快速排序 (Quick Sort)
简介:
快速排序(Quick Sort)是C.A.R.Hoare在1962年提出的,是一种有效的排序算法,使用分治法(Divide and Conquer)策略,把一个数列(list)划分为两个子数列(sublists).
步骤:
(1)从数列中挑出一个元素,作为”基准”(pivot).
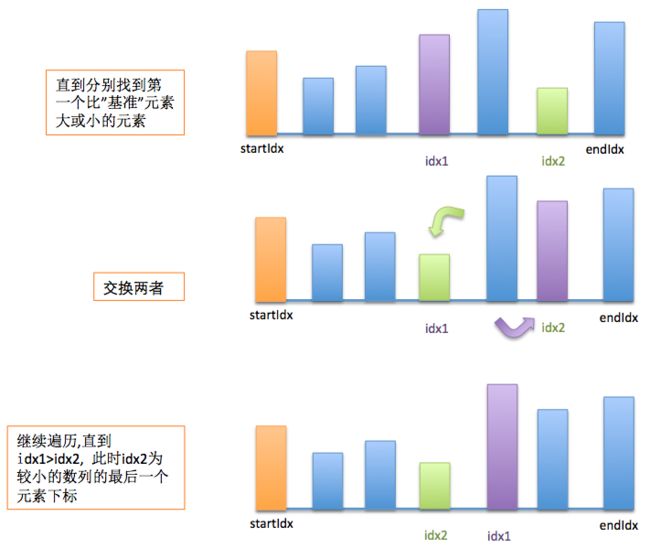
(2)遍历数列,把所有比基准值小的元素往前放,把所有比基准值大的元素往后放,遍历完一趟之后把基准值放在分开的两子数列之间.这个步骤成为”分区”(partition)操作.
(3)对划分开的两数列分别重复步骤(1).(2).
“基准”元素的选择:
可直接选择两端或中间的某个元素作为”基准”元素,但这样运行效率会因为元素的排列顺序不同而有很大变化,所以为了减小元素位置的影响,用随机抽取的方法比较好.
实现:
排序过程可用递归来实现.但要消耗递归栈的空间,而大多数情况下会使用系统递归栈来完成递归求解.在元素较大的情况下,对系统栈的频繁存取会影响到排序的效率.一个常用的方法是设定一个阀值(如取10),在每次递归求解中,如果元素总数比这个阀值小,则采用其他的简单排序方法(如选择排序,插入排序等)来代替快速排序,这样可以减少对系统递归栈的调用.但注意阀值不要太大,否则耗在简单排序方法上的时间比省下的存取系统栈的时间还多.
时间复杂度:
在平均情况下,时间复杂度为 O(nlogn);在最坏情况下则是 O(n2).
图解过程:


C语言版代码如下:
#include <stdio.h>
#include <stdlib.h>
// 交换两变量的值
void swap (int *x, int *y){
int temp = *x;
*x = *y;
*y = temp;
}
// 在 minIdx ~ maxIdx 间,随机返回一个数,作为"基准"的下标
int choose_pivot(int minIdx, int maxIdx){
return minIdx + rand() % (maxIdx - minIdx + 1);
}
// 对数列array中下标为 startIdx ~ endIdx 的元素进行快速排序
void quickSort(int array[], int startIdx, int endIdx){
int pivotValue, pivotIdx, idx1, idx2;
if (startIdx < endIdx) {
// 随机获取"基准"元素的下标
pivotIdx = choose_pivot(startIdx, endIdx);
// 记录"基准"元素的值
pivotValue = array[pivotIdx];
// 把"基准"元素放到首位
swap(&array[startIdx], &array[pivotIdx]);
// 遍历数列中其他元素,把比"基准"值小的往前放,较大的往后放
idx1 = startIdx + 1;
idx2 = endIdx;
while (idx1 <= idx2) {
// 从前往后,找到第一个比"基准"值大的元素
while (idx1 <= endIdx && array[idx1] <= pivotValue) {
idx1++;
}
// 从后往前,找到第一个比"基准"值小的元素
while (idx2 >= startIdx && array[idx2] > pivotValue) {
idx2--;
}
// 比较两元素,把较大的往后放
if (idx1 < idx2) {
swap(&array[idx1], &array[idx2]);
}
}
// 经过上面的循环,除了"基准"元素外的其他元素已经分为两个字数列,前一个数列的元素都比"基准"元素小,后一个则都较大.
// 此时idx2为前一个数列最后一个元素的下标,则交换两者,使得原数列被划分为以"基准"元素为界的两个子数列.
swap(&array[startIdx], &array[idx2]);
// 用递归的方法,分别对前后两个子数列同上面的方法进行排序,直到每个子数列被划分成只包含一个元素
quickSort(array, startIdx, idx2 - 1);
quickSort(array, idx2 + 1, endIdx);
}
}
int main(int argc, const char * argv[]) {
int array[10] = {4,2,7,3,9,10,5,8,6,1};
quickSort(array, 0, 9);
return 0;
}