CUDA编程(十)使用Kahan's Summation Formula提高精度
CUDA编程(十)
使用Kahan’s Summation Formula提高精度
上一次我们准备去并行一个矩阵乘法,然后我们在GPU上完成了这个程序,当然是非常单纯的把任务分配给各个线程,也没有经过优化。最终我们看到,执行效率相当的低下,但是更重要的是出现了一个我们之前做整数立方和没遇到的问题,那就是浮点数精度损失的问题。
关注GPU运算的精度问题:
在程序的最后,我们计算了精度误差,发现最大相对误差偏高,而一般理想上应该要低于 1e-6。
我们之前将评估CUDA程序的时候也提过了,精度是CUDA程序需要重点评估的一个点,那么我们该如何解决这个问题呢?我们先分析一下原因。
出现精度问题的原因:
其实计算结果的误差偏高的原因很简单,在 CPU 上进行计算时,我们使用 double(即 64 bits 浮点数)来累进计算过程,而在 GPU 上则只能用 float(32 bits 浮点数)。在累加大量数字的时候,由于累加结果很快会变大,因此后面的数字很容易被舍去过多的位数。
这里可能说的不是很清楚,看完下面这个例子就清楚了。
浮点数的大数吃小数问题:
浮点数的精度:
大家应该很清楚,浮点数在内存中是按科学计数法来存储的,分为符号位,指数位,和尾数位。
float和double各段的位数分别是:
float:
1bit(符号位) 8bits(指数位) 23bits(尾数位)
double:
1bit(符号位) 11bits(指数位) 52bits(尾数位)
float和double的精度是由尾数的位数来决定的:
float: 2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字。
double: 2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
大数吃小数:
float因为位数相较于double要短不少,所以很容易出现大数吃小数的问题:
比如我们用两个float相加:
#include <stdio.h>
int main()
{
float a = 100998;
float b = 2.338;
a = a + b;
printf("the sum is %f", a);
}a+b 应该等于 101000.338,前面说了float的精度有6~7位,所以38可能会被截掉,3不一定,但是8必然会被截掉,我们可以实际输出一下看看:
结果是:the sum is 101000.335938
因为%f是输出double类型,可以看到转换后8这位已经没了,33是正常的。
从这里可以看到一个加法过程就没了0.008,要是加1000次,一个整8就没了。
这就是大数吃小数问题。
Kahan’s Summation Formula:
现在我们就要想办法解决这个问题了,我们看到标题中这个看起来很高大上的名字,这个也叫作kahan求和算法,我们接下来就要用kahan求和来避免这种精度损失的情况。
名字很高大上,但是原理很小儿科,小学生也知道,缺的我们想办法再补回来:
所以我们用一个temp变量来记住损失掉的部分,等下次加法的时候再加回去就好了。
temp= (a+b)-a-b; 在上面那个问题中 temp = -0.008,在下次计算的时候加和到下一个加数就可以一定程度的减小误差。
Kahan’s Summation Formula伪代码:
function KahanSum(input)
var sum = 0.0
var c = 0.0 //A running compensation for lost low-order bits.
for i = 1 to input.length do
y = input[i] - c //So far, so good: c is zero.
t = sum + y //Alas, sum is big, y small, so low-order digits of y are lost.
c = (t - sum) - y //(t - sum) recovers the high-order part of y; subtracting y recovers -(low part of y)
sum = t //Algebraically, c should always be zero. Beware eagerly optimising compilers!
//Next time around, the lost low part will be added to y in a fresh attempt.
return sum提高矩阵乘法的精度:
看着伪代码比着葫芦画瓢还是比较简单的,我们只需要更改核函数中的加和部分即可:
原版
//计算矩阵乘法
if (row < n && column < n)
{
float t = 0;
for (i = 0; i < n; i++)
{
t += a[row * n + i] * b[i * n + column];
}
c[row * n + column] = t;
}改版
//计算矩阵乘法
if (row < n && column < n)
{
float t = 0;
float y = 0;
for (i = 0; i < n; i++)
{
float r;
y -= a[row * n + i] * b[i * n + column];
r = t - y;
y = (r - t) + y;
t = r;
}
c[row * n + column] = t;
}
完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//CUDA RunTime API
#include <cuda_runtime.h>
#define THREAD_NUM 256
#define MATRIX_SIZE 1000
const int blocks_num = MATRIX_SIZE*(MATRIX_SIZE + THREAD_NUM - 1) / THREAD_NUM;
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
//CUDA 初始化
bool InitCUDA()
{
int count;
//取得支持Cuda的装置的数目
cudaGetDeviceCount(&count);
if (count == 0)
{
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++)
{
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
//打印设备信息
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess)
{
if (prop.major >= 1)
{
break;
}
}
}
if (i == count)
{
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
//生成随机矩阵
void matgen(float* a, int n)
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
a[i * n + j] = (float)rand() / RAND_MAX + (float)rand() / (RAND_MAX * RAND_MAX);
}
}
}
// __global__ 函数 并行计算矩阵乘法
__global__ static void matMultCUDA(const float* a, const float* b, float* c, int n, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//表示目前的 thread 属于第几个 block(由 0 开始计算)
const int bid = blockIdx.x;
//从 bid 和 tid 计算出这个 thread 应该计算的 row 和 column
const int idx = bid * THREAD_NUM + tid;
const int row = idx / n;
const int column = idx % n;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid] = clock();
//计算矩阵乘法
if (row < n && column < n)
{
float t = 0;
//temp变量
float y = 0;
for (i = 0; i < n; i++)
{
float r;
y -= a[row * n + i] * b[i * n + column];
r = t - y;
y = (r - t) + y;
t = r;
}
c[row * n + column] = t;
}
//计算时间,记录结果,只在 thread 0(即 threadIdx.x = 0 的时候)进行,每个 block 都会记录开始时间及结束时间
if (tid == 0)
{
time[bid + blocks_num] = clock();
}
}
int main()
{
//CUDA 初始化
if (!InitCUDA()) return 0;
//定义矩阵
float *a, *b, *c, *d;
int n = MATRIX_SIZE;
//分配内存
a = (float*)malloc(sizeof(float)* n * n);
b = (float*)malloc(sizeof(float)* n * n);
c = (float*)malloc(sizeof(float)* n * n);
d = (float*)malloc(sizeof(float)* n * n);
//设置随机数种子
srand(0);
//随机生成矩阵
matgen(a, n);
matgen(b, n);
/*把数据复制到显卡内存中*/
float *cuda_a, *cuda_b, *cuda_c;
clock_t* time;
//cudaMalloc 取得一块显卡内存
cudaMalloc((void**)&cuda_a, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_b, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_c, sizeof(float)* n * n);
cudaMalloc((void**)&time, sizeof(clock_t)* blocks_num * 2);
//cudaMemcpy 将产生的矩阵复制到显卡内存中
//cudaMemcpyHostToDevice - 从内存复制到显卡内存
//cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(cuda_a, a, sizeof(float)* n * n, cudaMemcpyHostToDevice);
cudaMemcpy(cuda_b, b, sizeof(float)* n * n, cudaMemcpyHostToDevice);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);
matMultCUDA << < blocks_num, THREAD_NUM, 0 >> >(cuda_a, cuda_b, cuda_c, n, time);
/*把结果从显示芯片复制回主内存*/
clock_t time_use[blocks_num * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(c, cuda_c, sizeof(float)* n * n, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* blocks_num * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(cuda_a);
cudaFree(cuda_b);
cudaFree(cuda_c);
cudaFree(time);
//把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[blocks_num];
for (int i = 1; i < blocks_num; i++)
{
if (min_start > time_use[i]) min_start = time_use[i];
if (max_end < time_use[i + blocks_num]) max_end = time_use[i + blocks_num];
}
//核函数运行时间
clock_t final_time = max_end - min_start;
//CPU矩阵乘法,存入矩阵d
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
double t = 0;
for (int k = 0; k < n; k++)
{
t += a[i * n + k] * b[k * n + j];
}
d[i * n + j] = t;
}
}
//验证正确性与精确性
float max_err = 0;
float average_err = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (d[i * n + j] != 0)
{
//fabs求浮点数x的绝对值
float err = fabs((c[i * n + j] - d[i * n + j]) / d[i * n + j]);
if (max_err < err) max_err = err;
average_err += err;
}
}
}
printf("Max error: %g Average error: %g\n", max_err, average_err / (n * n));
printf("gputime: %d\n", final_time);
return 0;
}
运行结果:
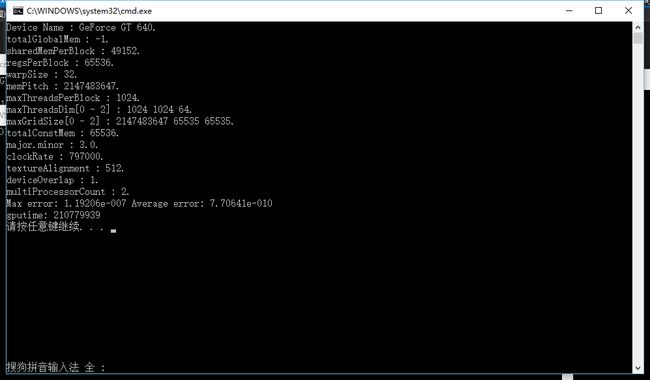
我们看到结果还是效果还是非常不错的,我们上次的结果是:
Max error:2.07589e-006
Average error :3.3492e-007
gpu time:189967999
而目前的结果是:
Max error:1.19206e-007
Average error :7.70641e-010
gpu time:210779939
我们可以看到精确度确实有了很大的提升,当然效率还是一如既往地慢,不过我们至少把精度问题给解决了。
总结:
之前我们用CUDA完成了矩阵乘法,但是当然会存在很多问题,除了速度问题,GPU浮点数运算的精度也很差,本篇博客从出现误差的原理(浮点数大数吃小数)分析,使用了Kahan’s Summation Formula在一定程度上解决了CUDA运算float精度不够的情况,接下来我们会着手去解决速度问题~
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》