2-6HDFS读取数据的过程+下一篇类加载器(未完)
我们在centos下打开JPS,看到有几个进程,如果我们设置断点了的话,【设置短点跳出,右键选clone session不知道在哪】是在jps看到进程里面有RPCClient的。这说明,namenode,datanode这些都是一个类!
在eclipse里面打开Ctrl+shift+T 可以查找类
找到namenode之后,我们开始关联源码,
在这里,我们先去搜索下载一个hadoop的源码【Java的源码之前说过了,在jdk里面有】
搜索hadoop2.2.0 src 发现有两种格式 ,一个是tar.jz格式,一个是zip格式
这里复制以下二者的区别,其实Windows也可以打开tar.gz的
tar.gz与zip的区别
接下来,我们关联好hadoop的源码【也就是在未连接源码那里点连接,外部——文件夹,然后点上hadoop src那个文件夹就好】
之后在其中搜索namenode,Ctrl+shift+T 是能找到namenode的。包是org-阿帕奇-hadoop-
打开这个namenode.class,里面能找到main方法【1300+行左右】【这个不知道在哪个功能键】
先讲下载,下载比较简单
下载是在HDFSDemo里面写的,
我打开那个下载的代码,在
- public static void main(String[] args) throws Exception{
- FileSystem fs = FileSystem.get(new URI("hdfs://itcast01:9000"),new Configuration();
- InputStream in = fs.open(new Path("/test.jar"));
- OutputStream out = new FileOutputStream("c://test.jar111");
- IOUtils.copyBytes(in, out, 4096, true);
- }
第一次运行在第一行开头,再点继续,运行到第二行开头时,给出的变量fs的值是“分布式文件系统”

之后,由于我们下载了源码,也连接了源码,接下来,我们看一眼这些个源码:
【先打开Filesystem的声明,通过点击Filesystem向下拉到底部,然后Ctrl+T】
Ctrl+T 可以看到这个类的所属范围。比如,点FileSystem就可以看到超类型的结构,是谁谁的子类
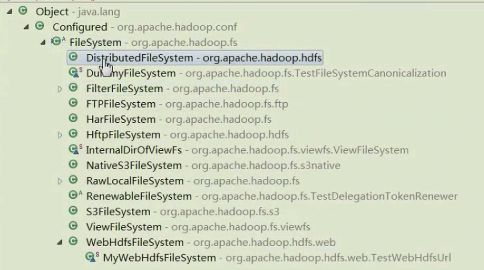
以后,DistributeFilesystem是Filesystem的子类,大部分功能都能满足,不满足的部分重写一下方法
好了,说回来,我们继续。现在打了两个断点,全部运行完成之后,在c盘出现了test.jar111这个文件
之后,再一次main右键,调试方式——然后进入调试,在上面有
单步跳入F5 单步跳过F6 单步返回F7
我此时的断点在第一行
- FileSystem fs = FileSystem.get(new URI("hdfs://itcast01:9000"),new Configuration());
这里,此时我如果想进入这个方法,摁F5或者上面的单步跳入键都可以,此时,它首先load URI这个类,然后进入URI的new构造方法,然后这个new完之后,要把configuration也load到里面,然后再进入到get方法里。
【在实际操作中,我并没有进入get方法里面,
如果想直接走过,摁F6
如果想从这个方法跳出去 F7
【程序员一定要会debug,打断点很重要!!!明天讲远程debug,可以让我能看到server的运行状况】
以后,namenode那个类是不可控的,如果我也想打断点,用远程debug。
????
【不懂的名词:懒汉/饿汉 多线程 】
【运行调试有两个短点的,然后按F5,可以进入classloader;不停的按F5,进入别的方法对象里】

hadoop也有自己默认的配置文件
在hadoop0106——引用的库——hadoop-common-2.2.0.jar下core-default.xml
core-default.xml是hadoop默认的配置文件。

双击打开,可以看到,

这个版本是从0.23.0版本发展过来的。别的信息也可以看到,不过在这里没有讲。
同理,在hadoop0106——引用的库——hadoop-hdfs-2.2.0.jar下可以找到hdfs-default.xml文件
在这个文件中,可以查找【暂时还不知道哪个快捷键是查找】blocksize,可以看到默认的块的大小是134217728,即128M,搜索replication,可以看到默认的dfs.replication是复制3份。【里面有默认配置,而且默认配置非常多】
-default一般是默认的配置,-site是可以让用户再自定义的
大体来说。。。源码是根据它的一些配置信息得到一些具体的实现类,实现类叫distributed FileSystem。
首先,我们先用FileSystem工具类,.get,进入get只完成一件事:根据你的文件类型找到你的实现类,实现类叫distributed FileSystem
我们看源码只看一些重要的步骤。。源码有20W+行....变量的赋值不需要看,我只看方法(这个方法有没有返回值,有返回值的话,类型是什么,如果返回一个list,要看在哪儿new这个list的,把什么东西放在这个list里了)
【此处没听懂。。通过反射得到它的class类型,然后可以new它的instance
??
1、最开始我通过读取信息得到一个工具类FileSystem,
2、我通过工具类FileSystem的get方法(读取配置信息,通过反射)来得到一个distributedFileSystem对象【这个对象中很多都没有初始化】
3、构建出来之后,调用initialize()方法来初始化【在initialize里面主要new构建了DFSClient,并将DFSClient作为它的成员变量。DFSClient里面通过HADOOP的RPC机制得到了一个服务端的代理对象$Proxy】
这个代理对象它不满意,又使用JDK动态代理又进行了一次代理。
面试:一个对象初始化的过程——请问第一行是一个private static int a=1,第二行是一个静态代码块,第三个是private int i=new innager,然后是构造方法里面的,请问他,,是什么数据
类加载器,类加载器加载的时候前面是static int a=1,然后是静态代码块
下面我转发一片关于类加载器的文章【没看懂】
现在,我可以通过FileSystem得到distributedFileSystem,distributedFileSystem又可以得到DFSClient,DFSClient又可以得到服务端的代理对象,我得到这个代理对象之后,我要抓取块的信息。
看到40:38,以后再看,看不懂