【数据结构排序算法系列】数据结构八大排序算法
写在前面的话:首先要明白在学习同类型的排序算法时,一定要明白任何相同领域存在的东西一定是竞争之后的结果,所以对于相同类型的排序之所以能够存在多种被人熟知,一定是因为它们各自存在各自的长处,可能是时间复杂度也可能是空间复杂度,也可能是因为稳定性。就像C,C++,Java它们之所以能同时存在,是因为在不同的领域它们的效率不同,所以学习排序算法时一定要知道同类型的排序的各自特点,如快速排序之于冒泡排序。
一.排序算法的归类:
总的排序算法分为以下几类:1.插入类排序:如:直接插入排序,折半插入排序,希尔排序
2.交换类排序:如:冒泡排序,快速排序,其中冒泡排序应该是计算机专业的学生最为熟悉的一种排序算法了,而快速排序则是在冒泡排序的基础上一次消除多个逆序对改进而来3.选择类排序:如:简单选择排序,堆排序。
4.其它类排序:如:归并排序,基数排序等。
二 各大排序的特点,如:时空复杂度,稳定性。

三各种排序详解
1交换类排序:
1.1冒泡排序:冒泡排序是通过对相邻的数据元素进行交换,逐步将待排序序列排成有序序列的过程。
如以升序为例(假设存储结构为数组array[len],长度为len):在一趟冒泡排序中,从第一个记录开始,扫描整个待排序序列(注意是待排序序列,而不是整个记录序列,待排序序列随着排序的趟数的增加而减少,最后一趟待排序序列为2,只用交换两个元素),在一趟扫描中,最终必然将最大的元素排在待排序序列的末尾,这也是最大元素应该在的位置,第一躺时会将整个记录中最大元素排在最后一个位置array[len]。
然后进行第二趟,重复上述过程,结果将次大记录放在第array[len-1]上,......重复上述过程,直至整个数组余下一个记录为止。
若在某一趟的冒泡排序过程中,一个逆序也没找到,则可以直接结束整个排序过程,所以冒泡排序过程最多只进行len-1趟,冒泡排序也是唯一一个可以不用排序而直接终止排序的排序算法。
冒泡排序的代码如下:(采用C++模板类)
#include<iostream>
using namespace std;
template<typename T>
void bubble( T t[],int len)//注意模板中的参数T为参数类型,所以不能写成T[]
{
bool flag=true;
int i,j;
for(i=1;i<=len-1&&flag;i++)
{
flag=false;
for(j=0;j<len-i;j++)//如果外层循环是从1开始,那么内层循环j<len-i,
//不能取等号,否则会产生下标越界,因为下面的交换判断语句为t[j]
//与t[j+1],
{
if(t[j]>t[j+1])
{
swap(t[j],t[j+1]);
flag=true;
}
}
}
}
void main()
{
int a[]={4,2,1,3,5,7,6};
char x[100]={'x','y','s','a','n','c','m'};//此处必须指定数组的大小,虽然不指定也不会出错,但是当用字符去初始化一个没定义长度的字符数组时,系统不会默认在
//末尾添加'\0',所以此时不能用strlen函数来求该字符数组的长度,而当指定数组的大小后,余下的系统自动赋值为空,即'\0'
// int len=strlen(a);错误,strlen函数的参数为char*类型
int len=sizeof(a)/4;
for(int i=0;i<len;i++)
cout<<a[i]<<' ';
cout<<endl;
cout<<"排序后结果为"<<endl;
bubble(a,len);
for(int i=0;i<len;i++)
cout<<a[i]<<' ';
cout<<endl;
int str_len=strlen(x);
for(int i=0;i<len;i++)
cout<<x[i]<<' ';
cout<<endl;
cout<<"排序后结果为"<<endl;
bubble(x,str_len);
for(int i=0;i<len;i++)
cout<<x[i]<<' ';
cout<<endl;
}
复杂度分析:冒泡排序最好的情况就是当待排序序列正序排列的时候,则只需要进行一趟排序,在排序过程中进行n-1次比较,而不需要移动记录,即外层for循环只需执行一次,此时复杂度为O(n).最坏的情况就是逆序排列的时候,则第i趟需要进行n-i次比较,3(n-i)次移动,即外层for循环与内层for循环都得执行,总的比较次数为n(n-1)/2,而移动次数为3n(n-1)/2,此时复杂度为O(n*n).

1.2快速排序:快速排序作为和冒泡排序相同类型的排序(同为交换类排序),之所以能够被人们所熟知,是因为它解决了冒泡排序只用来对相邻两个元素进行比较,因此在互换两个相邻元素时只能消除一个逆序,而快速排序是通过两个不相邻元素的交换,来消除待排序记录中的多个逆序。即快速排序中的一趟交换可以消除多个逆序。
具体思想:从待排序记录中选取一个记录(通常选取第一个记录,当然也可采用随即划分的方式,这样能大大提高快速排序的执行效率,如我们所熟知的在O(n)的时间复杂度内找出前k元的算法),将其关键字记为K1,然后将其余关键字小于K1的记录移到前面,而大于关键字K1的移到后面,一趟快速排序之后,将待排序序列划分为两个子表,最后将关键字K1插到这两个子表的分界线的位置。具体实现就是用三层while循环,最外层的while循环控制该趟快速是否进行,而内层的两个while循环一个用来从左到右扫描大于该趟基准记录关键字的元素,一个用来从右到左扫描小于该趟基准记录的关键字的元素,可以用两个指针low和high指向当前从左到右和从右到左扫描的当前记录的关键字,找到一个就将其交换。
以上是一趟快速排序的思想,对上述划分后的子表重复上述过程,直至划分后的子表的长度不超过1为止。即为快速排序的思想,从定义可知快速排序是一个递归排序。
具体代码如下:
#include<iostream>
using namespace std;
const int len=7;
int qk(int a[],int low,int high)//注意快速排序函数的参数,因为每一趟快速排序的作用是要将数组分割为两个部分,前面一部分不大于K,后面一部分不小于K,然后在 //对前一部分和后一部分继续进行快速排序,所以,qk的第二个参数与第三个参数应为low与high
{
int x=a[low];//选取第一个元素作为基准记录
while(low<high)
{
while(low<high&&a[high]>=x)
high--;
if(low<high)
{
a[low]=a[high];
low++;
}
while(low<high&&a[low]<=x)
low++;
if(low<high)
{
a[high]=a[low];
high--;
}
}
a[low]=x;
return low;
}
void qsort(int a[],int low,int high)
{
if(low<high)
{
int pos=qk(a,low,high);
qsort(a,low,pos-1);
qsort(a,pos+1,high);
}
}
void main()
{
int a[len]={7,4,5,1,2,3,6};
cout<<"快速排序后的结果为:"<<endl;
qsort(a,0,len-1);
for(int i=0;i<len;i++)
{
cout<<a[i]<<' ';
}
cout<<endl;
}
复杂度分析:快速排序最好的情况就是每一趟排序将序列划分为两个部分,正好在表中间将表划分为两个大小相等的子表,类似于折半查找,此时复杂度为O(nlog2n).
最坏的情况就是已经排好序,则第一趟经过n-1次比较,第一个记录定在原位置,左部子表为空表,右部子表为n-1个记录,第二趟n-1个记录经过n-2次比较,第二个记录定在原位置.....即此时快速排序内层中的两个while循环不执行,此时快速排序退化为冒泡排序,总的比较次数为n*(n-1)/2,复杂度为O(n*n).
程序运行结果如下:
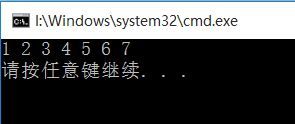
2.1简单选择排序:就是每趟扫描整个记录找到当前待排序序列中最小的(以升序为例),与第i(i=1,2,.....,n-1)个记录交换,很显然需要n-1趟,余下的最后一个元素直接在最后。
2.2堆排序:堆排序是利用堆这个数据结构(逻辑上用完全二叉树表示,物理上用数组表示),堆排序之所以被重视,主要是用在海量数据处理的TOP K问题中,如百度热词,从百度海量的用户搜索记录中查找被搜索次数最多的前K个关键词,这样我们只需要维护一个K元的堆即可,然后对海量数据分批加载到内存进行堆排序,最后所有数据都访问过后堆中的内容即为海量数据中TOP K元素。
关于堆排序的具体算法,请参看我的博客: 数据结构排序算法之堆排序
3其它类排序:
3.1归并排序:归并排序实际上就是将几个已排好序的子表合为一张新的有序表。
基于C++模板类的归并排序代码如下:
#include<iostream>
using namespace std;
template<typename T>
void merge(T t[],int low,int mid,int high)//mid参数表示t[low]-t[mid]和t[mid+1]-t[high]是按关键字排好序的
{
int i=low,j=mid+1;
int *temp=new int[high-low+1];
int k=0;
while(i<=mid&&j<=high)
{
if(t[i]<t[j])
{
temp[k]=t[i];
k++;
i++;
}
else
{
temp[k]=t[j];
k++;
j++;
}
}
while(i<=mid)
{
temp[k++]=t[i++];
}
while(j<=high)
{
temp[k++]=t[j++];
}
for(int i=low,j=0;i<high,j<k;i++)
{
t[i]=temp[j++];
}
}
template<typename T>
void mergeSort(T t[], int low, int high)
{
if(low < high-1)
{
int mid = (low+high)/2;
mergeSort(t,low,mid); //前半部分排序
mergeSort(t,mid+1,high); //后半部分排序
merge(t,low,mid,high);
}
}
void main()
{
int a[]={1,3,4,6,2,5,7};
mergeSort(a,0,6);
for(int i=0;i<7;i++)
{
cout<<a[i]<<' ';
}
cout<<endl;
}
程序运行结果如下:
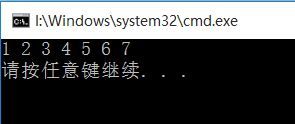
4插入类排序:
4.1希尔排序:即缩小增量排序,顾名思义就是将待排序序列划分为若干个“较稀疏的”子序列(通过多次调用希尔排序,直至最终增量为1为止,即缩小增量),它基于插入排序的思想,利用了直接插入排序的最佳性质(len较小),将这若干个子序列进行直接插入排序。
代码如下:
#include <iostream>
using namespace std;
const int len=7;
void ShellInsert(int a[],int len,int delta)
{
for(int i = delta; i<len; i++)
{
if(a[i] < a[i-delta])
{
int key = a[i];
int j;
for(j = i-delta;j>=0 && key < a[j]; j-=delta)
{
a[j+delta] = a[j];
}
a[j+delta] = key;
}
}
}
void ShellSort(int a[], int len, int delta[] , int n)
{
for(int i=0;i<n;i++)
{
ShellInsert(a,len,delta[i]);
}
}
int main()
{
int a[len]={7,4,5,1,2,3,6};
int delta[len] = {5,2,1};
ShellSort(a,len,delta,3);
for(int i=0; i<len; i++)
{
cout << a[i] << " ";
}
cout << endl;
}
程序运行结果如下:
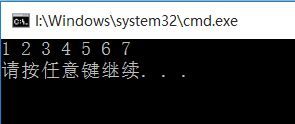
四.排序算法中的一些概念:
稳定性:排序算法的稳定性:若待排序的序列中,存在多个具有相同关键字的记录,经过排序, 这些记录的相对次序和排序之前相同,则称该算法是稳定的;若排序后,记录的相对次序和排序前不同,则该算法是不稳定的。
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
当待排序序列顺序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);
而快速排序则相反,当待排序序列基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n2);
待排序序列是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
以上就是本人理解的关于数据结构排序算法的相关内容,重点掌握冒泡排序,快速排序,堆排序以及它们各自的特点。