Hadoop Combiner组件
一:背景
在MapReduce模型中,reduce的功能大多是统计分类类型的总量、求最大值最小值等,对于这些操作可以考虑在Map输出后进行Combiner操作,这样可以减少网络传输负载,同时减轻reduce任务的负担。Combiner操作是运行在每个节点上的,只会影响本地Map的输出结果,Combiner的输入为本地map的输出结果,很多时候Combiner的逻辑和reduce的逻辑是相同的,因此两者可以共用reducer体。
二:什么时候运行Combiner
(1):当job设置了Combiner,并且spill的个数达到了min.num.spill.for.combine(默认是3)的时候,那么Combiner就会在merge之前执行。
(2):但是有的情况下,merge开始执行,但spill文件的个数没有达到需求,这个时候Combiner可能会在merge之后运行。
(3):Combiner也有可能不运行,Combiner会考虑当时集群的一个负载情况。
三:程序代码
public class WordCountTest {
// 定义输入路径
private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/hello";
// 定义输出路径
private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
public static void main(String[] args) {
try {
// 创建配置信息
Configuration conf = new Configuration();
/**********************************************/
//对Map端输出进行压缩
//conf.setBoolean("mapred.compress.map.output", true);
//设置map端输出使用的压缩类
//conf.setClass("mapred.map.output.compression.codec", GzipCodec.class, CompressionCodec.class);
//对reduce端输出进行压缩
//conf.setBoolean("mapred.output.compress", true);
//设置reduce端输出使用的压缩类
//conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);
// 添加配置文件(我们可以在编程的时候动态配置信息,而不需要手动去改变集群)
/*
* conf.addResource("classpath://hadoop/core-site.xml");
* conf.addResource("classpath://hadoop/hdfs-site.xml");
* conf.addResource("classpath://hadoop/hdfs-site.xml");
*/
// 创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
// 如果输出目录存在,我们就删除
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
}
// 创建任务
Job job = new Job(conf, WordCountTest.class.getName());
//1.1 设置输入目录和设置输入数据格式化的类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(TextInputFormat.class);
//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
// 1.4 排序、分组
//1.5 归约(Combiner可以和Reducer共用)
job.setCombinerClass(MyReducer.class);
//2.1 Shuffle把数据从Map端拷贝到Reduce端。
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
// 提交作业 退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
// 定义一个LongWritable对象作为map输出的value类型
LongWritable oneTime = new LongWritable(1);
// 定义一个Text对象作为map输出的key类型
Text word = new Text();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException,
InterruptedException {
// 对每一行记录采用制表符(\t)进行分割
String[] splits = value.toString().split("\t");
// 遍历字符串数组输出每一个单词
for (String str : splits) {
// 设置word
word.set(str);
// 把结果写出去
context.write(word, oneTime);
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
// 定义LongWritable对象最为Reduce输出的value类型
LongWritable result = new LongWritable();
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException,
InterruptedException {
int sum = 0;
// 遍历集合,计算每个单词出现的和
for (LongWritable s : values) {
sum += s.get();
}
// 设置result
result.set(sum);
// 把结果写出去
context.write(key, result);
}
}
}
程序使用的数据:
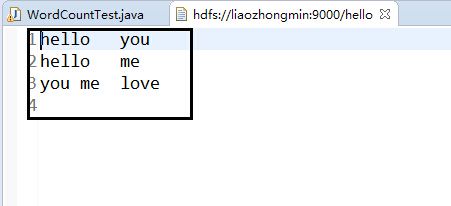
程序运行流程:
(1):Map的输入记录为3即<0,hello you> <10,hello me> <19,you me love>
(2):Map的输出记录为7即<hello,1> <you,1> <hello,1> <me,1> <you,1> <me,1> <love,1>
(3):排序分组后的记录为<hello,{1,1}> <love,{1}> <me,{1,1}> <you,{1}> 分了4组,但是记录数依然是7,只不过是分了组而已。
(4):进入Combiner的记录为7,经过Combiner之后的结果为<hello,2> <love,1> <me,2> <you,1>即Combiner的输出为4条记录
四:使用Combiner的限制
并不是所有情况都能使用Combiner,Combiner适用的场景是汇总求和、求最值的场景,但是对于求平均数的场景就不适用了。因为如果在求平均数的程序中使用了Combiner即在每个Map后都使用Combiner进行求平均,每个map计算出的平均值到了reduce端再进行平均,结果和正真的平均数就有出入了。