实战-不在害怕表关联(实现50亿*150亿数据量的表关联)
业务场景:从俩张海量的数据表抽取出大量的数据进行表关联,实现俩表信息的关联(统计单个用户的人均分发)。
首先看下我们要进行操作的俩张表的数据量和存储结构吧
第一个表 DailyUsers_2015:
从图上我们可以看到,有51.8亿,320G的数据,分成128个分区,分区列是Part
第二个表 ResDownloadLog_2015:
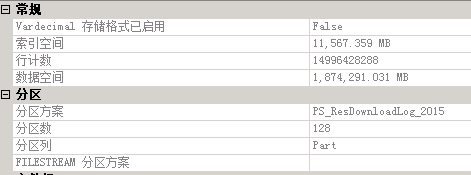
从上图我们可以看到,有149.9亿数据,1870G的数据,分成128个分区,分区列是Part
接下来我们就进行俩张表的关联操作,下面演示的是单个分区的表关联情况,玛丽((代)码例(子))1:
SELECT * from dbo.ResDownloadLog_2015 A with(nolock) inner join DailyUsers_2015 B on A.DownloadDate=B.LoginDate and A.SoftID=B.SoftID and A.IMEI=B.Imei and A.Platform=B.Platform and A.part=B.part and A.part=1 and B.part=1 and A.DownloadDate between 20150601 and 20150601 and A.IMEI!=''''
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'ResDownloadLog_2015'。扫描计数 1,逻辑读取 4174 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'DailyUsers_2015'。扫描计数 1,逻辑读取 894 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 2247 毫秒,占用时间 = 4119 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
所以单个分区时间t1=4.1,那么sum(t)=4*128=512s,9分钟不到。看到这样的结果很惊人吧。但是如果告诉你这俩个表每日数据还在递增。也就说我们在兼顾查询的性能的同时也要
兼顾插入的效率。你们会不会更加惊讶(没错,能操作这样数据量级别的数据是我的荣幸)。
玛丽1是一句平白无奇的Sql,但是结果确实惊人,但是上面显然不是最优的,了解一些Sql常识的人都是到 如果select *改成 select 所需字段,那么性能还会提高,特别在这种大数据量又是宽表的情况下,提升效果会更加更加的明显。当然这只是一个开始,如果在多核心的机子上,开启并行,这个时间最保守最保守还会有一个量级的提升,注意是一个量级的提升。
这就是优化的最终结果吗,NO!NO!NO!如果开启了数据的预加载还会有更好的提升(这也是memcache的最佳实践)。切记!后面俩绝招都是用在特殊场合,不可乱用,否则有自宫危险!
下面我们就来看看Sql和表的关系结构所造就的魔法吧,最简单且直接的方式就是看解释计划
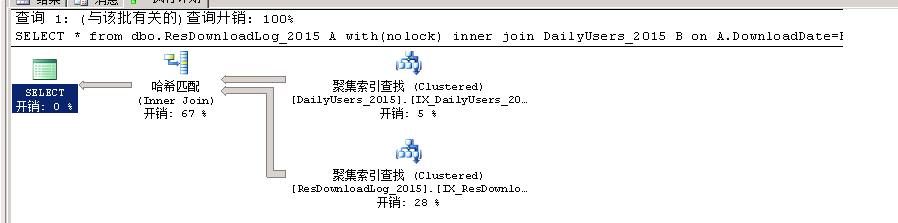
看到这个解释计划,很多人是不是想大声叫一句,哇靠,查询时间怎么那么少,大部分的时间在join上啊。理论上这样的大表查询速度应该很慢,在内存中的hash join 应该是很快的。
“是不是预估执行计划”
不是!给你们看的是真实执行计划!而且统计信息一点问题都没有(。。。给你么看的是15年的表)。
这里我想先说一个结论:深入理解业务需求,就是对SQL优化的极致,理解体系结构优化,就是把握SQL的优化的命门。
抛掉所谓 要exists 代替in ,select count(列)代替select count(*)这些所谓RBO优化,如果有人在用Oracle,Sql Server对你要记住这些,果断屏蔽掉他。
注意:mysql 现阶段还是基于RBO,CBO结合的优化。
好了,就来扯扯这俩张表是怎么设计的。
1 分表 拆解数据
上面虽然只展现了15年的表,当然还有13,14年的
2 分区表/分区索引 拆解数据,降低索引高度
上面赤裸裸展现了128个分区,你们看到的。part=hashcode(imei)%128,俩张表都是
看到这回不会又会问道,既然都是一个样的作用干嘛还要分表和分区?在数据库的存储结构里面,最小的存储结构是Block,但是每次申请数据空间是按区来申请空间
一个区由若干块组成,若干个区组成一个段。在无分区表,一个表只有一个段,在分区的情况下,表会被拆解成若干段。说道这里面应该懂了吧。不懂可以类比返向索引的作用。
3 建立聚集索引
按时间建立一个聚集索引,最大好处就是避免建立分聚集索引的回表查询的时间查询。所以在一个索引高度的IO次数下就可以完全找到数据载入到内存。还有一个极为重要的考量,在数据库插入的时候不是随机读写,索引构建不用进行叶子节点的重新分裂和组合,极大的提升了插入性能。
4 Hash Join
上图的代价确实大了,不过因为数据量庞大,不可能一次性在内存中做一次Join就实现内存簇的俩表之间的碰撞查找。内部不够磁盘担当,这当中的原理颇为复杂,需要在内存和磁盘之间频繁进行数据的交换。这边的开销主要的就是I/O开销了。
5 俩表都采用同一个字段作为分区列,所以在俩表的单个分区内就可以完全找到俩表所有匹配得数据,也就说是51亿/128 &149.9亿/128 的关联,既一个千万表&一个亿表数据的关联。大大缩减了数据量,减缓了I/O瓶颈,但是整个计算过程I/O还是瓶颈,这也是大数据数据计算的瓶颈(map reduce中 shuffle)