232:8000/blog,并发为10:
# ab -n1000 -c10 http://192.168.10.232:8000/blogThis is ApacheBench, Version 2.3 <$Revision: 1528965 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.10.232 (be patient)Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Completed 1000 requests Finished 1000 requests Server Software: tracd/1.0.1Server Hostname: 192.168.10.232Server Port: 8000Document Path: /blog Document Length: 330918 bytesConcurrency Level: 10Time taken for tests: 1353.994 seconds Complete requests: 1000Failed requests: 0Total transferred: 331323000 bytesHTML transferred: 330918000 bytesRequests per second: 0.74 [#/sec] (mean)Time per request: 13539.943 [ms] (mean)Time per request: 1353.994 [ms] (mean, across all concurrent requests)Transfer rate: 238.97 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median maxConnect: 1 1 0.8 1 17Processing: 8703 13500 640.5 13586 15076Waiting: 8646 13387 641.6 13480 14957Total: 8704 13501 640.5 13587 15079Percentage of the requests served within a certain time (ms) 50% 13587 66% 13742 75% 13848 80% 13912 90% 14133 95% 14315 98% 14516 99% 14618 100% 15079 (longest request)
注意Time per request: 13539.943 [ms] (mean)是平均每批请求的完成时间,这里时10个请求完成的时间。Time per request: 1353.994 [ms] (mean, across all concurrent requests)是平均每个请求的完成时间。
ApacheBench将只使用一个操作系统线程。很多情况下ApacheBench本身是瓶颈。当在硬件具有多个处理器核心使用ApacheBench,建议一个cpu核执行一个ab线程,但是现在cpu核数很多的情况下,比如48核,手工执行48个命令也是个体力活。
整体来说ab因为不能利用到多核、不能进行参数化、不支持http和https以外的协议等原因,只适合单个组件的粗略测试,比如Apache http。不合适业务级别的测试,如一旦后台有数据库等,ab的测试是几乎没有意义的。
ApacheBench参考
命令行帮助
$ ab -h Usage: ab [options] [http[s]://]hostname[:port]/path Options are: -n requests Number of requests to perform -c concurrency Number of multiple requests to make at a time -t timelimit Seconds to max. to spend on benchmarking This implies -n 50000 -s timeout Seconds to max. wait for each response Default is 30 seconds -b windowsize Size of TCP send/receive buffer, in bytes -B address Address to bind to when making outgoing connections -p postfile File containing data to POST. Remember also to set -T -u putfile File containing data to PUT. Remember also to set -T -T content-type Content-type header to use for POST/PUT data, eg. 'application/x-www-form-urlencoded' Default is 'text/plain' -v verbosity How much troubleshooting info to print -w Print out results in HTML tables -i Use HEAD instead of GET -x attributes String to insert as table attributes -y attributes String to insert as tr attributes -z attributes String to insert as td or th attributes -C attribute Add cookie, eg. 'Apache=1234'. (repeatable) -H attribute Add Arbitrary header line, eg. 'Accept-Encoding: gzip' Inserted after all normal header lines. (repeatable) -A attribute Add Basic WWW Authentication, the attributes are a colon separated username and password. -P attribute Add Basic Proxy Authentication, the attributes are a colon separated username and password. -X proxy:port Proxyserver and port number to use -V Print version number and exit -k Use HTTP KeepAlive feature -d Do not show percentiles served table. -S Do not show confidence estimators and warnings. -q Do not show progress when doing more than 150 requests -l Accept variable document length (use this for dynamic pages) -g filename Output collected data to gnuplot format file. -e filename Output CSV file with percentages served -r Don't exit on socket receive errors. -h Display usage information (this message) -Z ciphersuite Specify SSL/TLS cipher suite (See openssl ciphers) -f protocol Specify SSL/TLS protocol (SSL3, TLS1, TLS1.1, TLS1.2 or ALL)
语法:
ab [ -A auth-username:password ] [ -b windowsize ] [ -c concurrency ] [ -C cookie-name=value ] [ -d ] [ -e csv-file ] [ -f protocol ] [ -g gnuplot-file ] [ -h ] [ -H custom-header ] [ -i ] [ -k ] [ -n requests ] [ -p POST-file ] [ -P proxy-auth-username:password ] [ -q ] [ -r ] [ -s ] [ -S ] [ -t timelimit ] [ -T content-type ] [ -u PUT-file ] [ -v verbosity] [ -V ] [ -w ] [ -x <table>-attributes ] [ -X proxy[:port] ] [ -y <tr>-attributes ] [ -z <td>-attributes ] [ -Z ciphersuite ] [http[s]://]hostname[:port]/path
命令行选项
-A auth-username:password 向服务器提供基本认证信息。用户名和密码之间":"分割,以base64编码形式发送。无论服务器是否需要(即是否发送了401)都发送。 -b windowsize TCP发送/接收缓冲区大小,以字节为单位。 -c concurrency 并发数,默认为1。 -C cookie-name=value 添加Cookie。典型形式是name=value对。name参数可以重复。 -d 不显示"percentage served within XX [ms] table"消息(兼容以前的版本)。 -e csv-file 输出百分率和对应的时间,格式为逗号份额的csv。由于这种格式已经"二进制化",所以比"gnuplot"格式更有用。 -f protocol SSL/TLS protocol (SSL2, SSL3, TLS1, 或ALL). -g gnuplot-file 把所有测试结果写入"gnuplot"或者TSV(以Tab分隔)文件。该文件可以方便地导入到Gnuplot, IDL, Mathematica甚至Excel中,第一行为标题。 -h 显示使用方法。 -H custom-header 附加额外头信息。典型形式有效的头信息行,包含冒号分隔的字段和值(如:"Accept-Encoding: zip/zop;8bit")。 -i 执行HEAD请求,而不是GET 。 -k 启用KeepAlive功能,即在HTTP会话中执行多个请求。默认关闭。 -n requests 会话执行的请求数。默认为1。 -p POST-file 附加包含POST数据的文件。注意和-T一起使用。 -P proxy-auth-username:password 代理认证。用户名和密码之间":"分割,以base64编码形式发送。无论服务器是否需要(即是否发送了407)都发送。 -q quiet,静默模式。不在stderr输出进度条。 -r 套接字接收错误时不退出。 -s timeout 超时,默认为30秒。 -S 不显示中值和标准偏差值,而且在均值和中值为标准偏差值的1到2倍时,也不显示警告或出错信息。默认显示最小值/均值/最大值。(兼容以前的版本)-t timelimit 测试进行的最大秒数。内部隐含值是"-n 50000"。默认没有时间限制。 -T content-type POST/PUT的"Content-type"头信息。比如“application/x-www-form-urlencoded”,默认“text/plain”。 -v verbosity 详细模式,4以上会显示头信息,3以上显示响应代码(404,200等),2以上显示告警和info。 -V 显示版本号并退出。 -w 以HTML表格形式输出。默认是白色背景的两列。 -x <table>-attributes 设置<table>属性。此属性填入<table 这里 > 。 -X proxy[:port] 使用代理服务器。 -y <tr>-attributes 设置<tr>属性。 -z <td>-attributes 设置<td>属性。 -Z ciphersuite 设置SSL/TLS加密
结果分析字段
Server Software 返回的第一次成功的服务器响应的HTTP头。 Server Hostname 命令行中给出的域名或IP地址 Server Port 命令行中给出端口。如果没有80(HTTP)和443(HTTPS)。 SSL/TLS Protocol 使用SSL打印。 Document Path 命令行请求的路径。 Document Length 第一次成功地返回文档的字节大小。后面接受的文档长度变化时,会认为是错误。 Concurrency Level 并发数 Time taken for tests 测试耗时 Complete requests 收到成功响应数 Failed requests 失败请求数。如果有会打印错误原因 Write errors 写错误数 (broken pipe)Non-2xx responses 非2**响应数量。如果有打印。 Keep-Alive requests Keep-Alive请求的连接数 Total body sent: 传输的body的数据量,比如POST的数据。 Total transferred: 总传输数据量 HTML transferred: 累计html传输数据量 Time per request: 每批平均请求时间 Time per request: 每次平均请求时间。计算公式:Time per request/Concurrency Level。 Transfer rate 数据传输速率。计算公式:otalread / 1024 / timetaken。
boom
boom简介
boom是python替代ab的模块,并增加了部分功能。
boom安装
ubuntu 14.04 执行“pip install boom“即可,注意可能需要先执行"apt-get install libevent python-dev"。它使用Gevent创建虚拟用户,使用Requests发送请求。
boom快速入门
# boom -n1000 -c10 http://192.168.10.232:8000/blogServer Software: tracd/1.0.1 Python/2.7.3Running GET http://192.168.10.232:8000/blog Running 1000 times per 10 workers.[================================================================>.] 99% Done-------- Results --------Successful calls 1000Total time 1355.1412 s Average 13.5156 s Fastest 8.2434 s Slowest 15.3094 s Amplitude 7.0660 s RPS 0BSI Hahahaha-------- Status codes --------Code 200 1000 times.-------- Legend --------RPS: Request Per Second BSI: Boom Speed Index
Average:每批请求的平均处理时间。 Fastest:每批请求的最快处理时间。 Slowest:每批请求的最慢处理时间。 Amplitude:振幅,即最慢与最忙批次处理时间差。
boom参考
$ boom -h
usage: boom [-h] [--version] [-m {GET,POST,DELETE,PUT,HEAD,OPTIONS}]
[--content-type CONTENT_TYPE] [-D DATA] [-c CONCURRENCY] [-a AUTH]
[--header HEADER] [--hook HOOK] [--json-output]
[-n REQUESTS | -d DURATION]
[url]Simple HTTP Load runner.positional arguments:
url URL to hit
optional arguments:
-h, --help show this help message and exit
--version Displays version and exits.
-m {GET,POST,DELETE,PUT,HEAD,OPTIONS}, --method {GET,POST,DELETE,PUT,HEAD,OPTIONS}
HTTP Method --content-type CONTENT_TYPE
Content-Type -D DATA, --data DATA Data. Prefixed by "py:" to point a python callable.
-c CONCURRENCY, --concurrency CONCURRENCY
Concurrency -a AUTH, --auth AUTH Basic authentication user:password --header HEADER Custom header. name:value --hook HOOK Python callable that'll be used on every requests call
--json-output Prints the results in JSON instead of the default
format -n REQUESTS, --requests REQUESTS
Number of requests -d DURATION, --duration DURATION
Duration in seconds
结论
ab和boom在功能上远不及multi-mechanize和Grinder等主力python性能测试工具,甚至还比不上庞大且扩能能力差的loadrunner。只建议在对单个中间件的基准测试时使用。
参考资料
boom@pypi
boom homepage
ab命令参考
作者博客:http://my.oschina.net/u/1433482
类型:翻译加整理
locustio
什么是locustio?
Locust是易于使用、分布式的用户负载测试工具。用于网站(或其他系统)的负载测试,计算出系统可以处理并发用户数。
测试时大量蝗虫会攻击你的网站。每只蝗虫(或叫测试用户)可以自定义、测试过程由web界面实时监控。这能帮助测试并确定瓶颈。
Locust 完全基于的事件,单机可以支持数千用户。它不使用回调,而是基于轻量进程gevent, 能简单地实线各种场景。
特点
Python书写场景
无需笨重的UI或XML。仅仅是代码,协程而不是回调。
分布式,可扩展和,支持成千上万的用户
基于Web的用户界面
Locust有整洁HTML + JS用户界面,实时展示测试细节,跨平台和易于扩展。
可以测试任何系统
可控制
事件完全由gevent处理。
背景
我 们研究了现有的解决方案,都不符合要求。比如Apache JMeter和Tsung。JMeter基于UI操作,容易上手,但基本上不具备编程能力。其次JMeter基于线程,要模拟数千用户几乎不可能。 Tsung基于Erlang,能模拟上千用户并易于扩展,但它它基于XML的DSL,描述场景能力弱,且需要大量的数据处理才知道测试结果。
无论如何,我们试图解决创建蝗虫,当这些问题。希望以上都不是painpoints应该存在。
我想你可以说我们真的只是想在这里从头开始自己的痒。我们希望其他人会发现,因为我们做的是有益的。
作者
Jonatan Heyman (@jonatanheyman on Twitter)
Carl Byström (@cgbystrom on Twitter)
Joakim Hamrén (@Jahaaja on Twitter)
Hugo Heyman (@hugoheyman on Twitter)
License: MIT
安装
安装:"pip install locustio"或者"easy_install locustio"
检验:
执行"locust --help"能看到如下信息表示安装成功:
# locust --help Usage: locust [options] [LocustClass [LocustClass2 ... ]] Options: -h, --help show this help message and exit ...
主要需要 Python 2.6+,不支持python3。分布式测试还需要安装pyzmq。尽管locustio可以在Windows运行,但是考虑效率不推荐
快速入门
下面我们访问http://automationtesting.sinaapp.com/的首页和about页面。
编写脚本
#!/usr/bin/env python# coding=utf-8"""
Locust quickstart!
Copyright 2015.05.08 Rongzhong.Xu xurongzhong#126.com
http://automationtesting.sinaapp.com
"""from locust import HttpLocust, TaskSet, taskclass UserBehavior(TaskSet):
"""
Locust test class
"""
def on_start(self):
""" called when a Locust start before any task is scheduled """
self.login()
def login(self):
"pass"
pass
@task(2)
def index(self):
"http://automationtesting.sinaapp.com/"
self.client.get("/")
@task(1)
def about(self):
"http://automationtesting.sinaapp.com/about"
self.client.get("/about")class WebsiteUser(HttpLocust):
"""
The HttpLocust class inherits from the Locust class, and it adds
a client attribute which is an instance of HttpSession,
that can be used to make HTTP requests.
"""
task_set = UserBehavior
min_wait = 5000
max_wait = 9000
HttpLocust继承自Locust,添加了client属性。client属性是HttpSession实例,可以用于生成HTTP请求。
on_start为client初始化时执行的步骤。
task表示下面方法是测试内容,里面的数字执行比例,这里about页面占三分之一,主页占三分之二。
task_set指定client执行的类。min_wait和max_wait为两次执行之间的最小和最长等待时间。
启动
启动locust后台
# locust --host=http://automationtesting.sinaapp.com [2015-05-08 16:33:49,166] andrew-Hi-Fi-A88S2/INFO/locust.main: Starting web monitor at *:8089 [2015-05-08 16:33:49,167] andrew-Hi-Fi-A88S2/INFO/locust.main: Starting Locust 0.7.2
在浏览器启动locust
打开http://127.0.0.1:8089/,配置模拟的用户数"Number of users to simulate"和每秒发起的用户数"Hatch rate",提交执行测试。
这时在浏览器就可以看到实时的测试结果。点击浏览器上方的"stop”即可停止测试。
查看报告:
命令行按Ctrl + c , 可以显示一些摘要
# locust --host=http://automationtesting.sinaapp.com [2015-05-08 16:33:49,166] andrew-Hi-Fi-A88S2/INFO/locust.main: Starting web monitor at *:8089 [2015-05-08 16:33:49,167] andrew-Hi-Fi-A88S2/INFO/locust.main: Starting Locust 0.7.2 [2015-05-08 16:42:18,656] andrew-Hi-Fi-A88S2/INFO/locust.runners: Hatching and swarming 8 clients at the rate 2 clients/s... [2015-05-08 16:42:22,663] andrew-Hi-Fi-A88S2/INFO/locust.runners: All locusts hatched: WebsiteUser: 8 [2015-05-08 16:42:22,663] andrew-Hi-Fi-A88S2/INFO/locust.runners: Resetting stats ^C[2015-05-08 16:48:19,884] andrew-Hi-Fi-A88S2/ERROR/stderr: KeyboardInterrupt [2015-05-08 16:48:19,884] andrew-Hi-Fi-A88S2/INFO/locust.main: Shutting down (exit code 0), bye. Name # reqs # fails Avg Min Max | Median req/s -------------------------------------------------------------------------------------------------------------------------------------------- GET / 36 0(0.00%) 260 206 411 | 250 0.90 GET /about 17 0(0.00%) 199 146 519 | 170 0.10 -------------------------------------------------------------------------------------------------------------------------------------------- Total 53 0(0.00%) 1.00 Percentage of the requests completed within given times Name # reqs 50% 66% 75% 80% 90% 95% 98% 99% 100% -------------------------------------------------------------------------------------------------------------------------------------------- GET / 36 250 260 260 270 370 400 410 410 411 GET /about 17 170 180 180 200 290 520 520 520 519 --------------------------------------------------------------------------------------------------------------------------------------------
网页上可以下载csv文件,一个是调配记录,一个是请求记录。
# cat distribution_1431074713.45.csv "Name","# requests","50%","66%","75%","80%","90%","95%","98%","99%","100%" "GET /",36,250,260,260,270,370,400,410,410,411 "GET /about",17,170,180,180,200,290,520,520,520,519 "None Total",53,250,250,260,260,310,400,410,520,519 # cat requests_1431074710.05.csv "Method","Name","# requests","# failures","Median response time","Average response time","Min response time","Max response time","Average Content Size","Requests/s" "GET","/",36,0,250,260,206,411,9055,0.76 "GET","/about",17,0,170,199,146,519,4456,0.36 "None","Total",53,0,250,241,146,519,7579,1.12
其他:
指定测试文件启动:locust -f ../locust_files/my_locust_file.py --host=http://example.com
分布式测试时作为主测试机:locust -f ../locust_files/my_locust_file.py --master --host=http://example.com
分布式测试时作为从测试机:locust -f ../locust_files/my_locust_file.py --slave --master-host=192.168.0.100 --host=http://example.com。master-host的默认值是127.0.0.1。
locustfile
locustfile需要定义至少一个locust类。
Locust类
locust类代表用户。属性如下:
task_set属性
task_set属性指向定义了用户的行为的TaskSet类。
min_wait和max_wait属性
两次执行之间的最小和最长等待时间,单位:毫秒,即执行各任务之间等待时间。默认为1000,并且因此蝗虫永远等待1秒各任务之间如果min_wait和MAX_WAIT未声明。
用下面locustfile,每个用户将等待任务之间5到15秒:
weight属性
可以同时执行同一文件的多个locust:
# locust -f locust_file.py WebUserLocust MobileUserLocust
weight标识执行比例,这里WebUserLocust的执行次数3倍于MobileUserLocust:
class WebUserLocust(Locust): weight = 3 ....class MobileUserLocust(Locust): weight = 1 ....
host属性
URL的前缀(如"http://automationtesting.sinaapp.com”)。通常在命令行使用--host选项指定。也可以设置host属性,在命令行没有指定时作为默认值。
TaskSet类
TaskSet表示任务的集合。任务可以嵌套,比如:
Main user behaviour
Watch movie
Filter movies
Read thread
New thread
View next page
Reply
Index page
Forum page
Browse categories
About page
嵌套的python代码示例:
class ForumPage(TaskSet):
@task(20)
def read_thread(self):
pass
@task(1)
def new_thread(self):
pass
@task(5)
def stop(self):
self.interrupt()class UserBehaviour(TaskSet):
tasks = {ForumPage:10}
@task
def index(self):
pass
类嵌套示例:
class MyTaskSet(TaskSet): @task class SubTaskSet(TaskSet): @task def my_task(self): pass
HTTP请求
HttpLocust继承自Locust,添加了client属性。client属性是HttpSession实例,调用了requests,可以用于生成HTTP请求。 self.client设置了属性指向 self.locust.client。
get 和post示例:
# get
response = self.client.get("/about")
print "Response status code:", response.status_code
print "Response content:", response.content
# post
response = self.client.post("/login", {"username":"testuser", "password":"secret"})
注意失败的任何请求如连接错误,超时等不产生异常,而是返回None,status_code是0。
默认只要返回的不是2都是失败。也可以设置失败和成功:
with client.get("/", catch_response=True) as response:
if response.content != "Success":
response.failure("Got wrong response")
with client.get("/does_not_exist/", catch_response=True) as response:
if response.status_code == 404:
response.success()
动态参数:
# Statistics for these requests will be grouped under: /blog/?id=[id]
for i in range(10):
client.get("/blog?id=%i" % i, name="/blog?id=[id]")
分布式测试
主机使用--master,它不会模拟任何用户。实际测试机需要--slave和--master-host参数。通常一个cpu核可以执行一个从机。
master的参数还有: "--master-bind-host=X.X.X.X"和--master-bind-host=X.X.X.X。
从机的参数有:"--master-port=5557"。
参考资料
作者博客:http://my.oschina.net/u/1433482
locustio英文文档