Spark集群运行模式
Spark集群运行模式
spark集群四种运行模式
Local(只需要一台机器)
Standalone(不需要Hadoop集群也可以跑Spark,Spark自带的集群模式)
Yarn
Mesos
1、解压压缩文件到指定目录
[root@node1 software]# tar -zxf spark-1.3.1-bin-hadoop2.4.tgz -C /opt/modules
![]()
[root@node1 modules]# mv spark-1.3.1-bin-hadoop2.4 spark-1.3.1
2、配置salve(Spark从节点)
[root@node1 conf]# mv slaves.template slaves
[root@node1 conf]# vi slaves
![]()
node2
node3
node5
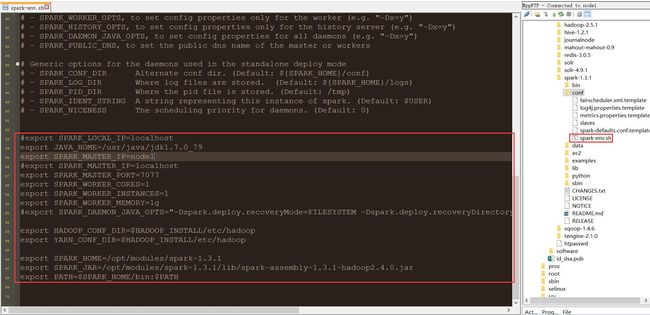
3、配置/opt/modules/spark-1.3.1/conf目录下的spark-env.sh文件
#export SPARK_LOCAL_IP=localhost
export JAVA_HOME=/usr/java/jdk1.7.0_79
export SPARK_MASTER_IP=node1
#export SPARK_MASTER_IP=localhost
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
#export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/nfs/spark/recovery"
export HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.1/etc/hadoop
export YARN_CONF_DIR=/opt/modules/hadoop-2.5.1/etc/hadoop
export SPARK_HOME=/opt/modules/spark-1.3.1
export SPARK_JAR=/opt/modules/spark-1.3.1/lib/spark-assembly-1.3.1-hadoop2.4.0.jar
export PATH=$SPARK_HOME/bin:$PATH
Local单机模式
结果xshell可见:
[root@node1 spark-1.3.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[1] ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
StandAlone模式
1> 将在node1配置好的spark配置文件发送给node2、node3、node5节点
[root@node1 spark-1.3.1]# scp -r /opt/modules/spark-1.3.1 root@node2:/opt/modules/spark-1.3.1
[root@node1 spark-1.3.1]# scp -r /opt/modules/spark-1.3.1 root@node3:/opt/modules/spark-1.3.1
[root@node1 spark-1.3.1]# scp -r /opt/modules/spark-1.3.1 root@node5:/opt/modules/spark-1.3.1

想要运行,要先启动Spark集群
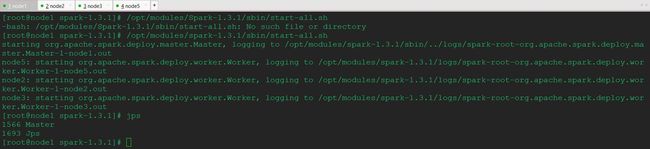
2> 启动spark集群
[root@node1 spark-1.3.1]# /opt/modules/spark-1.3.1/sbin/start-all.sh
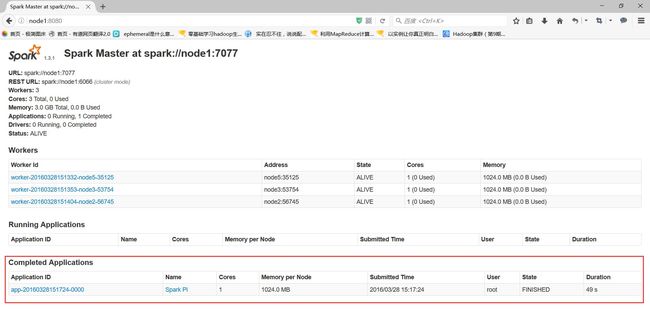
Spark Web UI监控
3> 在浏览器地址栏访问:http://node1:8080/
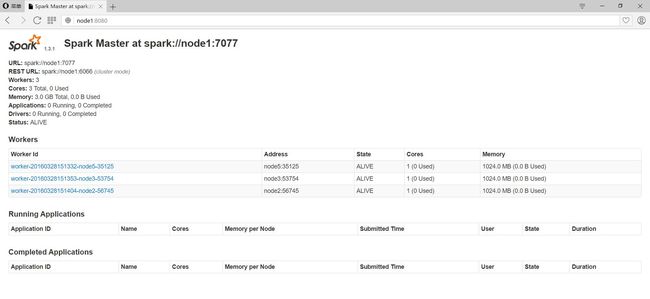
node1:7077(内部通信端口)
Standalone集群模式之client模式
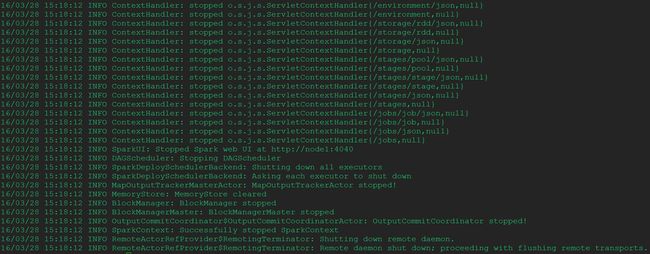
结果xshell可见:
[root@node1 spark-1.3.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
Standalone集群模式之cluster模式
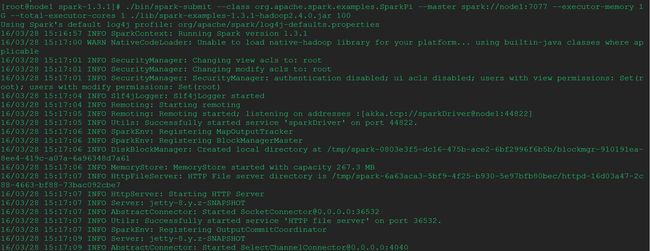
1> 运行测试
[root@node1 spark-1.3.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --deploy-mode cluster --supervise --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100

Spark Web UI监控
2> 在浏览器地址栏访问:http://node1:8080/
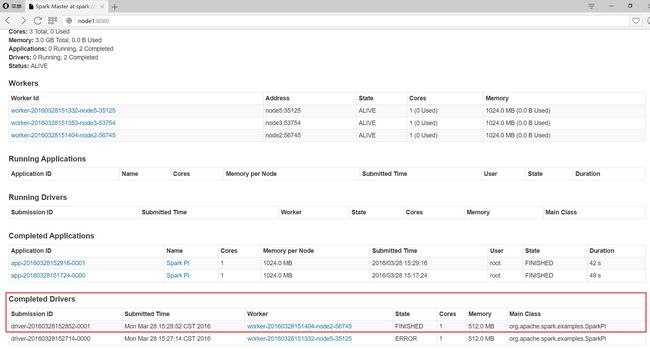

YARN运行模式
1> 停止Spark集群
[root@node1 spark-1.3.1]# /opt/modules/spark-1.3.1/sbin/stop-all.sh

2> 启动Zookeeper、Hadoop集群
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
[root@node1 ~]# start-all.sh
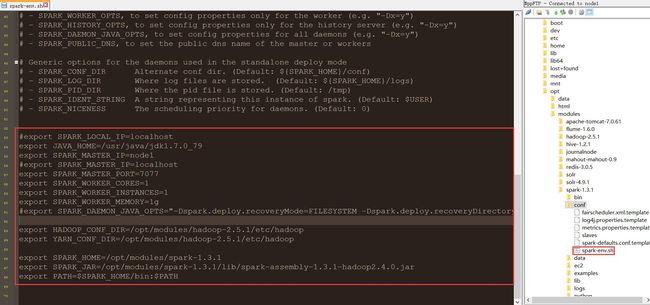
3> 配置/opt/modules/spark-1.3.1/conf目录下的spark-env.sh文件
#export SPARK_LOCAL_IP=localhost
export JAVA_HOME=/usr/java/jdk1.7.0_79
export SPARK_MASTER_IP=node1
#export SPARK_MASTER_IP=localhost
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
#export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/nfs/spark/recovery"
export HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.1/etc/hadoop
export YARN_CONF_DIR=/opt/modules/hadoop-2.5.1/etc/hadoop
export SPARK_HOME=/opt/modules/spark-1.3.1
export SPARK_JAR=/opt/modules/spark-1.3.1/lib/spark-assembly-1.3.1-hadoop2.4.0.jar
export PATH=$SPARK_HOME/bin:$PATH
4> 执行命令
YARN集群模式之client模式
client模式下:可以在xshell中查看到输出结果
[root@node1 spark-1.3.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 1G --num-executors 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
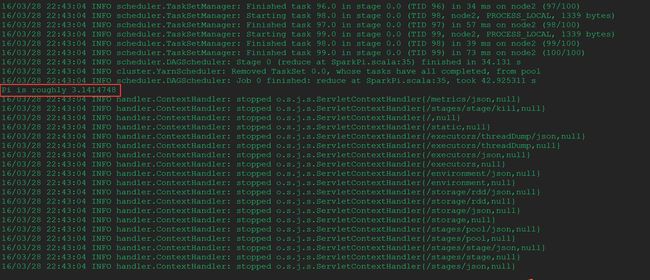
在浏览器地址栏输入:http://node1:8088/cluster查看
YARN集群模式之cluster模式
可以在Spark Web UI中查看到结果
[root@node1 spark-1.3.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 1G --num-executors 1 ./lib/spark-examples-1.3.1-hadoop2.4.0.jar 100
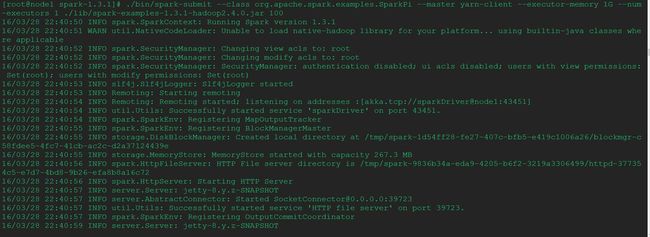
在浏览器地址栏输入:http://node1:8088/cluster查看