Leveldb源码分析--8
6 SSTable之2
6.4 创建sstable文件
了解了sstable文件的存储格式,以及Data Block的组织,下面就可以分析如何创建sstable文件了。相关代码在table_builder.h/.cc以及block_builder.h/.cc(构建Block)中。
6.4.1 TableBuilder类
构建sstable文件的类是TableBuilder,该类提供了几个有限的方法可以用来添加k/v对,Flush到文件中等等,它依赖于BlockBuilder来构建Block。
TableBuilder的几个接口说明下:
> void Add(const Slice& key, const Slice& value),向当前正在构建的表添加新的{key, value}对,要求根据Option指定的Comparator,key必须位于所有前面添加的key之后;
> void Flush(),将当前缓存的k/v全部flush到文件中,一个高级方法,大部分的client不需要直接调用该方法;
> void Finish(),结束表的构建,该方法被调用后,将不再会使用传入的WritableFile;
> void Abandon(),结束表的构建,并丢弃当前缓存的内容,该方法被调用后,将不再会使用传入的WritableFile;【只是设置closed为true,无其他操作】
一旦Finish()/Abandon()方法被调用,将不能再次执行Flush或者Add操作。
下面来看看涉及到的类,如图6.3-1所示。
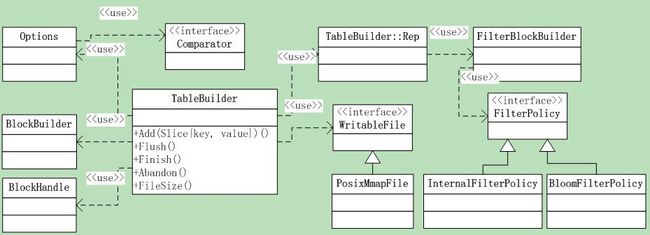
图6.3-1
其中WritableFile和op log一样,使用的都是内存映射文件。Options是一些调用者可设置的选项。
TableBuilder只有一个成员变量Rep* rep_,实际上Rep结构体的成员就是TableBuilder所有的成员变量;这样做的目的,可能是为了隐藏其内部细节。Rep的定义也是在.cc文件中,对外是透明的。
简单解释下成员的含义:
Options options; // data block的选项 Options index_block_options; // index block的选项 WritableFile* file; // sstable文件 uint64_t offset; // 要写入data block在sstable文件中的偏移,初始0 Status status; //当前状态-初始ok BlockBuilder data_block; //当前操作的data block BlockBuilder index_block; // sstable的index block std::string last_key; //当前data block最后的k/v对的key int64_t num_entries; //当前data block的个数,初始0 bool closed; //调用了Finish() or Abandon(),初始false FilterBlockBuilder*filter_block; //根据filter数据快速定位key是否在block中 bool pending_index_entry; //见下面的Add函数,初始false BlockHandle pending_handle; //添加到index block的data block的信息 std::string compressed_output;//压缩后的data block,临时存储,写入后即被清空
Filter block是存储的过滤器信息,它会存储{key, 对应data block在sstable的偏移值},不一定是完全精确的,以快速定位给定key是否在data block中。
下面分析如何向sstable中添加k/v对,创建并持久化sstable。其它函数都比较简单,略过。另外对于Abandon,简单设置closed=true即返回。
6.4.2 添加k/v对
这是通过方法Add(constSlice& key, const Slice& value)完成的,没有返回值。下面分析下函数的逻辑:
S1 首先保证文件没有close,也就是没有调用过Finish/Abandon,以及保证当前status是ok的;如果当前有缓存的kv对,保证新加入的key是最大的。
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key))> 0);
}
S2 如果标记r->pending_index_entry为true,表明遇到下一个data block的第一个k/v,根据key调整r->last_key,这是通过Comparator的FindShortestSeparator完成的。
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key,key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry =false;
}
接下来将pending_handle加入到index block中{r->last_key, r->pending_handle’sstring}。最后将r->pending_index_entry设置为false。
值得讲讲pending_index_entry这个标记的意义,见代码注释:
直到遇到下一个databock的第一个key时,我们才为上一个datablock生成index entry,这样的好处是:可以为index使用较短的key;比如上一个data block最后一个k/v的key是"the quick brown fox",其后继data block的第一个key是"the who",我们就可以用一个较短的字符串"the r"作为上一个data block的index block entry的key。
简而言之,就是在开始下一个datablock时,Leveldb才将上一个data block加入到index block中。标记pending_index_entry就是干这个用的,对应data block的index entry信息就保存在(BlockHandle)pending_handle。
S3 如果filter_block不为空,就把key加入到filter_block中。
if (r->filter_block != NULL) {
r->filter_block->AddKey(key);
}
S4 设置r->last_key = key,将(key, value)添加到r->data_block中,并更新entry数。
r->last_key.assign(key.data(), key.size()); r->num_entries++; r->data_block.Add(key,value);
S5 如果data block的个数超过限制,就立刻Flush到文件中。
const size_testimated_block_size = r->data_block.CurrentSizeEstimate(); if (estimated_block_size >=r->options.block_size) Flush();
6.4.3 Flush文件
该函数逻辑比较简单,直接见代码如下:
Rep* r = rep_;
assert(!r->closed); // 首先保证未关闭,且状态ok
if (!ok()) return;
if (r->data_block.empty())return; // data block是空的
// 保证pending_index_entry为false,即data block的Add已经完成
assert(!r->pending_index_entry);
// 写入data block,并设置其index entry信息—BlockHandle对象
WriteBlock(&r->data_block, &r->pending_handle);
//写入成功,则Flush文件,并设置r->pending_index_entry为true,
//以根据下一个data block的first key调整index entry的key—即r->last_key
if (ok()) {
r->pending_index_entry =true;
r->status =r->file->Flush();
}
if (r->filter_block != NULL){ //将data block在sstable中的便宜加入到filter block中
r->filter_block->StartBlock(r->offset); // 并指明开始新的data block
}
6.4.4 WriteBlock函数
在Flush文件时,会调用WriteBlock函数将data block写入到文件中,该函数同时还设置data block的index entry信息。原型为:
void WriteBlock(BlockBuilder* block, BlockHandle* handle)
该函数做些预处理工作,序列化要写入的data block,根据需要压缩数据,真正的写入逻辑是在WriteRawBlock函数中。下面分析该函数的处理逻辑。
S1 获得block的序列化数据Slice,根据配置参数决定是否压缩,以及根据压缩格式压缩数据内容。对于Snappy压缩,如果压缩率太低<12.5%,还是作为未压缩内容存储。
BlockBuilder的Finish()函数将data block的数据序列化成一个Slice。
Rep* r = rep_;
Slice raw = block->Finish(); // 获得data block的序列化字符串
Slice block_contents;
CompressionType type =r->options.compression;
switch (type) {
case kNoCompression: block_contents= raw; break; // 不压缩
case kSnappyCompression: { // snappy压缩格式
std::string* compressed =&r->compressed_output;
if(port::Snappy_Compress(raw.data(), raw.size(), compressed) &&
compressed->size()< raw.size() - (raw.size() / 8u)) {
block_contents =*compressed;
} else { // 如果不支持Snappy,或者压缩率低于12.5%,依然当作不压缩存储
block_contents = raw;
type = kNoCompression;
}
break;
}
}
S2 将data内容写入到文件,并重置block成初始化状态,清空compressedoutput。
WriteRawBlock(block_contents,type, handle); r->compressed_output.clear(); block->Reset();
6.4.5 WriteRawBlock函数
在WriteBlock把准备工作都做好后,就可以写入到sstable文件中了。来看函数原型:
void WriteRawBlock(const Slice& data, CompressionType, BlockHandle*handle);
函数逻辑很简单,见代码。
Rep* r = rep_;
handle->set_offset(r->offset); // 为index设置data block的handle信息
handle->set_size(block_contents.size());
r->status =r->file->Append(block_contents); // 写入data block内容
if (r->status.ok()) {// 写入1byte的type和4bytes的crc32
chartrailer[kBlockTrailerSize];
trailer[0] = type;
uint32_t crc = crc32c::Value(block_contents.data(),block_contents.size());
crc = crc32c::Extend(crc, trailer, 1); // Extend crc tocover block type
EncodeFixed32(trailer+1, crc32c::Mask(crc));
r->status =r->file->Append(Slice(trailer, kBlockTrailerSize));
if (r->status.ok()) { // 写入成功更新offset-下一个data block的写入偏移
r->offset +=block_contents.size() + kBlockTrailerSize;
}
}
6.4.6 Finish函数
调用Finish函数,表明调用者将所有已经添加的k/v对持久化到sstable,并关闭sstable文件。
该函数逻辑很清晰,可分为5部分。
S1 首先调用Flush,写入最后的一块data block,然后设置关闭标志closed=true。表明该sstable已经关闭,不能再添加k/v对。
Rep* r = rep_; Flush(); assert(!r->closed); r->closed = true;
BlockHandle filter_block_handle,metaindex_block_handle, index_block_handle;
S2 写入filter block到文件中
if (ok() &&r->filter_block != NULL) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,&filter_block_handle);
}
S3 写入meta index block到文件中
如果filterblock不为NULL,则加入从"filter.Name"到filter data位置的映射。通过meta index block,可以根据filter名字快速定位到filter的数据区。
if (ok()) {
BlockBuildermeta_index_block(&r->options);
if (r->filter_block !=NULL) {
//加入从"filter.Name"到filter data位置的映射
std::string key ="filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key,handle_encoding);
}
// TODO(postrelease): Add stats and other metablocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
S4 写入index block,如果成功Flush过data block,那么需要为最后一块data block设置index block,并加入到index block中。
if (ok()) {
if (r->pending_index_entry){ // Flush时会被设置为true
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding)); // 加入到index block中
r->pending_index_entry =false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
S5 写入Footer。
if (ok()) {
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status =r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset +=footer_encoding.size();
}
}
整个写入流程就分析完了,对于Datablock和Filter Block的操作将在Data block和Filter Block中单独分析,下面的读取相同。